Stablecoin Ponzi Risk Is a Consumer-Protection Time Bomb
Stablecoin yields mimic Ponzi dynamics and amplify run risk Ban interest on payment tokens; regulate platforms that bolt on returns Educators and institutions should teach risks and keep payments separate from investments

Southeast Asia AI Productivity: Why the Payoff Rises or Falls with Learning, Not Just Spend
Southeast Asia AI Productivity: Why the Payoff Rises or Falls with Learning, Not Just Spend

David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Published
Modified
AI investment pays off in Southeast Asia only when paired with real workforce learning Training, workflow redesign, and governance turn tools into measurable productivity and wage gains Shift budgets from hardware to people so diffusion is broad, fast, and inclusive

The most revealing number in today’s AI conversation isn’t a billion-dollar investment or a flashy compute benchmark. It’s the fourfold difference in productivity growth between sectors most exposed to AI and those least exposed. This is coupled with a 56% wage premium for workers in AI-skilled roles. These indicators are based on PwC’s analysis of nearly a billion job ads and firm outcomes. They highlight a clear point: where AI is used effectively, output per worker increases quickly, and wages rise. Where it isn’t applied well, the opposite happens. In Southeast Asia, the investment narrative is significant, with tens of billions of dollars poured into data centers and cloud regions, leading the region's digital economy back to double-digit growth. However, the returns depend on people, processes, and time. The main argument of this essay is straightforward: Southeast Asia's AI productivity will depend on how quickly schools, companies, and government bodies can transform AI from mere tools into daily habits.
Southeast Asia AI productivity starts with human learning
We know AI can boost output within firms. An extensive study of customer support agents found that access to a generative AI assistant increased average productivity by about 14%, with the most significant gains—about a third—among the least experienced workers. This scenario is common in many Southeast Asian service jobs, which often have high turnover, steep learning curves, and significant skill gaps. Studies of software illustrate the same point. In a controlled task, developers using GitHub Copilot completed coding nearly 56% faster than the control group. This efficiency increase adds up over a year of sprints and fixes. The mechanism isn’t magical. AI captures practical know-how from skilled workers and offers it to novices during their work, shortening the learning curve and spreading best practices. In short, Southeast Asia's AI productivity improves when learning speeds up.
The challenge is that learning never happens for free. Surveys show many employees save significant time using AI, but only a small percentage receive formal training on how to apply it. A global workplace poll found that users save about an hour per day on average, but only 1 in 4 had received training. Another study from the St. Louis Fed measured time savings of 5.4% of weekly hours for users—about 2 hours per week for a standard 40-hour schedule. Training older or less tech-savvy workers requires intentional effort. In a UK pilot, simple permissions and a few hours of coaching significantly increased AI usage among late-career women in lower-income jobs—a lesson with clear implications for Southeast Asia's diverse labor markets. Unless leaders allocate time and money for this human ramp-up, AI tools will remain unused, and productivity will stagnate. Improving Southeast Asia's AI productivity is primarily a management challenge rather than a hardware race.
Southeast Asia AI productivity depends on uneven adoption
Adoption across the region is occurring but remains uneven. According to Google, Temasek, and Bain, over $30 billion was invested in AI infrastructure in Southeast Asia during the first half of 2024, while the broader internet economy returned to double-digit growth. Governments and tech giants are acting quickly: Thailand approved $2.7 billion in funding for data center and cloud investments, while Microsoft committed $1.7 billion to Indonesia, aiming to train 840,000 Indonesians in AI skills as part of a regional goal of 2.5 million. Yet, enterprise readiness lags. An IDC/SAS survey revealed that only 23% of Southeast Asian organizations are at a “transformative” stage of AI use. A separate Deloitte survey shows that executives identify the most significant barriers as talent shortages, risk, and a shaky understanding of the technology. In simple terms, capital is arriving faster than the necessary skills.
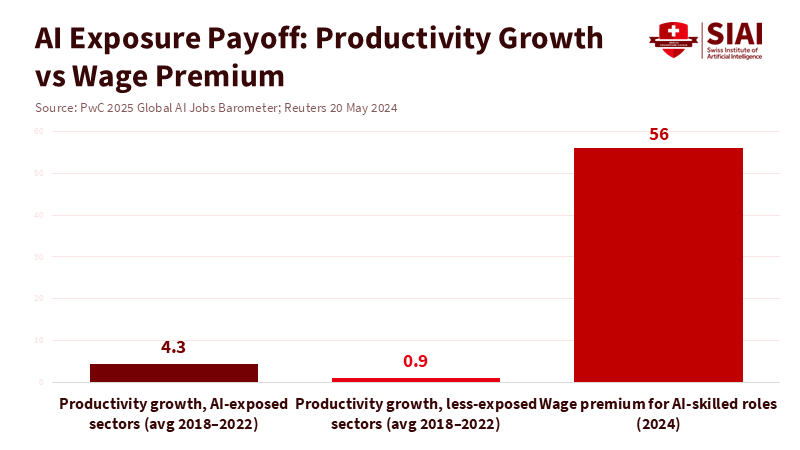
There are encouraging signs. Agentic AI—software that connects tasks—might expand quickly as companies turn pilot programs into standard operations. Multiple regional surveys indicate that about two in five firms already use such agents, with most others planning rollouts within the following year. However, relying on averages obscures significant national differences in skills, infrastructure, and digital trust. The World Bank warns that when adoption depends on task structures and complementary skills, the benefits will flow to workers and firms that can adapt to the technology, leaving others behind. The OECD reaches a similar conclusion: AI can boost productivity, but long-term benefits rely on widespread usage, regulations, and inclusivity. This leads to a clear policy implication: to enhance Southeast Asia's AI productivity, leaders must close the “last-mile” gap between large capital expenditures and frontline workers.
