No Reset: Takaichi’s First Moves Lock In the New Normal of Japan-China Relations
Japan’s new PM locks in a hard-line, US-aligned stance Japan–China ties enter “stable instability” as ASEAN/Seoul outreach continues Schools and policymakers must harden compliance and diversify partnerships
 <
<
China Climate Leadership After Paris: Why 7 to 10 Percent by 2035 Can Be a Floor
China’s clean-energy surge makes the 7–10% by 2035 a floor, not a ceiling Wind, solar, and EV scale are bending emissions down despite coal capacity With the U.S.
Market-Based Inflation Predictor: How Education Can Budget Smarter with Markets and News
Markets provide the fastest, most reliable signal of expected inflation Pairing market prices with news-based textual indicators improves shock classification and timing Education systems should anchor wages and procurement to this dashboard with simple, rules-based triggers

Generative AI for Older Adults: Lessons from the Internet Age
Generative AI for Older Adults: Lessons from the Internet Age

David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Published
Modified
Older adults are missing out on generative AI Used well, it can boost independence and wellbeing Policy must make these tools senior-friendly

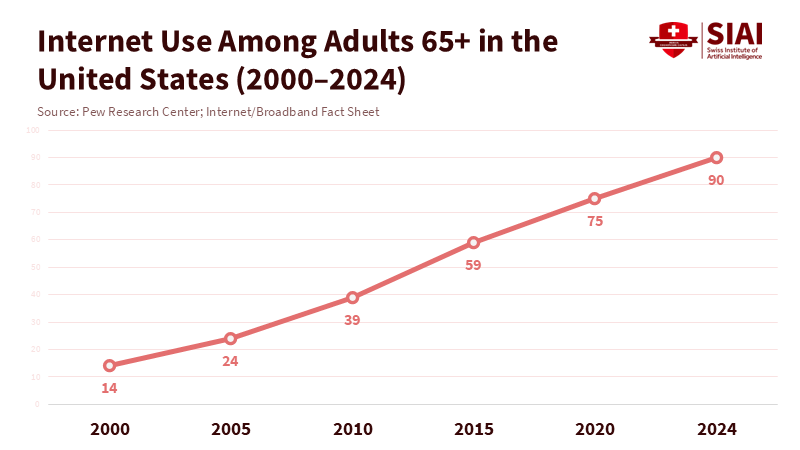
In 2000, only 14% of Americans aged 65 and older were online. By 2024, that number had risen to 90%. This shift is so significant that it's easy to forget how unfamiliar the internet once seemed to older adults. Today, many people in this age group video call their grandchildren, manage their bank accounts on smartphones, and consider YouTube their main TV channel. However, when we transition from browsing the web to using large language models, we see a regression. By mid-2025, only 10% of Americans aged 65 and older had ever used ChatGPT, compared with 58% of adults under 30. Data from Italy shows a similar trend: while three-quarters of adults are aware of generative AI, regular use remains concentrated among younger, more educated people. Generative AI for older adults is now in a position similar to the internet at the turn of the century: visible and popular, but mostly overlooked by seniors.
Most discussions of this gap view it as a job-market issue. Evidence from Italian household surveys indicates that using generative AI is linked to a 1.8% to 2.2% increase in earnings, about half a year's worth of additional schooling, and one-tenth of the wage benefit seen with basic computer use in the 1990s. From this perspective, younger, tech-savvy workers benefit first while older workers fall behind. While this interpretation isn’t wrong, it is limited. For those in their 60s and 70s, generative AI is less about income and more about independence, health, and social connections. The better comparison isn't early spreadsheets or email, but how the internet and smartphones changed well-being in later life once they became accessible and valuable. If we overlook this comparison, we risk repeating a 20-year delay that older adults cannot afford.
