From Hype to Syllabus: Quantum Chaos Education After Google’s “Echoes” Claim
Quantum Echoes delivered a verified 13,000× speedup, elevating quantum chaos education Curricula should pivot from qubit counts to competence in echoes, OTOCs, and noise Fund teacher PD, simple cloud labs, and artifact-based assessment

APEC Economic Cooperation Delivers Even Without a U.S.-China Truce
APEC economic cooperation keeps delivering even without a U.S.–China truce Mid-sized members drive results through trade facilitation, mobility, and digital trust Train skills; scale ABTC and CBPR.

Debt Stigma and the Speed of Money: A Policy Lever Hiding in Plain Sight
Debt stigma slows borrowing and drags on money velocity Purpose-framed, safeguarded credit boosts productive investment in education and firms Use macroprudential guardrails to lift growth without fueling bubbles

Debt stigma isn't j
Building the Third AI Stack: An Airbus-Style Playbook for Public AI Cooperation
Building the Third AI Stack: An Airbus-Style Playbook for Public AI Cooperation

In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
Build a third AI stack for education Adopt an Airbus-style consortium for procurement Prioritize teacher time-savings, multilingual access, and audited safety

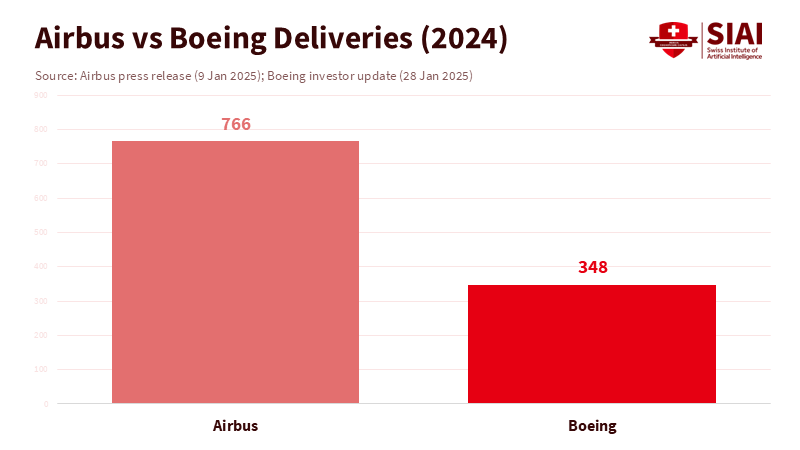
A single number highlights the stakes: in 2024, Airbus delivered 766 jetliners, which is more than twice Boeing's 348. This marks a significant advantage for a European consortium over an American company that once seemed unbeatable. The lesson isn't about airplanes; it's about how countries can combine resources, industrial policies, and standards to shape a critical market. Education is at a similar turning point. If we want safe, affordable, multilingual AI for classrooms, research, and public services, we need the third AI stack. This stack would be a collaborative layer of compute, data, and safety infrastructure that works alongside corporate platforms and open-source communities. Europe is starting this stack with €7 billion for shared supercomputing, while the United States is launching NAIRR to provide compute and datasets to researchers. Together, these initiatives outline a path similar to Airbus's AI approach. The opportunity is limited. Compute and model scales are rapidly increasing. Without coordinated efforts, the gap between what schools need and what private stacks offer will grow.
Why the third AI stack matters now
The third AI stack is not just a future possibility, but a pressing need in the present. Its importance is underscored by the current market dynamics and the increasing concentration of advanced AI in the hands of a few.
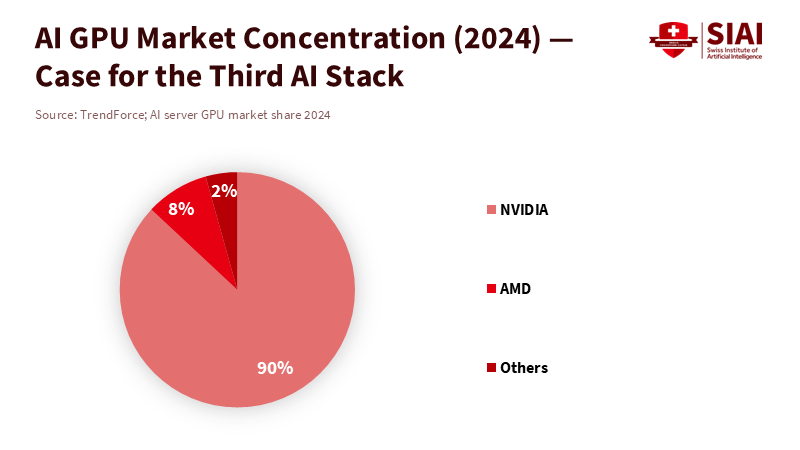
The market for advanced AI is concentrating where it counts most: accelerator hardware and the software that keeps users dependent on it. Analysts estimate that training costs for cutting-edge systems have increased by four to five times annually since 2010. The latest compute-intensive runs have exceeded 10^26 floating-point operations. TrendForce reports that, across all types of AI server accelerators, one vendor holds a significant market share, nearing 90 percent in GPU sales alone. This isn't a critique of success; it's a warning about potential bottlenecks and the erosion of bargaining power. When compute, essential frameworks, and curated data reside within a few proprietary stacks, public-interest applications—like multilingual tutoring, teacher planning, and assessment research—get sidelined or priced out. A third AI stack would provide public and cooperative infrastructure to ensure basic access to compute, data protection that protects privacy, and safety evaluations. Without it, education systems will struggle, buying isolated solutions while missing the chance to influence foundational resources.
The policy framework for this third layer is already forming. The EU's AI Act took effect on August 1, 2024, with general-purpose obligations gradually implemented throughout 2025 and high-risk rules to follow. Simultaneously, the OECD's AI Principles—which many jurisdictions now follow—offer a common language for human-centered, trustworthy AI. Regulation alone can't create capacity, but it clarifies responsibilities and reduces uncertainty. When we combine guidelines with pooled resources—common compute, linked data spaces, and shared testing—we create a model for an industry that meets public needs while scaling globally. For schools and universities, this means reliable access to tools that match curriculum, languages, and community values, rather than only seeing systems that prioritize advertising or sales.
An Airbus-style consortium for public AI
Airbus began in 1970 as a Franco-German-UK-Spanish consortium to challenge a dominant player. It didn't succeed through protectionism alone; it pooled R&D risks, standardized interfaces, and coordinated procurement with long-term goals. The results are precise: after facing challenges such as the pandemic and the 737 MAX crisis, Airbus has led global deliveries for 6 years in a row, delivering 766 aircraft in 2024. While no analogy is perfect, the political economy is relevant. What once seemed like a fixed duopoly was transformed by a patient coalition that used shared financing and common standards to accelerate progress. A third AI stack can follow this model: a transatlantic, and eventually global, consortium that networks compute, curates open datasets, and establishes safety tests with independent labs, which collectively provide affordable solutions for public users.