Financing Southeast Asia AI productivity: from capex to opex
Much of the AI budget in the region focuses on hardware, cloud credits, and vendor proofs of concept. The larger returns lie in the operating budget: training time, workflow redesign, risk management, and change processes. This is where many digital programs fall short. Research shows that 70% of significant transformations exceed their original budget—often because they underestimate the organizational effort involved. The empirical evidence on potential payoff is becoming clearer. PwC’s analysis links AI exposure to faster productivity growth and increased revenue per employee. MIT’s call center experiment, along with the Copilot RCT, provides estimates of the gains firms can expect from well-planned adoption. These figures support a shift in perspective: view training and change as investments with measurable results, not just expenditures to cut.
What could effective operating expenses look like? Start with hours saved. If typical users can save around 5% of their weekly time now—and even more on repetitive knowledge tasks—modest adoption across a 10,000-person company can yield thousands of hours freed weekly. Add small-group coaching, workflow standards, and secure model access, and the time savings can accelerate further. In practice, measurable benefits often appear quickly once tools are integrated: Bain’s Southeast Asia analysis notes that many firms see returns within 12 months. On the public side, targeted skills programs can increase returns on private investments. The ILO’s new initiative to deliver digital skills in ASEAN’s construction sector serves as a valuable model for employer-linked training. Microsoft’s large-scale upskilling efforts in Indonesia aim in the same direction. A practical rule emerges: if we cannot identify scheduled training hours and a redesigned workflow, we should expect Southeast Asia's AI productivity to disappoint, regardless of how much computing power we acquire.
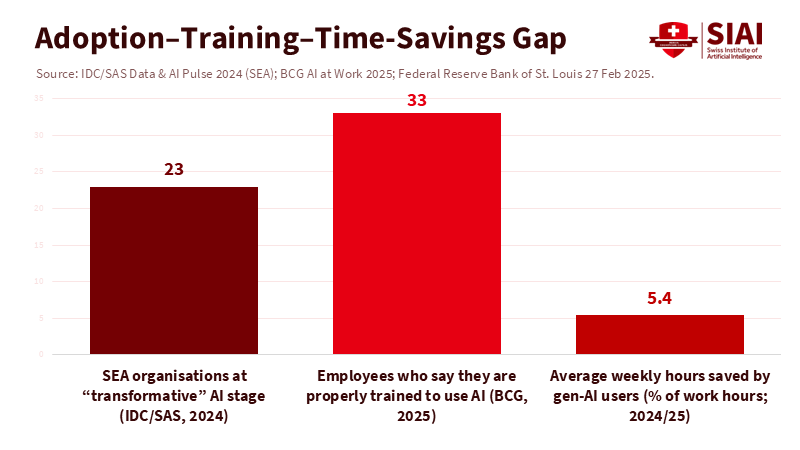
Governing Southeast Asia AI productivity for the long run
Sustained productivity improvements require policies that facilitate diffusion while minimizing harm. The World Bank’s work in East Asia and the Pacific highlights that skill policies, mobility, taxes, and social protections will determine whether technology promotes inclusion or inequality. In education, this means expanding from pilot programs to overarching curricula that include training in prompting, verification, and tool selection from upper secondary levels onward. In TVET systems, this involves establishing AI labs linked to local businesses and introducing stackable micro-credentials that align with real jobs. In universities, it means enforcing strict academic integrity policies while still allowing supervised AI use for drafting, coding, and analysis.
For administrators, procurement should focus on outcomes rather than just acquiring licenses. Contracts can stipulate vendor-funded training hours per license, workflow templates, and measurable time savings at six- and twelve-month intervals. Ministries could collaborate to establish regional standards for model safety, data governance, and interoperability, thereby reducing costs and risks for smaller institutions. The OECD's caution regarding uneven diffusion, combined with PwC's findings on wage premiums, supports reskilling subsidies tied to wages and mobility assistance, ensuring benefits don't just concentrate in already-advantaged areas. Lastly, infrastructure policy must remain practical. Reports on Thailand’s data center expansion and coverage of Indonesia’s hyperscale investments illustrate this point. Data centers are vital, but their social return depends on practical skills and open access. Otherwise, these power-hungry assets could remain unused while schools and clinics lack the necessary tools. The goal of governance is steady, inclusive, measurable, and sustainable improvement in Southeast Asia's AI productivity.