Generative AI for Older Adults and the New Adoption Gap
Recent Italian survey data highlight how significantly age influences the use of these tools. In April 2024, 75.6% of Italians aged 18 to 75 reported awareness of generative AI tools like ChatGPT, yet only 36.7% had used them at least once in the past year, and just 20.1% were monthly users. Age and education create a clear divide: adults aged 18 to 34 were 11 percentage points more likely to know about generative AI than those 65 and older, and among those aware of it, they were 30 percentage points more likely to use it. These are significant differences that reflect well-documented patterns in the "digital divide," where older adults see fewer benefits from new technologies and face steeper learning curves and greater perceived risks. Consequently, generative AI for older adults exists, but it is mostly outside their everyday activities.
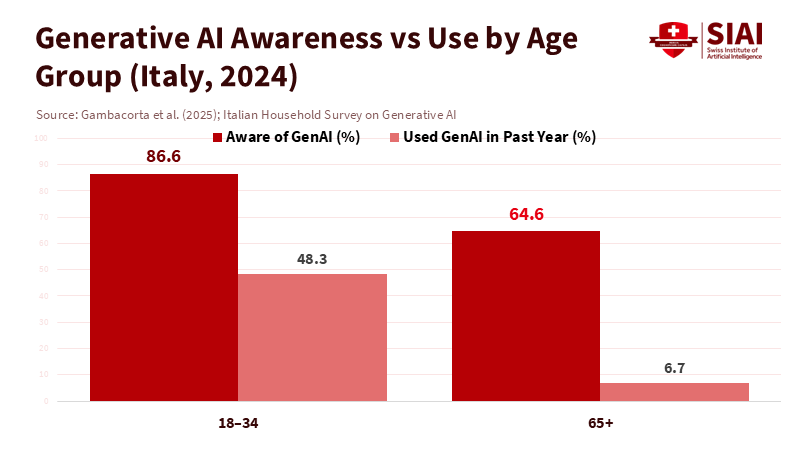
Evidence from other countries shows that Italy is not an anomaly. A module in the U.S. Federal Reserve’s Survey of Consumer Expectations finds that awareness of generative AI now exceeds 80% among adults. Usage rates are slightly higher than those in Italy, but the same pronounced divides by age, education, and gender persist. Pew Research Center estimates that by June 2025, 34% of U.S. adults had used ChatGPT. The difference by age is stark: 58% of adults under 30 compared to 25% of those aged 50 to 64 and just 10% of those 65 and older. Across the EU, the Commission’s Joint Research Centre reports that about 30% of workers now use some form of AI, with adoption highest among younger, better-educated groups. Generative AI for older adults is thus developing within a framework of established digital inequality: seniors have achieved near-universal internet access. Still, they are once again marginalized by a new general-purpose technology.
This situation would be less concerning if the gains from adoption were solely financial. Estimates from Italy suggest that generative AI use provides only a modest earnings boost, much smaller than the benefits received from basic computer skills during the early computer age. Yet older adults interact with health systems, social services, and financial providers that are quickly integrating AI. If generative AI for older adults remains uncommon, the risk extends beyond reduced income; it also includes diminished ability to navigate services influenced by algorithms. The Italian data highlight another vital aspect: social engagement strongly predicts the use of generative AI, even after considering education and income. This finding mirrors decades of research on the internet, where social connections and perceived usefulness determine whether late adopters continue to use these tools. Understanding generative AI through this perspective is crucial, as it shifts the focus from “teaching seniors to code with chatbots” to integrating these technologies into the social and service settings they trust, thereby illuminating the true potential of AI for older adults.
What the Internet Era Taught Us About Late-Life Technology Adoption
The history of the web and smartphones illustrates how quickly older adults can close a gap once technologies become simpler and more relevant. In the United States, only 14% of those 65 and older used the internet in 2000; by 2024, that number reached 90%, just nine percentage points lower than the youngest age group. Home broadband and smartphone ownership reflect a similar trend: as of 2021, 61% of people aged 65 and older owned a smartphone, and 64% had broadband at home, up from single-digit levels in the mid-2000s. Even YouTube—a platform initially considered for teenagers—has seen use grow among older adults, with the percentage of Americans aged 65 and older using it rising from 38% to 49% between 2019 and 2021. In other words, older adults did not grow up digital. Still, once devices became touch-based, constantly connected, and integrated into social life, they underwent large-scale adaptation.