Elements of that consortium already exist. Europe's EuroHPC Joint Undertaking has a budget of about €7 billion to deploy and connect supercomputers across member states. It is now establishing "AI Factories" in different countries to host fine-tuning, inference, and evaluation workloads. In the United States, the National AI Research Resource (NAIRR) pilot began in January 2024, involving 10 federal agencies and over two dozen private and nonprofit partners to provide advanced computing, datasets, models, and training to researchers and educators. Meanwhile, an international network of AI Safety Institutes is beginning to coordinate evaluation methods and share results. If we bring these efforts together under a governance charter focused on education and science, the Airbus analogy could shift from a mere metaphor to a practical plan.
Financing the third AI stack: pooled compute, open data, shared safety
Financing is crucial. The cost of training next-generation models is approaching $1 billion, and infrastructure plans require multi-year commitments. Public budgets can't—and shouldn't—compete dollar-for-dollar with large tech companies, but they can leverage their buying power. Three actions stand out. First, extend EuroHPC-style pooled procurement to create a joint window for education compute, ensuring a set amount of GPU hours for universities, vocational programs, and school districts, with reserved capacity for teacher resources. Second, expand NAIRR into a standing fund with matched contributions from foundations and industry, linked to open licensing for models below a certain capability threshold and protecting access to sensitive datasets above that threshold. Third, formalize the International Network of AI Safety Institutes as the neutral testing ground for models intended for public education, with evaluations focusing on pedagogy, bias, and child safety. These aren't ambitious goals; they extend existing programs.
The regulatory schedule supports this approach. The phased obligations of the EU AI Act for general-purpose and high-risk systems create clear targets for vendors. The OECD's compute frameworks provide governments with a guide to plan capacity along three dimensions: availability and use, effectiveness, and resilience. From the supply side, the market for accelerators is growing rapidly; one forecast predicts AI data-center chips could surpass $200 billion by 2025. As capacity increases, public purchasers should negotiate pricing that favors educational use, exchanging predictability for volume—similar to how Airbus-era launch aid traded capital for long-term orders within WTO rules. The aim isn't to choose winners; it's to ensure that the third AI stack exists and remains affordable.
Open data is the second pillar. Education can't rely on data scraped from the web, which often fails to represent classrooms, vocational training, and non-English-speaking learners. Horizon Europe and Digital Europe are already funding structured data spaces; these should expand to include multilingual educational data, incorporating consent, age-appropriate safeguards, and tracking of data sources. Curated datasets for lesson plans, assessment items, and classroom discussions—licensed for research and public services—could enable smaller models to perform effectively on tasks that matter in schools. The UNESCO Recommendation on AI ethics, accepted by all 194 member states, addresses rights and equity. The third AI stack needs a data governance component that translates these principles into practical rules for generating, auditing, and deleting student data.
Safety standards need to be measurable, not just theoretical. The emerging network of AI Safety Institutes—from the UK to the U.S.—has started publishing pre-deployment evaluations and building shared risk taxonomies. Education regulators can build on this work by adding specific tests for problems such as incorrect citations, harmful stereotypes in feedback, or unsafe experimental suggestions in lab simulations. The goal isn't to certify "safe AI," but to create a system of ongoing evaluation linked to deployment. This means schools would adopt only models that pass basic audits, and providers would commit to retesting after significant updates. The third stack would incorporate red-teaming sandboxes and make evaluation results available to parents and teachers in clear language, turning safety into a common resource.
From cooperation to classroom impact
The Airbus analogy matters most when it benefits teachers on Monday mornings. Evidence is growing that well-guided generative tools can save time. In England's first large-scale trial, teachers using ChatGPT with a brief guide reduced planning time by about 31 percent while maintaining quality. The OECD's latest TALIS survey shows that one in three teachers in participating systems already use AI at work, with higher adoption rates in Singapore and the UAE. These are early signs, not guarantees, but they indicate where public value lies: planning, differentiation, formative feedback, and translation across languages and reading levels. Suppose the third AI stack lowers the cost of these tasks and implements safeguards. In that case, the advantages will multiply across millions of classrooms.