The key figures introduced at the beginning of this essay—greater productivity growth and a 56% wage premium in AI-focused roles—are not inevitable; they are invitations to action. They demonstrate what can be achieved when tools meet trained individuals and when work processes are restructured. In Southeast Asia, capital is flowing in through national data center initiatives and hyperscaler commitments for training. Research results consistently indicate that productivity increases most rapidly when newcomers learn quickly and when managers allocate resources for change. The region now faces a clear choice. It can view AI as a competition for hardware and settle for narrow benefits concentrated in a few companies and cities. Alternatively, it can prioritize people—teachers, nurses, programmers, clerks—and invest in the time, coaching, and standards necessary for practical tool usage. If it chooses the latter path, Southeast Asia's AI productivity could become a strong driver of the next growth cycle: compounding, inclusive, and evident in both paychecks and profits.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Adecco Group. (2024, October 17). AI saves workers an average of one hour each day (press release).
AP News. (2024, April 30). Microsoft will invest $1.7 billion in AI and cloud infrastructure in Indonesia.
Bain & Company; Google; Temasek. (2024). economy SEA 2024. Key highlights page.
BCG. (2024, June 26). AI at Work in 2024: Friend and Foe.
Deloitte. (2025). Generative AI in Asia Pacific (regional pulse).
IDC (commissioned by SAS). (2024, November 6). IDC Data & AI Pulse: Asia Pacific 2024 (SEA cut).
ILO. (2025, June 26). New initiative to boost green and digital skills in ASEAN construction.
McKinsey & Company. (2023, April 11). Why most digital transformations fail—and how to flip the odds.
NBER (Brynjolfsson, Li, & Raymond). (2023). Generative AI at Work (Working Paper No. 31161).
OECD. (2024). The impact of artificial intelligence on productivity, distribution and growth.
PwC. (2025, June 3/26). Global AI Jobs Barometer press materials (productivity growth; 56% wage premium).
Reuters. (2025, March 17). Thailand approves $2.7 billion of investments in data centres and cloud services.
St. Louis Fed. (2025, February 27). The Impact of Generative AI on Work Productivity.
The Conversation (hosted via University of Melbourne). (2025, August 14/15). Does AI really boost productivity at work? Research shows gains don’t come cheap or easy.
World Bank. (2025, June 2). Future Jobs: Robots, Artificial Intelligence, and Digital Platforms in East Asia and Pacific; (2025, August 5) How new technologies are reshaping work in East Asia and Pacific.
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.

















AI Housing Supply Needs a Different Approach
AI Housing Supply Needs a Different Approach

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
Tiny city samples won’t close the 3.7–3.9 million-home gap Use real-time public and private data under shared standards and privacy rules Governments set rails, platforms supply feeds, and weekly human review turns signals into units

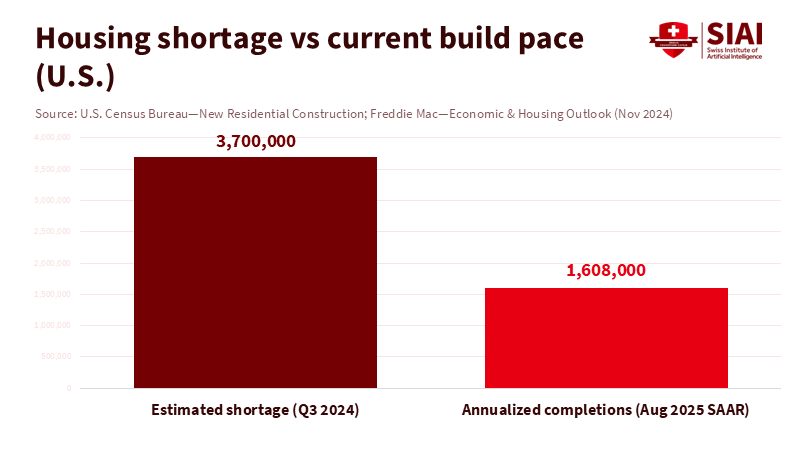
Cities do not require a small survey of 50 or 100 households to address the housing shortage. They need a system that can track the market in real time. The key number is clear. The United States is short by about 3.7 to 3.9 million homes, depending on the measure used. This gap did not appear overnight, and it won't close with minor initiatives. It can only close if we utilize the data we already have — much of which is in the private sector — and establish clear guidelines for its use. We should measure, govern, and act at scale. This is the purpose of AI housing supply. It should not replicate the weaker aspects of a survey. Instead, it should strive for a comprehensive market view that updates monthly, or even weekly, and connects to permits, prices, and completions that already influence the system.
Reframing the Problem: From Sampling to Standards for AI Housing Supply
The current suggestions propose that cities create groups, harmonize a few fields, and test AI on small samples. The intention is positive. The aim is to accelerate approvals and site selections. However, relying on samples of a few homes per city cannot compete with the insights that private platforms gather from over 100 million properties every day. Zillow alone offers data on more than 110 million homes and publishes valuations on approximately 100 million, with median error rates under 2 percent for properties on the market in recent years. Redfin updates listings, demand, and price indicators weekly across different markets.