This access brought about not just convenience but also improved well-being. A study of adults aged 50 and older found that using the internet for communication, information, practical tasks, and leisure positively affected life satisfaction and, in terms of task performance and leisure, negatively correlated with symptoms of depression. An analysis of older Japanese adults revealed that frequent internet users enjoyed better physical and cognitive health, stronger social connections, and healthier behaviors than those who didn't use the internet, even after controlling for initial differences. Studies in England and other aging societies also show a link between regular internet use among seniors and higher quality-of-life scores. Overall, this research suggests that when older adults successfully incorporate digital tools into their daily lives, they often experience greater autonomy, social ties, and psychological resilience.
However, the evidence cautions against being overly optimistic. A recent quantitative study of older adults in a European country, using European Social Survey data, found that daily internet use is negatively associated with self-reported happiness, even while it is positively related to social life indicators. A 2025 analysis from China described a "dark side," noting that internet use is associated with improved overall subjective well-being. Still, it also creates new vulnerabilities, with hope being a key psychological factor. The takeaway isn't that older adults should disconnect; rather, it is about the intensity and purpose of their digital interactions. Well-designed tools that foster communication, meaningful learning, and practical problem-solving tend to enhance late-life well-being. In contrast, aimless browsing and exposure to scams or misinformation do not have the same effect. Generative AI for older adults will follow this same trend unless it is thoughtfully created and regulated.
Designing Generative AI for Older Adults as a Well-Being Tool
Suppose we view generative AI for older adults as an extension of digital infrastructure. In that case, its most impactful uses will be straightforward and practical. Older adults already interact with AI-driven systems when seeking public benefits, scheduling medical appointments, or navigating banking apps. Conversational agents based on large language models could transform these interactions into two-way support: breaking down forms into simple language, drafting letters to landlords or insurers, or helping prepare questions for doctors. Research on health and wellness chatbots shows that older adults are willing to use them for medication reminders, lifestyle coaching, and appointment help if the interfaces are user-friendly and trust is established over time. Early qualitative studies indicate seniors appreciate chatbots that are patient, non-judgmental, and aware of local context—not those filled with jargon or pushy prompts.
Labor market evidence suggests that the most significant benefit of generative AI for older adults may not be financial. Data from Italian households reveal that the earning boost associated with generative AI use is real but modest. For retirees or those nearing retirement, this boost may not matter. What is crucial is whether these tools can help maintain independence—allowing someone to stay in their home longer, manage a chronic condition more effectively, or remain active in community groups. Findings from England’s longitudinal aging study and similar research suggest that using the internet for communication and information improves quality of life and reduces loneliness among older adults. A growing body of research indicates that AI companions and assistants can help combat isolation. However, the quality of this evidence varies. Suppose generative AI for older adults can focus on these high-value functions. In that case, its social benefits may significantly outweigh its direct economic contributions.
Design decisions will shape this future. Surveys show that around 60% of Americans aged 65 and older have serious concerns about the integration of AI into everyday products and services. Classes offered by organizations like Senior Planet in the United States highlight this: participants are eager to learn, but they worry about scams, misinformation, and hidden data collection. For generative AI for older adults, "accessible design" has at least three aspects. First, interfaces must accommodate slow typing, hearing, or vision impairments, and interruptions; voice input and clear visual feedback can help. Second, safety features—such as prompts about scams, easy-to-follow source links, and skepticism regarding financial or health claims—should be built into the systems rather than added later. Third, tailoring matters: advice on pensions, care systems, or tenant rights must be specific to national regulations, not generic templates. Each of these elements lessens cognitive load and increases the chances that older adults will see AI as helpful rather than threatening.
Policy for Inclusive Generative AI for Older Adults
The European Union’s "Digital Decade" strategy aims to ensure that 80% of adults have at least basic digital skills by 2030. This goal should now expand to include proficiency in using generative AI to enhance well-being rather than detract from it. The most effective delivery channels are those already trusted by seniors. Public libraries, community centers, trade unions, and universities for older adults can host short, practical workshops where participants practice asking chatbots to rewrite scam emails, summarize medical documents, or generate questions for consultations. In Italy and other aging societies, adult education programs can pair tech-savvy students with older learners to explore AI tools together, turning social engagement—already a key factor in adoption—into a foundational design principle. Importantly, this training should not be framed as a crash course in “future-proofing your CV,” but as a toolkit for engaging with public services, managing finances, and maintaining social connections.
