Member for
5 months 3 weeksProfessor of AI/Data Science @ SIAI
입력
수정
While founding a university (SIAI), I encountered a surprising reality—university rankings, like any evaluative system, are shaped by more than just academic performance. Factors such as institutional branding, media visibility, and methodological choices play a role in shaping how institutions are perceived and ranked. This has led to ongoing debates about how rankings should be structured and whether certain metrics introduce unintended biases.
Although I still respect world-class newspapers that produce university rankings, I began to wonder: Can we create a ranking system that is free from predefined metrics and reflects real-time public perception? In the age of 'Big Data', where everyone’s opinions contribute to digital landscapes—just as Google’s PageRank algorithm does for web search—shouldn’t rankings be more dynamic, reflecting organic engagement and discussion rather than static formulas?
Google’s search ranking is determined by a webpage’s popularity and its informative potential, both shaped by user behavior. By the same logic, I envisioned a PageRank-like ranking system that extends beyond web search—one that could be applied to any domain, as long as the data is properly structured and the model is well-designed.
Of course, no single index can perfectly capture the true potential of an institution. However, unlike traditional rankings that rely on fixed methodologies and expert-driven criteria, my approach removes human discretion from the equation and mirrors the real-world mechanisms used by the most trusted system in the digital age—Google’s search engine.
At the end of the day, ranking is not static—it evolves continuously. Just as Google updates search results dynamically based on new data and shifting ranking logic, the rankings measured by GIAI follow the same principle. Because our system is based on real-time internet data rather than an annual retrospective dataset, it is inherently more up-to-date, even if it still has many imperfections.

The Challenge of Trustworthy Rankings
From a statistical perspective, ranking is a form of dimensionality reduction, similar to Factor Analysis. Researchers often believe that many observed variables are influenced by a smaller set of hidden variables, called 'factors'. Ranking is, in essence, an attempt to condense multidimensional information into a single index (or a few indices at most), making it conceptually similar to factor analysis.
In fact, this logic is central to SIAI’s education. I teach students that even Deep Neural Networks (DNNs) are multi-stage factor analysis models—each layer extracts hidden factors that were not visible at the earlier stage. The reason we need DNN-based complex factor analysis instead of simple statistical methods is that modern data structures, such as images or unstructured text, require deeper representations.
For ranking, however, I use network data instead of traditional column-based data, which demands a different type of factor analysis technique—one designed for network structures. This means that our ranking methodology is not merely a standard statistical reduction but a network-driven eigenvector centrality approach, akin to Google's search ranking algorithm.
Unfortunately, like all dimensionality reduction methods, this approach has limitations. Some information is inevitably lost in the process, which introduces potential bias into the ranking. Just as Google continuously updates its ranking algorithm to refine search results, we also need to iterate and improve our model to account for distortions that arise from the dimensional reduction process.
In this regard, we admit that our ranking is not definitive replacement of existing ranking services, but a complementary support that established system may have missed.
Quick side tour: How does Google determine page ranking? - PageRank
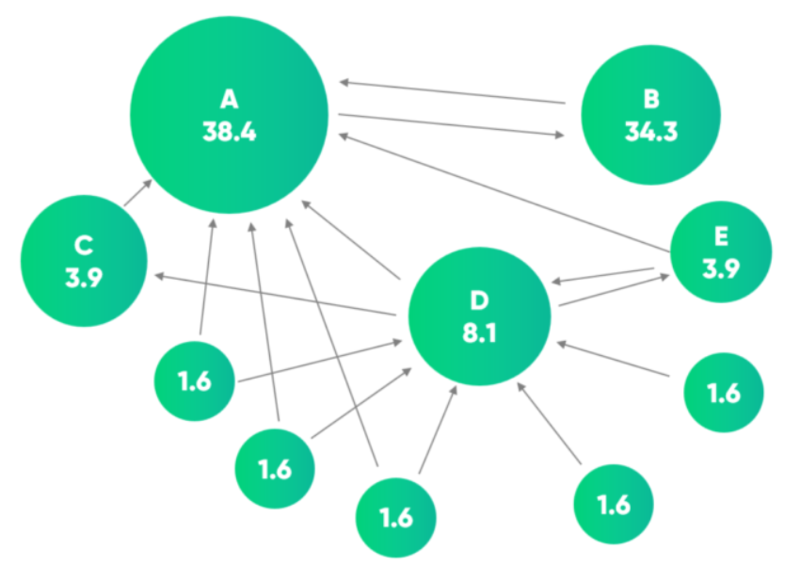
When Google was founded, its revolutionary innovation was PageRank, an algorithm designed to rank web pages based on their importance, rather than just keyword matching. Instead of relying solely on how many times a word appeared on a webpage, PageRank measured how web pages were linked to each other—operating on the principle that important pages tend to be linked to by many other important pages.
PageRank works like a network-based ranking system:
- Every webpage is treated as a node in a network.
- A link from one page to another is considered a vote of confidence.
- Pages that receive more inbound links from high-quality sources receive a higher score.
This approach allowed Google to rank pages based on their structural relevance, rather than just keyword stuffing—a major flaw in early search engines.
PageRank assigns a score to each webpage based on the probability that a random internet user clicking on links will land on that page. This is determined through an iterative formula:
Where:
- $PR(A)$ = PageRank of webpage A
- $d$ = Damping factor (typically set to 0.85 to prevent infinite loops)
- $PR(B)$ = PageRank of a webpage linking to A
- $L(B)$ = Number of outbound links from webpage B
(There can be N(>1) of webpage B, all of which will be summed and weighted by $d$).