Additionally, public agencies publish timely information on completions, permits, and household counts. The issue is not a lack of data feeds. It lies in the absence of shared standards and lawful, privacy-sensitive methods for combining public and private signals. AI housing supply should begin there, not with a limited city-level sample that cannot capture the market's dynamic aspects.
The argument for smaller samples is based on quality and control. It implies that carefully curated records can address messy, biased inputs. However, this approach sacrifices broad coverage for attention to detail. Housing markets depend on marginal changes: the extra lot that gets rezoned, the small multifamily project that finishes construction, and the changes in price-to-income ratios that allow more buyers to enter the market. If your data falls short of these margins, your policies will not align with the market. Shared standards—such as standardized schemas, reference IDs, and governance—enable us to maintain broad coverage while improving quality. This is the necessary reframing at this moment.
What the Data Already Shows—and How to Use It
Start with the supply. Federal data tracks completions and new construction by unit type and region. In August 2025, the United States completed homes at an annualized rate near 1.6 million units. The single-family rate averaged about 1.09 million units, while the multifamily rate averaged around 500,000 units. Although these figures fluctuate monthly, they remain quick, public, and consistent. They provide a framework for cities to monitor supply and demand. They also allow us to evaluate whether zoning changes or fee modifications appear in future pipelines. AI systems do not need to guess these trends when the data is already available. They should incorporate this information, coordinate it with local rules, and identify where approvals are delayed.
Now let's examine demand and prices. Private platforms track listings, tours, concessions, and closing spreads almost in real time. Zestimates for listed homes maintain low median error rates and span both urban and rural markets. Redfin provides weekly updates on shifts in supply, sale-to-list ratios, and price reductions. When cities decide where to speed up reviews or allow higher housing density, these signals are crucial. They reveal market stress, slack, and how quickly policy changes reach the closing table. If we separate public systems from these private feeds, we limit the effectiveness of the AI tools we hope will assist us. The best approach is to establish lawful, transparent data-sharing with enforceable privacy protections, then train systems using the combined data.
The demand-supply gap is significant and persistent. Freddie Mac's latest analysis estimates the shortage at about 3.7 million homes as of late 2024. Up for Growth's independent estimate shows underproduction nearing 3.85 million in 2022, a slight decrease for the first time in several years. We do not require small samples to recognize the obvious. We need guidelines that allow local leaders to use high-coverage, high-frequency data to direct their limited time to the most pressing issues: land, permits, utilities, and financing timelines. AI can help prioritize cases and identify where an additional inspector or a small code change could create hundreds of units. But only if the models have a complete view.
Governance First: Privacy, Accuracy, and the Public-Private Divide in AI Housing Supply
Privacy poses a real risk on both sides. The federal government has acknowledged this in its policies. Executive Order 14110 directs agencies to manage AI risks, including privacy issues. The Office of Management and Budget has issued guidance on responsible federal AI use. The Census Bureau has strong disclosure controls, including differential privacy, for its core data products. These methods protect individuals but can impact accuracy in small areas if not correctly adjusted. That is a governance lesson, not a reason to shy away from standards. Cities should adopt privacy terms that align with federal practices, require vendor model evaluations, and maintain a simple register outlining "what data we use and why." The goal is balance: public entities share only what is necessary; private partners document their models and controls; and the public can audit both.
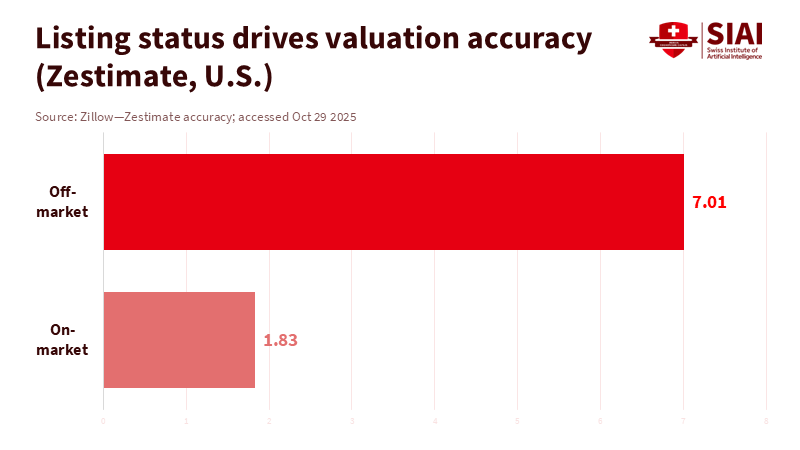
Accuracy is the second principle. Zillow's documentation outlines how coverage and error vary by market and listing status. Redfin explains when metrics are weekly, rolling, or updated. Public datasets indicate error ranges and revisions. The solution is not to assume that a hand-picked sample is more reliable. Instead, every data field in an AI pipeline should have an accuracy note, a last-updated tag, and a link to its methodology. This enables human reviewers and auditors to assess each signal. It also prevents models from overly relying on a single source in a thin market. Cities can specify these requirements in procurement and can reject claims lacking documentation. This is the kind of straightforward governance that makes AI valuable.