The policy initiatives are concrete. Ministries and districts can contract for "educator-first" model hosting on AI Factory sites that ensure data residency, fund small multilingual models refined on licensed curriculum content, and develop secure portals that give teachers access without dealing with consumer terms of service. Universities can reserve NAIRR allocations for education departments and labs, speeding up rigorous trials that assess learning improvements and bias reduction, rather than just user satisfaction. Safety institutes can hold annual "education evaluations" in which vendors are tested against shared benchmarks developed by teachers and child development experts. None of this requires building a national chatbot; it requires cooperation across borders, budgets, and standards so that classroom-ready AI is a guaranteed resource, not an optional extra.
Critics may argue that public-private cooperation could reinforce existing players or that governments may act too slowly for an industry that doubles its computing every few quarters. Both points have merit. However, the Airbus story shows that coordinated buyers can influence supply while enhancing safety and interoperability. The pace of change isn't as mismatched as it seems. EuroHPC is setting up AI-focused sites; NAIRR is bringing in partners; the International Network of AI Safety Institutes is synchronizing tests. The crucial missing element is a clear education mandate that unites these efforts for classroom applications and establishes shared goals: hours saved, reduced inequalities, measurable improvements in reading and numeracy, and clear audits of model behavior in school environments.
The alternative is stagnation. Suppose we let the market set its own direction. In that case, education will be stuck with sporadic pilots and individual licenses that rarely expand. If we focus solely on regulation, we will create paperwork without the capacity to implement it. The third AI stack represents a middle ground: a collaborative infrastructure that minimizes risks, lowers costs, and empowers educators. Airbus didn't eliminate Boeing; it compelled a duopoly to compete on quality and efficiency. A public AI consortium won't replace private stacks; it will drive them to compete based on public value.
Let's return to the opening figure: an international consortium delivered 766 aircraft last year, outpacing its rival's total by more than double because countries chose to share risk, align standards, and collaborate over decades. Education needs this same long-term perspective for AI. Build the third AI stack now: secure compute resources for teaching and research on EuroHPC and NAIRR, create multilingual, consented data spaces for pedagogy, and establish safety evaluation as an ongoing public service. Then enter into large-scale contracts so that every teacher and learner can access trustworthy AI in their language, aligned with their curriculum, and compliant with their laws. This isn't just about catching the latest trends; it's about establishing the foundational framework that lowers costs, builds trust, and allows schools to choose what works best. Airbus demonstrates that practical cooperation can accelerate progress. The following two years will determine whether education is in control or merely trying to keep up.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
AP News. (2025, January). Boeing's aircraft deliveries and orders in 2024 reflect the company's rough year. Retrieved from AP News.
Cirium. (2025, January). Shaking out the Airbus and Boeing 2024 delivery numbers. Retrieved from Cirium ThoughtCloud.
Digital Strategy, European Commission. (2024–2025). AI Act: Regulatory framework and application timeline. Retrieved from European Commission.
Education Endowment Foundation. (2024, December). Teachers using ChatGPT can cut planning time by 31%. Retrieved from EEF. EuroHPC Joint Undertaking. (2021–2027). Discover EuroHPC JU and budget overview. Retrieved from EuroHPC.
European Commission. (2024). AI Factories—Shaping Europe's digital future. Retrieved from European Commission.
OECD. (2023). A blueprint for building national compute capacity for AI. Retrieved from OECD Digital Economy Papers.
OECD. (2024). Artificial intelligence, data and competition. Retrieved from OECD.
OECD. (2025). Results from TALIS 2024. Retrieved from OECD.
OECD.AI. (2019–2024). OECD AI Principles and adherents. Retrieved from OECD.AI.
Reuters. (2025, January). Airbus keeps top spot with 766 jet deliveries in 2024. Retrieved from Reuters.
Simple Flying. (2025, October). Underdog story: How Airbus became part of the planemaking duopoly. Retrieved from Simple Flying.
Stanford HAI. (2025). AI Index 2025—Economy chapter. Retrieved from Stanford HAI.
TrendForce. (2024, July). NVIDIA's market share in AI servers and accelerators. Retrieved from TrendForce.
U.S. National Science Foundation. (2024, January). Democratizing the future of AI R&D: NAIRR pilot launch. Retrieved from NSF.
U.S. Department of Commerce / NIST. (2024, November). Launch of the International Network of AI Safety Institutes. Retrieved from NIST.
Epoch AI. (2024–2025). Training compute trends and model thresholds. Retrieved from Epoch AI.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.

