Governments and regulators also play a role in shaping the market for generative AI for older adults. Health and welfare agencies can create “public option” chatbots that provide answers based on verified information and acknowledge uncertainty, rather than pushing older adults toward less transparent private tools. Consumer protection authorities can mandate that AI systems used in pension advice, insurance, or credit scoring provide accessible explanations and clear appeal paths. Given the established links between internet use and better subjective well-being in later life, the onus should be on providers to demonstrate that their tools do not systematically mislead or exploit older users. Labor market policy is also essential. As AI becomes integrated into workplace software, employers should offer targeted training for older workers, recognizing that even modest earnings gains from generative AI can help extend productive careers for those who want to continue working.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Aldasoro, I., Armantier, O., Doerr, S., Gambacorta, L., & Oliviero, T. (2024a). The gen AI gender gap. Economics Letters, 241, 111814.
Aldasoro, I., Armantier, O., Doerr, S., Gambacorta, L., & Oliviero, T. (2024b). Survey evidence of gen AI and households: Job prospects amid trust concerns. BIS Bulletin, 86.
Bick, A., Blandin, A., & Deming, D. (2024). The rapid adoption of generative AI. VoxEU.
European Commission. (2025). Impact of digitalisation: 30% of EU workers use AI. Joint Research Centre.
Gambacorta, L., Jappelli, T., & Oliviero, T. (2025). Generative AI: Uneven adoption, labour market returns, and policy implications. VoxEU.
Lifshitz, R., Nimrod, G., & Bachner, Y. G. (2018). Internet use and well-being in later life: A functional approach. Aging & Mental Health, 22(1), 85–91.
Nakagomi, A., Shiba, K., Kawachi, I., et al. (2022). Internet use and subsequent health and well-being in older adults: An outcome-wide analysis. Computers in Human Behavior, 130, 107156.
Pew Research Center. (2022). Share of those 65 and older who are tech users has grown in the past decade.
Pew Research Center. (2024). Internet/Broadband Fact Sheet.
Pew Research Center. (2025). 34% of U.S. adults have used ChatGPT, about double the share in 2023.
Suárez-Álvarez, A., & Vicente, M. R. (2023). Going “beyond the GDP” in the digital economy: Exploring the relationship between internet use and well-being in Spain. Humanities and Social Sciences Communications, 10(1), 582.
Suárez-Álvarez, A., & Vicente, M. R. (2025). Internet use and the Well-Being of the Elders: A quantitative study in an aged country. Social Indicators Research, 176(3), 1121–1135.
Washington Post. (2025, August 19). How America’s seniors are confronting the dizzying world of AI.
Yu, S., et al. (2024). Understanding older adults’ acceptance of chatbots in health contexts. International Journal of Human–Computer Interaction.
Zhang, D., et al. (2025). The dark side of the association between internet use and subjective well-being among older adults. BMC Geriatrics.
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.

















Rethinking Household Risk: Why the Interest Coverage Ratio, Not DTI, Should Guide Policy
DTI misreads risk; it ignores cash-flow strain Sweden shows the interest coverage ratio tracks stress while assets preserve solvency Center policy and education on ICR, use counter-cyclical amortization, and curb high-cost credit

Building an ASEAN Regional Stability Fund for the Next Crisis
ASEAN needs its own stability fund to protect trade during crises Europe shows that regional firewalls boost confidence An ASEAN-led design would secure faster, fairer support

Central Banks Cannot Fix Broken Pipelines: Rethinking Monetary Policy for Supply Shock Inflation
Supply shock inflation comes from real shortages that rates cannot fix Central banks can limit spillovers, but fiscal and structural tools must absorb the shock Inflation control is a shared task.