Next comes defining the public-private divide. The government should establish rules for common parcel IDs, zoning and entitlement schemas, timelines for permit statuses, and open APIs for decision-making and appeals. It should not attempt to recreate national market feeds that brokerages and platforms already assemble and refresh. Instead, cities should integrate those feeds into their regulations through contracts, complete with audit rights and sunset clauses. This division of labor respects expertise and accelerates learning. It also reduces the temptation to create a flashy but ineffective government app that wastes funds and stalls after a pilot.
What This Means for Regions—For Universities, School Districts, and City Halls
An education journal should focus on training systems, not just on models. Universities can lead this effort by creating cross-disciplinary studios where planning, data science, and law students develop “living codes” for AI housing supply. These studios can outline a region's permitting steps, label each with data fields, and provide an open schema that any city can implement. They can also assess model biases with real zoning cases and publish the results. This work is practical. It provides cities with ready-made resources and opens pathways for students to pursue meaningful careers in public problem-solving.
School districts have a direct interest in this issue. Housing developments affect enrollment, bus routes, and staffing. Districts should participate when cities establish data standards, ensuring school capacity and equitable access goals are considered alongside sewer maps and transit plans. When AI models highlight growth areas, districts can anticipate teacher hiring and special needs services earlier. They can also verify that new housing aligns with safe walking zones. This is how “AI housing supply” becomes beneficial for families rather than just a distant technical discussion.
City halls can take three actions. First, they should publish a clear, machine-readable entitlement map with parcel IDs and decision timelines. Second, they should sign agreements for data sharing with one or two major private feeds and one public feed that together cover listings, permits, and completions. Third, they should form a small human team that reviews flagged models weekly and updates the public about changes: a rule modified, a utility conflict resolved, or an appeal settled. The weekly frequency is crucial. It fosters transparency and turns data into actionable units.
The objections to these proposals are predictable and deserve responses. One concern is privacy. Here, federal practices demonstrate both the risks and the solutions. Strong disclosure controls can protect individuals while still providing valid aggregate data, and cities can require similar safeguards from vendors. Another objection is that private data might reflect platform interests and potentially include biases. This is valid, which is why contracts should demand documentation of training data, regular error updates, and the possibility of independent audits. A third objection claims that the government must “own” the core models. This confuses ownership with control. Clear standards, transparent contracts, and public dashboards provide absolute control without forcing cities to become data brokers themselves.
There is also the belief that a public cohort will build expertise. It can, but only if it focuses on the correct elements: standards, IDs, APIs, and governance. Much of the necessary framework already exists. Zillow provides extensive coverage in its valuation system; Redfin updates its market data weekly; and federal datasets track counts and completions. The innovative public strategy is to integrate these resources rather than replicate them. And when a private dataset disappears, such as Zillow’s ZTRAX for open research, the response should not be to create a weaker copy. Instead, it is essential to require portable schemas and maintain a minimal public “backbone” of critical fields, so cities can seamlessly exchange data sources.
The timeline is essential. In September 2025, the Census Bureau released new one-year ACS estimates. In August 2025, completions were approximately 1.6 million SAAR. These are current signals, not historical artifacts. They should now be part of city dashboards. When a governor extends a missing-middle incentive or a council adjusts parking requirements, we should see results in permit statuses within weeks and in construction starts within months. AI can help to identify these shifts faster and filter out noise. But standards and data access are necessary for this detection to be effective.
The “home genome” metaphor is compelling, but it risks misinterpretation. The Human Genome Project required new measurements to uncover what was previously invisible. Housing is different. Much of it is already visible. Parcels, zoning, utilities, permits, listings, prices, rents, starts, and completions are available, albeit scattered. The challenge is not discovery but rather integration and governance. This is the leap we need to take: stop acting as if we need to gather a new organism; instead, focus on wiring the system we already have.
Build the Infrastructure, Not Another Sample
Return to the number: a shortage of about 3.7 to 3.9 million homes. That is the key takeaway. AI housing supply must target that scale. A small sample cannot handle this challenge, no matter how well curated it is. The most efficient route is to create public infrastructure—standards, IDs, APIs, and privacy regulations—and apply the best available public and private data to it. Cities maintain control by setting the rules and auditing the models. Platforms should continue what they do best: gathering signals and updating them. Educators should train the workforce that can maintain this infrastructure and question the models. If we succeed, weekly dashboards will translate into construction starts and new residents. If we fail, we will spend another cycle on pilots that yield little and provide less help. The choice is clear: build the infrastructure now and let the market's complete signals guide our efforts.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Brookings Institution. “A home genome project: How a city learning cohort can create AI systems for optimizing housing supply.” Accessed Oct. 29, 2025. Brookings
Census Bureau. “American Community Survey (ACS). 2024 1-year estimates released.” Sept. 11, 2025. Census.gov
Census Bureau. “New Residential Construction: August 2025.” Sept. 17, 2025. Census.gov
Census Bureau. “Simulation, Data Science, & Visualization (research program pages).” 2025. Census.gov
Census Bureau. “Disclosure Avoidance and the 2020 Census.” 2023. Census.gov
Community Solutions. “Can AI Help Solve the Housing Crisis?” Sept. 23, 2025. Community Solutions
Executive Office of the President. “Executive Order 14110: Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence.” Nov. 1, 2023. Federal Register
Freddie Mac. “Economic, Housing and Mortgage Market Outlook—Updated housing shortage estimate (3.7 million units as of Q3 2024).” Nov. 2024 and Jan. 2025 updates.