Confusopoly Pricing Is a Feature, Not a Bug
Firms use complexity to hide true costs UK evidence shows obfuscation raises prices even with competition Standard total-price labels, algorithm-aware enforcement, and price literacy can protect consumers

In the United Kingdom, regu
AI-Assisted Teaching Is the Reform, Not the Threat
AI-Assisted Teaching Is the Reform, Not the Threat

Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
AI-assisted teaching is the reform, not the threat Shift assessment from answer-hunting to reasoning and disclosure Train every teacher and set simple norms so AI boosts equity and learning

A single statistic should reframe the debate: in 2024, one in four U.S. teenagers used ChatGPT for schoolwork, a figure double that of 2023. The trend is steep, and it is still early. Most teens have not yet used it. But the growth is clear. AI is now a typical study habit for a significant minority, rather than a rare case. We can try to block it or oversee it. Or we can accept a simple truth: technology has already changed classrooms. The question is not how to fix the tool; it’s how to adjust teaching around it. This is at the heart of AI-assisted teaching. We need to set expectations that foster authentic learning, even when answers are just a prompt away. The goal is both straightforward and challenging: create classrooms where the easy path is not the learning path. The easy path should only help students do the hard work more effectively.
Reframing the problem: AI-assisted teaching replaces answer-hunting with thinking
The introduction of chatbots has revealed a problem with assessments rather than a cheating issue. We have asked students to gather facts and repackage them. Machines can do that much faster. AI-assisted teaching requires a shift in instruction. Tasks must encourage students to evaluate sources, compare different perspectives, test claims, and show their reasoning within time constraints. This is not an abstract ideal; it is the only way to keep learning central when AI provides fluent but shallow text. Surveys indicate that teens feel AI is suitable for research but not for writing essays or solving math problems. This instinct is healthy. We should respond with assignments that demand human judgment and original thinking. When a prompt can yield an outline, the assignment must require selecting, defending, and revising that outline using course concepts and cited evidence. Here, the tool becomes the starting point, not the endpoint.
The policy context has also moved in this direction. UNESCO’s global guidance encourages systems to focus on human agency, build teacher capacity, and create age-appropriate guidelines. This advice matters because teaching—not software—determines whether AI is beneficial or harmful. Countries and districts are beginning to respond. Training is increasing rapidly, but it is uneven and incomplete. In the U.S., the proportion of districts offering AI training jumped from about one quarter in fall 2023 to nearly one half in fall 2024, with plans indicating further growth. Teacher surveys show that usage is still concentrated in planning and content drafting, not in deep data use for learning. This is a story about capacity, not fate. Suppose we invest in teachers and redesign assessments. In that case, AI-assisted teaching can turn a potential risk into a tool for greater rigor.