When European gas prices s
Digital bank runs and loss-absorbing capacity: why mid-sized banks need bigger buffers
Digital bank runs and loss-absorbing capacity: why mid-sized banks need bigger buffers

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
Digital bank runs can drain banks in hours, outpacing current LAC rules. Raise LAC for mid-sized, high-digital banks using uninsured-deposit and network metrics AI-amplified rumors heighten correlation, so stress tests and resolution must run on 24-hour clocks

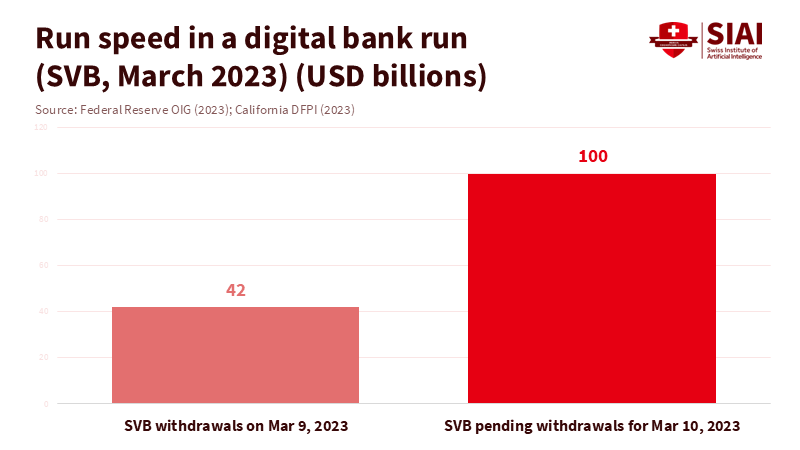
In March 2023, a single U.S. bank experienced a staggering $42 billion in customer withdrawals in just one trading day, representing a quarter of its total funding. The following morning, another $100 billion was poised to leave. Regulators had no time for a weekend rescue. The balance sheet, which would typically be dismantled over weeks, was emptied in a matter of hours. This alarming scenario is the new reality of digital bank runs. The rapid evolution of mobile banking, social media, and concentrated corporate depositors can transform mere rumors into full-blown funding crises almost instantly. However, our primary safety tool—loss-absorbing capacity (LAC) for resolution—still reflects a time of slower runs and primarily focuses on the largest global banks. If LAC is to shield the real economy from chaotic failures effectively, it must be recalibrated to match the speed and structure of digital panic. Buffers for mid-sized, digitally intensive banks must be increased and explicitly calibrated to the risk of digital bank runs, rather than being treated as an afterthought.
Digital bank runs and loss-absorbing capacity
Over the last decade, major regions have established resolution systems so that large banks can fail without disrupting the wider system or requiring taxpayer bailouts. The most prominent international institutions are subject to a common minimum standard for total loss-absorbing capacity (TLAC). This standard is designed to ensure that there is enough bail-in debt and capital to cover losses and restore a viable entity during resolution. For other systemic banks, the rules are more fragmented. A recent analysis by the Bank for International Settlements shows that while many countries now apply LAC-style rules to significant domestic banks, there is no uniform global baseline, and the standards vary widely. That variety might have been acceptable in a world of slow, queue-based runs. It seems much less reassuring after a funding shock that wiped out tens of billions within hours.