HUD & Census Bureau. “American Housing Survey (AHS) 2023 release and topical modules.” Sept. 25, 2024.
Redfin. “Data Center: Downloadable Housing Market Data.” Accessed Oct. 29, 2025.
Up for Growth. “Housing Underproduction in the U.S. (2024).” Oct. 30, 2024.
Zillow. “Why Doesn’t My House Have a Zestimate?” Accessed Oct. 29, 2025.
Zillow. “Zestimate accuracy.” Accessed Oct. 29, 2025.
Zillow. “Building the Neural Zestimate.” Feb. 23, 2023.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Public R&D Subsidies Are the Risk Buffer Poor Countries Need
Public R&D subsidies de-risk innovation in poor countries Brazil’s Embrapa shows ~110% productivity gains and ~17:1 payoffs Fund local adaptation, build capacity, and open data to crowd in private capital

When Industrial Subsidies in East Asia Hold Back the Best Firms
Industrial subsidies in East Asia misallocate resources and dampen productivity Cheap credit and opaque, incumbent-favoring programs entrench weak firms Make support transparent, performance-based, and linked to skills and exit

Multi-Issuer Stablecoins Can Make Europe Safer, If We Build the Backstop
Europe shouldn’t ban multi-issuer stablecoins; it should backstop them Require joint redemption, a prefunded mutual buffer, and fast resolution to contain failures This builds euro-scale alternatives to dollar coins while reducing systemic risk

From Capital to Classrooms: The Demand Case for Southeast Asia Sovereign Wealth Funds
The bottleneck is investable projects, not capital Build regulated grids and education contracts that generate steady, social returns With clear rules, Southeast Asia sovereign wealth funds can turn savings into national progress

Deposit Rate Elasticity Is the Weakest Link in Monetary Transmission
Mortgage rates move fast; deposit rate elasticity stays weak Most households ignore higher yields; wealthy react more but leave money Clear benchmarks, auto-sweeps, and education can raise responsiveness safely

A single figure
Pecking Order Financing Beats Rate Tweaks: Why Cash Buffers, Not 25 bps, Move Investment
Small rate tweaks rarely change investment Firms follow pecking order financing—cash first, then debt, equity last Targeted credit tools and skills policy move capex more than blanket cuts

Euro-a
AI Chatfishing, AI Companions, and the Consent Gap: Why Disclosure Decides the Harm
AI Chatfishing, AI Companions, and the Consent Gap: Why Disclosure Decides the Harm
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
AI chatfishing hides bots in dating, removing consent and raising risks Declared AI companions can help, but still need strict guardrails Require clear disclosure, platform accountability, and education to close the consent gap

When a machine can pass for a person 70 percent of the time, the burden of proof shifts. In a 2025 study, which served as a modern Turing test, judges who chatted simultaneously with a human and a large language model identified the AI as the human 73 percent of the time. This study, conducted by [research institution], used [specific AI model] to demonstrate the rapid advancement of AI technology. This is not a simple trick; it marks the point where “Are you real?” stops being a fair defense. Move this capability into online dating, and the stakes increase rapidly. A wrong guess can lead to emotional, financial, and sometimes physical costs. AI chatfishing, which involves using AI to impersonate a human in romantic chat, thrives when the line between person and program is hard to define and is clear that it is blurred. To protect intimacy in the digital age, we need a straightforward rule that both the law and platforms can support: disclose whenever it’s a bot, every time, and make dishonesty costly for those who create the deception.
AI Chatfishing versus AI Companions: Consent, Expectations, and Incentives
AI chatfishing and AI companions are not the same. Both operate on the same technology and can appear warm, attentive, and even sweetly awkward. Yet, the key difference lies in consent. With AI companions, users opt in; they choose a system that openly simulates care. In contrast, AI chatfishing lures someone into a conversation that appears authentic but isn't. This difference alters expectations, power dynamics, and potential harm. It also changes incentives. Companion apps focus on satisfaction and retention by helping users feel better. Deceptive actors prioritize gaining resources—money, images, time, or attention—while concealing their methods. When the true nature of the speaker is hidden, consent is absent, and the risks range from broken trust to fraud and abuse. The distinction is moral, legal, and practical: disclosure turns a trick into a tool, while the lack of disclosure turns a tool into a trap. The rule must be as clear as the chat window itself.