What the data already shows: productivity gains and learning effects
The early evidence regarding teacher workload is clear. When teachers use well-guided prompts, lesson preparation time decreases without affecting quality. A large trial in England found that providing a simple guide along with ChatGPT reduced planning time by about a third. That level of gain is rare in education. It frees up hours for feedback, tutoring, and class discussions—elements of teaching that machines cannot replicate. U.S. surveys reflect this trend. Many teachers report using AI weekly, and those who do so regularly save several hours each week. These savings are not just conveniences; they create time for instruction that focuses on analysis and argument rather than recall. AI-assisted teaching starts by giving teachers back their time.

Learning effects are beginning to show, especially in writing. Randomized trials indicate that structured AI feedback can enhance revision quality for college students and language learners. Improvements happen when students use AI to identify problems and refine drafts, rather than skipping the drafting process altogether. This is the actionable takeaway for classrooms: make AI a critic, not a ghostwriter. When the task requires students to summarize complex readings, compare arguments, and defend a claim with quotations, AI can offer style advice or highlight weak topic sentences. Students must still engage in critical thinking. This approach aligns with AI-assisted teaching principles. The machine excels at providing rapid feedback and minor edits. At the same time, the student tackles tasks that require human reasoning, judgment, and decision-making.
The adoption gap: training, equity, and the new baseline for rigor
Adoption varies across systems and subjects. The OECD’s recent international teacher survey shows that, on average, about one in three teachers use AI, with leaders like Singapore and the UAE approaching three-quarters. In other areas, teacher usage remains below one in five. Within countries, use is primarily focused on lesson drafting and content adaptation, with limited application for formative analytics. This pattern is predictable and solvable. Training drives usage. Where teachers receive structured professional development, adoption and confidence grow. Equity must receive the same attention. If only well-resourced schools incorporate AI-assisted teaching, the existing gaps in feedback and enrichment will widen. The policy expectation should be clear: every teacher should understand how to use AI to create better lesson plans, develop richer examples, and design assessments that value reasoning over searching.
Student use is already prevalent. Global student surveys in 2024 revealed high rates of AI usage for academic support, and national snapshots confirm this trend. In the U.S., teen use of ChatGPT for schoolwork doubled in a year. Studies in the UK report that the majority use AI for assistance with essays or explanations. At the same time, students express concerns that AI might undermine study habits if misused. This tension should shape policy decisions. Banning and detection will not scale; teaching and designing must. Schools should clarify norms for acceptable uses of brainstorming, outlining, and language support; disclosure rules; and penalties for presenting AI-generated text as original work. Most importantly, we must raise the rigor of assignments. When tasks require live problem-solving, oral defenses, and iterative feedback on drafts, quick answers hold little value. AI-assisted teaching redirects student energy back to learning.
What to change now: curriculum, assessment, and teacher craft
Curriculum should include AI as a critical literacy. Students need to learn prompt design, source verification, bias detection, and the distinction between fluent language and genuine reasoning. This is not an optional unit; it belongs in core subjects. In writing courses, AI can model alternative thesis frameworks and illustrate counterarguments. In science, it can suggest experimental variations and help design data tables. In language classes, it can provide feedback focused on form while teachers emphasize meaning and interaction. The system's role is to assist; the student's role is to create. Institutions should also adopt standard disclosure policies so students can indicate where and how they used AI. When rules are straightforward and public, misuse decreases and AI-assisted teaching becomes standard practice rather than a loophole. Thoughtful national guidance already points in this direction; local leaders should implement it promptly.