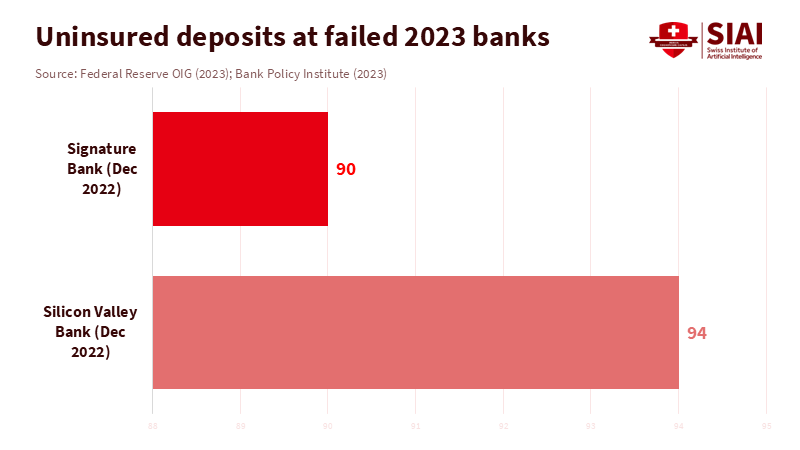
The turmoil of 2023 revealed how digital bank runs can turn mid-sized lenders into systemic threats on a new timeline. At Silicon Valley Bank, $42 billion in deposits were left on March 9, 2023, and requests for another $100 billion appeared overnight. First Republic then lost more than $100 billion in deposits in a single quarter as confidence vanished. Research using detailed social media data indicates that banks with high Twitter exposure lost more market value and experienced greater outflows of uninsured deposits during this period, even after accounting for balance-sheet risks. Observers have accurately labeled these events as digital bank runs, fueled by instant transfers and intense online scrutiny. However, LAC frameworks still tend to treat mid-sized banks as locally significant but manageable with modest buffers. The disconnect is apparent: resolution plans assume time and funding that digital bank runs no longer allow.
Measuring digital systemicity beyond size-based LAC
The main lesson from these cases is straightforward. Systemic importance is no longer determined solely by size, cross-border activity, or complexity. It is also about how quickly a bank can lose funding when narratives shift. Digital bank runs occur at the intersection of three features: large amounts of uninsured deposits, intense social media focus, and seamless digital channels. Research on the 2023 U.S. banking stress finds that banks with high Twitter exposure experienced equity losses about 6 to 7 percentage points higher than their peers.
Additionally, message volume predicted intraday losses and uninsured outflows. Central bank commentary supports similar conclusions: the Banque de France notes that digitalization and social networks worsened the Silicon Valley Bank run by making it easier to move uninsured deposits and spread panic. This means that the relevant funding profile now is not just "wholesale versus retail"; it also concerns how networked, uninsured, and mobile those funds are.
LAC policy must adapt to these changes. Instead of treating mid-sized banks as a uniform group that can maintain a thin layer of bail-inable instruments, supervisors should introduce a 'digital systemicity' factor when determining minimum LAC. This factor can utilize data already collected: the share of uninsured deposits, the proportion of funding from large corporate or venture networks, the use of instant payment channels, and fundamental indicators of a bank's public digital presence. While none of these metrics is perfect, together they can highlight where digital bank runs are most likely to happen quickly and in a coordinated manner. Where digital systemicity is high, LAC floors should be closer to those set for the largest banks, even if their total assets are lower. Recent work from global standard-setters already emphasizes the need to tailor LAC for non-global systemic banks; the next step is to integrate digital run risk into that calibration rather than treat it as an afterthought.
AI-driven contagion and the new calibration challenge
The risk landscape is shifting even more as artificial intelligence becomes central to information production and decision-making. A 2025 study in the UK on AI-generated misinformation finds that false but believable content about a bank's condition, spread through targeted social media ads, significantly increases the number of customers likely to move their money. The authors estimate that in some cases, £10 in ad spend could influence up to £1 million in deposits. The Financial Stability Board's 2024 evaluation of AI warns that generative models can amplify misinformation and help malicious actors trigger "acute crises," including bank runs, by lowering the cost of generating convincing narratives at scale. In simpler terms, creating the spark for digital bank runs is becoming cheaper, faster, and harder to monitor.
Simultaneously, the infrastructure that supports financial AI is highly concentrated. By mid-2025, the three largest cloud providers controlled about two-thirds of the global cloud infrastructure market. Many banks and market utilities now run their AI models on the same providers and tools. Supervisory studies on AI in finance highlight vendor concentration, herding, and limited visibility as significant sources of concern for financial stability. These trends matter for LAC because they increase the likelihood that many institutions will react to the same rumor in the same way at the same time. When AI systems promote and rank similar content across platforms, a piece of false news does not just reach one bank's clients; it hits overlapping communities of depositors within minutes. Thus, digital bank runs become more correlated among institutions, including mid-sized lenders that were never deemed 'systemically important' in the traditional sense. If LAC calibration overlooks this, it will be too low exactly where AI-driven contagion makes failure most disruptive. A more comprehensive approach to LAC calibration is needed to account for these new challenges.