Consequently, clear disclosure is essential. Europe has established a foundation. The EU AI Act requires that people be informed when they interact with a chatbot so that they can make an informed choice; this responsibility helps maintain trust. In October 2025, California took further steps. A new state law requires “companion chatbots” to state that they are not human, incorporate protections for minors, and submit public safety reports—including data on crisis referrals—so parents, educators, and regulators can see what occurs on a broader scale. Suppose a reasonable user might mistake a chatbot for a human. In that case, the system must disclose this, and that reminder must recur for minors. These rules outline a global standard the intimate internet needs: when software communicates like a person in contexts that matter, it must identify itself, and platforms must ensure that identity is unmistakable.
The Growing Role of AI in Dating and Why AI Chatfishing Thrives
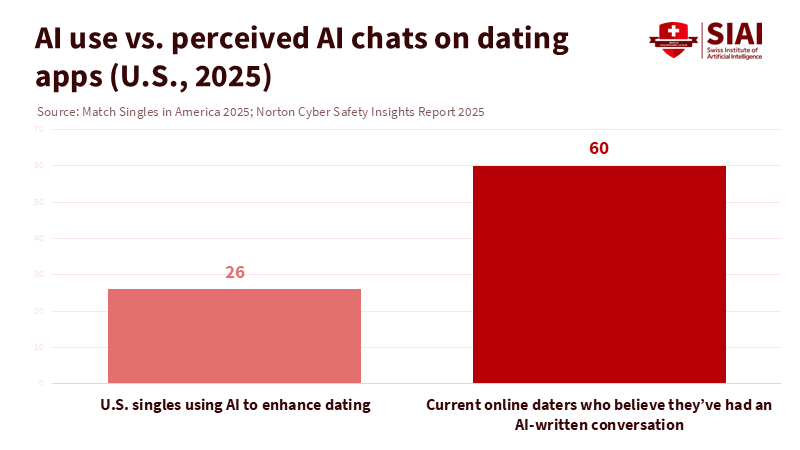
Usage is increasing rapidly. Match Group’s 2025 Singles in America study, conducted with Kinsey Institute researchers, reveals that about one in four U.S. singles now uses AI to improve some aspect of dating, with the highest growth among Gen Z. A separate 2025 Norton survey shows that six in ten online daters believe they have had at least one conversation written by AI. Major outlets have noted this shift as platforms introduce AI helpers to enhance profiles and generate conversation starters. At the same time, users adopt tools to improve matches and avoid awkward starts. Meanwhile, role-play and companion platforms keep millions engaged for extended periods—indicating that conversational AI is not just a novelty but a new form of social software. This scale is significant: the more common AI chat becomes, the easier it is for AI chatfishing to blend in unnoticed.
Detection is also challenging in practice. The same Turing-style study that raised concerns explains why: when models adopt a believable persona—young, witty, and adept online—they not only imitate grammar; they also replicate timing, tone, and empathy in ways that feel human. Our own psychology contributes to this, too. We enter new chats with hope and confirmation bias, wanting to see the best. A university lab study in 2024 found that non-experts only identified AI-generated text about 53 percent of the time under test conditions, barely above random guessing. Platforms are working on this. Bumble’s “Deception Detector” utilizes machine learning to identify and block fake, spam, and scam profiles; the company claims it can catch the majority of such accounts before they reach users. This is helpful, but it remains a platform promise rather than a guarantee, and deceptive actors adapt. The combination of increasing usage, human misjudgment, and imperfect filters creates a persistent space where AI chatfishing can thrive.
Why AI Companions Are Different and Still Risky for the Public Good
Stating that an entity is artificial changes the ethics. AI companions acknowledge their software status, and users can exit at any time. Many people report real benefits: practice for socially anxious daters, relief during grief, a space to express feelings, or prompts for self-reflection. A widely read first-person essay in 2025 describes how paying for an AI boyfriend after a painful breakup revealed that the tool provided steady emotional support—listening, prompting, and encouragement—enough to help the writer regain confidence in life. Public radio coverage reinforces this idea: for some, companions serve as a bridge back to human connection rather than a replacement. The role of AI companions in providing emotional support is significant and should be acknowledged.
However, companions still influence the public space. If millions spend hours practicing conversations with tireless software, their tolerance for messy human interaction may decline. Suppose teenagers learn early scripts about consent, boundaries, and empathy from systems trained on patterns. In that case, those scripts may carry into classrooms and dorms. New research warns that some systems can mirror unhealthy behaviors or blur sexual boundaries when protections are weak, especially for minors. The potential negative influence of AI companions on social skills is a concern that needs to be addressed.
Additionally, because many companion platforms frequently update their models and policies, the “personality” users rely on can change suddenly, undermining relationships and trust. The social consequences develop slowly and collectively: norms change, affecting not just individual experiences. This is why disclosure is vital, but not enough. We need age-appropriate designs, limitations on prolonged sessions, and protocols that encourage vulnerable users to seek human help when conversations become troubling. These requirements fit a declared, opt-in product; they cannot be enforced on hidden AI chatfishing.