Assessment must shift from recall to reasoning. This means more supervised, classroom-based writing, more oral defenses, and more multi-step tasks that require judgment at each stage. It also involves using AI to create better rubrics and examples. Teachers can ask AI to draft three sample answers—basic, proficient, and advanced—and then refine them to meet standards. Students learn what quality looks like and why it matters. Districts should update honor codes to include AI disclosure and provide clear examples of allowed and prohibited uses. Training remains crucial. As district surveys show, when leaders invest in ongoing professional learning, teachers’ use of AI becomes safer and more effective. We need the same investment that accompanied the transition from chalkboards to projectors to learning management systems—only faster. That is what AI-assisted teaching requires.
Anticipating the critiques—and answering them with design
Critique one argues that AI undermines originality. It can do so if assignments prioritize speed over thought. The solution is not to ban tools but to redesign assignments. When tasks demand unique evidence from class experiments, local data, or in-person observations, generic outputs will not meet expectations. Trials in writing support this point. AI feedback enhances revision quality when students write and then revise. It offers little support when students skip the draft. The solution lies in design, not in fear. We can establish process checkpoints, require annotated drafts, and include reflection as part of the grading. The outcome is more writing, not less, with AI serving as a coach. That is AI-assisted teaching in action.
Critique two warns that AI could worsen inequity. It might, if only some teachers and students knew how to use it effectively. However, policy can bridge the gap. Provide device access and high-quality AI tools in classrooms. Train all teachers, not just volunteers. Share prompt banks, model lessons, and example tasks created within districts. Current international and national guidelines emphasize user-focused methods and teacher development as key elements for safe AI adoption. Systems that prioritize training report higher usage and greater confidence. Equity is not complex; it is about resources, standards, and time. If we build the necessary supports, AI-assisted teaching can help close gaps by providing all students with quick feedback and more opportunities to engage in real thinking.
We should revisit that initial statistic and consider it carefully. A quarter of teens using ChatGPT for schoolwork is not, in itself, a crisis. It is a signal. This signal indicates that students are already studying in an environment where humans and machines coexist. The only real risk is pretending otherwise. If we improve our teaching—if we elevate the expectations for tasks, normalize disclosure, train teachers widely, and incorporate AI literacy into core subjects—we can keep learning at the forefront. We can ensure that speed serves depth. We can enable convenience to support judgment. This is the promise of AI-assisted teaching, and it is also a necessity. The tools will continue to improve. The only way to stay ahead is to teach what they cannot do: reason with evidence, explain under pressure, and adapt ideas to new situations. Let us create classrooms where these skills become the norm. The statistic will keep rising. Our standards should rise even faster.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Education Endowment Foundation (2024). Teachers using ChatGPT – alongside a guide to support them to use it effectively – can cut lesson planning time by over 30 per cent. (press release, Dec. 12, 2024).
OECD (2025). Teaching for today’s world: Results from TALIS 2024.
Pew Research Center (2025). About a quarter of U.S. teens have used ChatGPT for schoolwork—double the share in 2023. (Jan. 15, 2025).
RAND Corporation (2024). Using Artificial Intelligence Tools in K–12 Classrooms.
RAND Corporation (2025). More Districts Are Training Teachers on Artificial Intelligence.
UNESCO (2023; updated 2025). Guidance for generative AI in education and research.
Zhang, K. (2025). Enhancing Critical Writing Through AI Feedback (randomized controlled trial). Humanities & Social Sciences Communications.
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Weak Dollar Risk: Three Shock Channels That Hit Emerging Economies First
A weak dollar is a systemic risk for non-key currency economies Losses hit reserves, balance sheets, and trade through dollar pricing Diversify reserves, match contract and debt currencies, and build hedging