Each iteration refines the scores until a stable ranking emerges. This method effectively identifies pages that are central to the web’s information flow.
While PageRank was the foundation of Google Search, it is no longer the sole ranking factor. Over time, Google evolved its algorithm to address manipulation and improve search quality. Some key developments include:
✅ Link Quality Over Quantity: Google penalized spammy, low-quality link-building tactics that artificially boosted PageRank.
✅ Personalization & Context Awareness: Google now considers user search history, location, and device to tailor results.
✅ RankBrain (2015): An AI-based ranking system that understands semantic relationships rather than just word matching.
✅ BERT & MUM (2019-Present): Advanced natural language models that improve the understanding of complex queries and intent.
Even though PageRank is no longer Google’s sole ranking mechanism, its core logic—using network-based ranking rather than static indicators—still drives how web relevance is determined.
So, in theory, Google’s PageRank algorithm and GIAI's ranking model share the same fundamental principle: Ranking entities based on their structural position in a network, rather than relying on arbitrary human-defined scores. The difference lies in:
- Google ranks web pages, whereas I rank companies, universities, or movies based on word-of-mouth networks.
- Google uses hyperlinks between pages, while I use word associations in discussions and media coverage.
- Google refines its ranking with AI models like RankBrain; I adjust weights based on time sensitivity and data source credibility.
By following this well-established methodology, my ranking system is not arbitrary or subjective—it is grounded in the same kind of network-based analysis that transformed the internet into an organized and searchable knowledge system.
Potential risks in the 'word of mouth' based ranking model
1. The Impact of Sarcasm and Irony
One of the greatest challenges in natural language processing (NLP) is distinguishing between genuine praise and sarcastic remarks. While humans can easily identify irony in statements like:
- "Oh wow, another groundbreaking innovation from this company…" (actually expressing frustration)
- "This is the best movie ever. I totally didn't fall asleep halfway through." (obvious sarcasm)
A text-based ranking model, however, may interpret these statements as positive sentiment, artificially boosting an entity’s score.
Why It’s Hard to Fix:
- Traditional sentiment analysis models rely on word-based classification, which struggles with sarcasm.
- Even advanced contextual models (e.g., BERT, GPT) require massive amounts of labeled sarcastic text for accurate detection.
- Sarcasm often lacks explicit markers, making it difficult to distinguish from genuine praise without deep contextual understanding.
2. Bias in Data Sources
Text-based rankings are only as good as the data they rely on. The internet is filled with skewed sources, and the way an entity is discussed can vary wildly depending on where the data is collected from:
- Twitter & Social Media: Driven by trends, memes, and emotional reactions, often amplifying sensational or controversial entities.
- News Articles: More structured but still prone to corporate PR influence and selective coverage.
- Online Forums (e.g., Reddit, community discussions): Stronger opinions, but highly demographic-dependent.
Why It’s Hard to Fix:
- No single dataset represents a true public opinion.
- Weighting sources automatically requires carefully tuned bias adjustments.
- Some entities get more exposure due to media agendas, not true popularity.
3. Viral Manipulation and Astroturfing
In the age of social media brigades and fake engagement, ranking models can be gamed. Some common tactics include:
- Comment spam: Fake positive or negative comments posted in bulk to shift rankings.
- Mass upvotes/downvotes: Platforms like Reddit allow coordinated actions to promote or suppress certain views.
- Corporate PR campaigns: Artificially boosting positive discussion or suppressing negative narratives.
Why It’s Hard to Fix:
- Many manipulation attempts look organic, making them hard to detect algorithmically.
- Tracking IP origins and user patterns is outside the scope of text-based ranking.
- Real engagement can resemble manipulation, making it difficult to separate genuine sentiment shifts from artificial ones.
4. Time-Sensitivity Issues
Public sentiment isn’t static—entities gain and lose popularity rapidly. A ranking system based on static text analysis may fail to capture recent shifts, such as:
- A scandal that rapidly deteriorates a company’s reputation.
- A viral moment that temporarily inflates a movie’s ranking.
- A forgotten entity that suddenly resurfaces.
Why It’s Hard to Fix:
- Adjusting for recency bias can distort historical credibility.
- Short-term spikes in attention don’t always indicate long-term influence.
- Handling time-weighted ranking adjustments requires constant recalibration.
What This Means for GIAI's Ranking Model
Despite my best efforts, a purely text-based ranking will never be fully trustworthy—not because of a flaw in the methodology, but because language itself is unpredictable, biased, and easily manipulated. While I have built automatic weight-adjusting mechanisms to counteract some of these issues, certain biases remain:
✅ Strong at identifying entity prominence: If an entity is widely discussed, my model captures it well.
✅ Good at detecting discussion clusters: My eigenvector-based approach ensures ranking reflects influence rather than just raw frequency.
⚠️ Vulnerable to sarcasm and manipulation: Without deeper NLP work, sarcasm and fake engagement can skew results.
⚠️ Sensitive to source biases: Ranking outcomes depend on where the data comes from.
⚠️ Time-dependent accuracy issues: Spikes in discussion may create misleading rankings if not adjusted correctly.
Moving forward, one potential improvement is to overlay sentiment adjustments carefully, ensuring that rankings are influenced but not dictated by sentiment. However, I will remain cautious about over-engineering the model—sometimes, allowing raw data to speak for itself is more honest than trying to force it into artificial classifications.
At the end of the day, no ranking system is perfect. But by understanding its flaws, we can interpret the results more intelligently, rather than assuming any model has a monopoly on truth.
Member for
5 months 3 weeksProfessor of AI/Data Science @ SIAI