Policy and Practice: A Disclosure-First Standard for the Intimate Internet
We should shift from asking whether AI chatfishing or AI companions are “worse” in the abstract and instead align rules with actual harm. Start with a disclosure-first standard for any intimate or semi-intimate setting, including dating apps, private marketplaces, and companion platforms. Suppose a reasonable person might mistake the speaker for a human. In that case, the system must say it is not and repeat this cue during more extended conversations. This rule should be enforced at the platform level, where logs, models, and interface choices can interact effectively. Align with existing frameworks: adopt the EU transparency baseline and the new California requirements to ensure users see consistent messages across regions. Importantly, notices should be placed inside the chat box, not in footers or terms links. The goal is to make identity part of the discussion, not a hidden puzzle for users already managing emotional and relational risks.
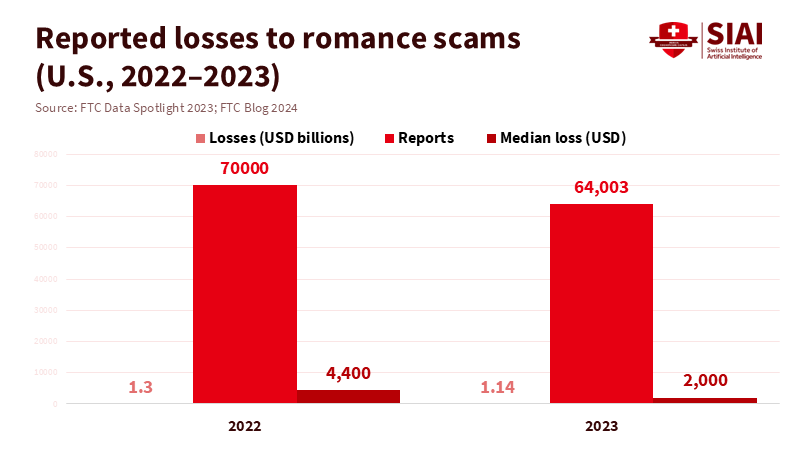
Markets also need incentives to combat deception that disclosure alone cannot address. Romance scammers extracted at least $1.14 billion from U.S. consumers in 2023, with a median reported loss of $2,000 per person; the actual toll is likely higher because many victims do not report. Platforms should face consequences when they ignore clear signals: rapid message frequency from new accounts, reuse of scripted templates, or coordination among fraud rings across apps. Regulators can facilitate this by measuring meaningful outcomes. They should publish standardized safety dashboards on bot takedown rates, time to block after a user’s first report, and median losses recovered. Require annual third-party audits to investigate evasion tactics and false positives. California’s initiative to mandate public reporting on crisis referrals is a positive step; similar disclosures on deception would help turn safety from a slogan into a measurable factor. For declared companions, require opt-in for minors, along with additional reminders and session limits, as California law requires. These are not theoretical ideals; they are practical measures aimed at reducing the space where AI chatfishing can profit.
Education Closes the Loop
K-12 digital citizenship programs should go beyond phishing links to focus on interpersonal authenticity: how to identify AI chatfishing, how to ask for identity confirmation during a chat without feeling ashamed, and how to exit quickly if something feels off. Colleges should update conduct codes and reporting systems to include AI-related harassment and deception, particularly when students use models to manipulate others. Procurement teams can act now by choosing tools that display identity labels by default in the chat interface and offer a one-tap option for verified human support. Faculty can model best practices in office-hour chatbots and course communities by using clear badges and periodic reminders. These small, visible actions help students adopt a norm: in close conversations, being honest about who—and what—we are is the foundation of care.
The question of which is “worse” has a practical answer. Hidden AI in romance is worse because it strips away consent, invites fraud, and exploits intimacy for profit. Declared AI companions can still pose risks, but the harms are limited by choice and design. Suppose we want a healthier future for dating and connection. In that case, we should create regulations that make disclosure seamless and deceit costly. We must educate people, especially teenagers and young adults, on what an “AI disclosure” looks like and why it is essential. Finally, we should focus on measuring outcomes rather than just announcing features, so platforms that prioritize user protection succeed while those that enable AI chatfishing fall short. The experiments have already demonstrated that machines can impersonate us; the real challenge now is whether we can remain genuine ourselves.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
BusinessWire. (2024, February 6). Bumble Inc. launches Deception Detector™: An AI-powered shield against spam, scam, and fake profiles.
European Commission. (n.d.). AI Act — transparency obligations.
Federal Trade Commission. (2024, February 13). Love stinks—when a scammer is involved.
Harper’s Bazaar. (2025, January 24). How I learned to stop worrying and love the bot.
Jones, C. R., & Bergen, B. K. (2025). Large language models pass the Turing test. arXiv preprint.
LegiScan. (2025). California SB 243 — Companion chatbots (enrolled text).
Match Group & The Kinsey Institute. (2025, June 10). 14th Annual Singles in America study.
Penn State University. (2024, May 14). Q&A: The increasing difficulty of detecting AI versus human.
Scientific American. (2025, October). The rise of AI “chatfishing” in online dating poses a modern Turing test.
Skadden, Arps. (2025, October 13). New California “companion chatbot” law: Disclosure, safety protocol, and reporting requirements.
The Washington Post. (2025, July 3). How AI is impacting online dating and apps.
WHYY. (2025, May 7). Will AI replace human connection?
Wired. (2025, August). Character.AI pivots to AI entertainment; 20M monthly users.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.