One fact stands out.
When a Face Becomes a License: Deepfake NIL Licensing and the Next Lesson for Education
When a Face Becomes a License: Deepfake NIL Licensing and the Next Lesson for Education

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
Deepfake NIL licensing will surge as content costs collapse Schools must use contracts and authenticity tech to protect communities Provenance and consent rebuild trust when faces become licensable assets

Only three in ten UK adults say they feel confident in spotting whether AI made an image, voice clip, or video. This finding from the country's communications regulator highlights a critical gap in public life: the difference between what we see and what we can trust. Meanwhile, the influencer market is projected to reach about $32.6 billion in 2025, with content volume growing and production costs decreasing. Put these two facts together, and a simple truth appears. Deepfake NIL licensing—the paid use of a person’s name, image, and likeness through synthetic media—will grow faster than our defenses unless schools, universities, and education ministries take action. This issue goes beyond celebrity appearances. It affects students, teachers, and institutions that now compete for attention like brands and creators do. Classrooms have become studios, and authenticity is now part of the curriculum.
Deepfake NIL licensing is changing the cost curve
The reason for this change is technological. In 2025, OpenAI released Sora 2, a model that generates hyper-realistic video with synchronized audio and precise control. OpenAI’s launch materials highlight improved physical realism. Major tech outlets report that typical consumer outputs run for tens of seconds per clip. The app now includes social features designed for quick remixing and cameo-style participation. In short, anyone can create convincing short videos at scale using someone else’s licensed (or unlicensed) face and voice. When credible tools drop the cost of production to near zero, licensing becomes the business model. The market will follow the path of least resistance: pay creators or their agents a fee for permissioned “digital doubles” and then mass-produce content featuring them. This shift is already visible in pilot platforms that let users record a brief head movement and voice sample for cameo use, complete with revocable permissions and embedded watermarks. However, those marks don’t always hold up against determined adversaries.
Policy is progressing, but not quickly enough. The EU’s AI Act mandates that AI-generated or AI-modified media—deepfakes—must be clearly labeled. YouTube now requires creators to disclose realistic synthetic media. Meta and TikTok have introduced labeling and, importantly, support for Content Credentials (the C2PA provenance standard) to ensure that authentic data travels with files across platforms. However, these disclosures rely on adoption, which is inconsistent. Recent studies indicate that fewer than half of creators use adequate watermarking, and deepfake labeling remains uncommon across the ecosystem. This gap—in rules, enforcement, and infrastructure—provides an opportunity for deepfake NIL licensing to thrive in gray areas. At the same time, misuse spreads through the same channels.

The economics are compelling. Goldman Sachs estimates that the broader creator economy could reach $480 billion by 2027. Influencer marketing alone has jumped from $24 billion in 2024 to an estimated $32.55 billion in 2025. As volume increases, brands will treat faces as licensable assets rather than items to juggle. Unions have noticed this trend. The SAG-AFTRA agreements for 2024–2025 set minimum standards for consent, compensation, and control over digital replicas—including voice—creating a framework that education and youth sports can follow. However, the same time period also revealed how fragile these safeguards can be. Investigations and watchdogs have reported extensive non-consensual deepfake pornography, rising synthetic-fraud rates, and the ease with which realistic fakes can bypass naive checks. Deepfake NIL licensing will flourish in this environment.
Deepfake NIL licensing and campus policy
Education currently sits at a crossroads where NIL, influence, and duty of care intersect. In US college sports, a court-supervised settlement now allows schools to share up to $20.5 million each year directly with athletes for NIL starting in the 2025–26 season. At the same time, the collegiate NIL market itself is often valued at around $1.5 billion, while the broader influencer economy that students engage with is much larger. Many students are already micro-influencers, and many departments now function like media shops. In this climate, deepfake NIL licensing becomes a campus issue because licensing—and mis-licensing—can occur on school accounts, in team agreements, and within courses that require students to create and publish. The ethical guidelines on campus must keep up with the financial realities.

The risk profile is real. Channel 4 News, covered by The Guardian, reported that nearly 4,000 celebrities had been targeted by deepfake porn, which received hundreds of millions of views over just a few months. Teen creators and student-athletes face the same tools and risks, often without protection. Regulators and platforms stress labeling and disclosure, but confidence remains low: only 30% of UK adults feel they can judge whether media was AI-generated. At the same time, surveys in the US show that large majorities want labels because they cannot trust their ability to detect such content. Schools cannot pass this responsibility to platforms. Athletic departments, communications offices, and student services need consent processes, model releases that clearly cover digital doubles, and default provenance tagging on official outputs. This is necessary to protect students who license their likeness as well as those who never intended to do so.
Deepfake NIL licensing needs an authenticity infrastructure
Rules are essential, but infrastructure is crucial. The C2PA “Content Credentials” standard provides media files with a verifiable provenance trail. Major platforms and manufacturers have begun to adopt it, from TikTok’s automatic labeling of credentialed content to camera makers that include credentials in their devices. The Content Authenticity Initiative reports thousands of organizations are now involved. This is significant for education because provenance can be integrated into workflows: a journalism school, a design program, or a district communications team can require Content Credentials during creation and maintain them through editing and publishing. It is not a complete solution; it is a safety measure. Where labels are present, trust can grow. Where they are absent, disclosure rules become optional.
Yet adoption is inconsistent. A 2025 study found that only about 38% of popular image generators use adequate watermarking, and only about 18% employ meaningful deepfake labeling. Meanwhile, platform policies remain fluid. Meta announced labeling in early 2024 and later adjusted its placement and scope. YouTube’s disclosure requirement is now active, and TikTok has expanded auto-labels for media with credentials. Schools should treat these as baselines rather than guarantees. The transparency provisions in the EU AI Act offer a stronger framework and will influence global practices, but institutions cannot wait for uniform enforcement to arrive.
What educators should do now about deepfake NIL licensing
Start with contracts instead of code. Every school involved with student media or athletics should update release forms to include explicit consent, scope, duration, revocation, and compensation for digital replicas, following the principles of transparency, consent, compensation, and control present in recent SAG-AFTRA deals. The form must address voice clones, face swaps, and synthetic narration and specify whether training uses are permitted. For minors, obtain consent from a parent or guardian. For international programs, align forms with the EU AI Act’s disclosure requirements to prevent cross-border confusion. Then support the paperwork with technology: require Content Credentials on all official outputs, enable automatic credential preservation in editing tools, and keep a registry of authorized digital doubles so staff can verify if a “cameo” is licensed.
The curriculum also needs an upgrade. Media and information literacy should make checking provenance and identifying platform-specific labels standard practices. UNESCO warns that two-thirds of creators do not systematically fact-check before posting; PISA materials show how weak digital practices impact learning. Teach students how to interpret a Content Credentials panel, how to disclose synthetic edits, and how to file a takedown when a deepfake targets them. Develop lab exercises around real platform policies on YouTube, Meta, and TikTok. Teach detection skills, but do not base trust solely on visual judgment. The evidence is clear: the public’s ability to identify AI is limited, and in some scenarios, negligible. Trust should come from reliable processes rather than guesswork. Deepfake NIL licensing will hinge on how consent is gathered, how provenance is maintained, and how misuse is managed before it becomes a significant issue.
The existing gap remains a significant concern. Only 30% of adults feel confident identifying AI-generated media, even as the creator and influencer economies fuel the content boom. This serves as the backdrop for deepfake NIL licensing—a system that will monetize faces on a large scale, reward permissioned clones, and entice bad actors to bypass consent. Education cannot remain on the sidelines. It is the place where young creators learn the rules of the attention economy. It is where student-athletes negotiate NIL for the first time. It is where public trust in knowledge is either rebuilt or lost. The call to action is clear: align releases with the realities of digital replicas, require provenance by default, teach disclosure and verification as essential skills, and prepare for the day a viral fake targets your institution. If we do this, schools will not just keep pace with the platforms. They will set the standard for a public space where licensing a face is straightforward—but earning trust remains the goal.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Adobe. (2024). Authenticity in the age of AI: Growing momentum for Content Credentials across social media platforms and AI companies.
Coalition for Content Provenance and Authenticity (C2PA). (2025). C2PA technical specification v2.2.
Content Authenticity Initiative. (2025). 5,000 members: Building momentum for a more trustworthy digital world.
European Parliament. (2025, Feb. 19). EU AI Act: First regulation on artificial intelligence.
Freshfields. (2024, Jun. 25). EU AI Act unpacked #8: New rules on deepfakes.
Goldman Sachs. (2023, Apr. 19). The creator economy could approach half-a-trillion dollars by 2027.
Influencer Marketing Hub. (2025, Apr. 25). Influencer Marketing Benchmark Report 2025.
Meta. (2024, Feb. 6). Labeling AI-generated images on Facebook, Instagram and Threads.
Ofcom. (2024, Nov. 27). Four in ten UK adults encounter misinformation; only 30% confident judging AI-generated media.
OpenAI. (2025, Sept. 30). Sora 2 is here.
OpenAI. (2025, Feb. 15). Sora: Creating video from text.
Opendorse. (2025, Jul. 1). NIL at Four: Monetizing the new reality.
Reuters. (2025, Jul. 10). Industry video-game actors pass agreement with studios for AI security.
SAG-AFTRA. (2024–2025). Artificial Intelligence: Contract provisions and member guidance.
The Guardian. (2024, Mar. 21). Nearly 4,000 celebrities found to be victims of deepfake pornography.
TikTok Newsroom. (2024, May 9). Partnering with our industry to advance AI transparency and literacy. https://newsroom.tiktok.com.
YouTube Help. (2024). Disclosing use of altered or synthetic content.
Zhao, A., et al. (2025, Oct. 8). Adoption of watermarking for generative AI systems in the wild. arXiv.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Nepal Youth Protests and the BRI: How Street Anger Reshapes Beijing’s Neighborhood Policy
Undersea Cable Security Is Now Education Policy in Southeast Asia
Undersea cable security is now core education infrastructure in Southeast Asia Taiwan’s 2025 cable disruptions show how gray-zone incidents can cut classes, exams, and research ASEAN must build redundancy and protect its seabed links