Some argue that increasing LAC for a broader range of banks is too expensive and that better supervision or liquidity rules should manage digital stress. There is a cost: bail-inable debt is not free, and spreads may rise. However, post-crisis studies on stronger capital requirements suggest that the long-term impact on credit and growth is small compared to the benefits of reduced crisis risk. Moreover, LAC targeted at digital systemicity can be detailed. Banks with low uninsured deposits and limited digital reach would not see significant increases. Those with concentrated, mobile funding and a heavy reliance on public platforms would need larger buffers to account for the higher risks they entail. Liquidity support and supervision remain essential, but they cannot replace the need for readily available loss-absorbing resources when digital bank runs and AI-fueled narratives expose weaknesses in hours instead of days.
What must educators and regulators do now?
For regulators, the first step is theoretical. LAC should be viewed as a tool to manage digital coordination risk, not merely as a means of absorbing balance-sheet losses. This means integrating indicators of digital bank runs into both the scope and calibration of LAC. Authorities can begin by requiring banks with a certain level of digital systemicity to hold a higher minimum LAC, with a clear phase-in and rationale. Stress tests should consider run speeds similar to those seen in 2023, when a quarter of deposits can vanish in a day, and model shocks from AI-driven misinformation rather than just interest-rate or credit shocks. Resolution plans must also be quicker. Bail-in guidelines, communication plans, and temporary liquidity support mechanisms must be ready for execution around the clock, not just during a quiet weekend.
Educators and administrators also play an essential role. Programs in finance, law, data science, and public policy should now include digital bank runs as a regular topic, not just a niche study. Students preparing for roles in treasuries, central banks, or supervisory agencies need to analyze the 2023 events with real numbers: how deposit structures, social networks, and rumors combined to overwhelm existing buffers. Courses can integrate simple models that connect LAC levels to run speed and digital exposure, illustrating how additional bail-in debt impacts the options available to resolution authorities during stress. Cross-disciplinary modules that connect technology, psychology, and regulation—drawing on recent legal and economic analyses of bank runs in the digital age—will help future decision-makers understand why narrative dynamics are now at the center of discussions of stability.
The conclusion follows from the figure mentioned at the start. When $42 billion can exit a bank in one day and another $100 billion is lined up for the next, we are not facing a rare shock. We are observing the normal pace of panic in a world of digital bank runs and AI-driven information. LAC rules that disregard this reality are, by design, miscalibrated. Increasing buffers for mid-sized and digitally intensive banks is not about punishment; it is about acknowledging their new systemic impact and providing resolution tools with enough resources to function. If regulators adjust LAC with digital systemicity in mind, if banks accept that higher loss-absorbing capacity is the cost of operating in a hyper-connected market, and if educators prepare the next generation to think in these terms, the next digital run need not lead to a scramble for extraordinary support. The choice is clear: enhance LAC for our current world, or keep relying on safeguards built for a slower crisis that no longer exists.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bank for International Settlements – Financial Stability Institute. (2025). Loss-absorbing capacity requirements for resolution: beyond G-SIBs (FSI Insights No. 69). Bank for International Settlements.
Bank for International Settlements – Financial Stability Institute. (2024). Regulating AI in the financial sector: recent developments and main challenges (FSI Insights No. 63). Bank for International Settlements.
Banque de France. (2024). Digitalisation – a potential factor in accelerating bank runs? Bloc-notes Éco, Post 382.
Beunza, D. (2023). Digital bank runs: social media played a role in recent financial failures, but could also help investors avoid panic. The Conversation.
Cookson, J. A., Fox, C., Gil-Bazo, J., Imbet, J. F., & Schiller, C. (2023). Social Media as a Bank Run Catalyst (working paper). Federal Deposit Insurance Corporation / Banque de France.
Financial Stability Board. (2024). The financial stability implications of artificial intelligence. Financial Stability Board.
Fortune. (2023, March 11). $42 billion in one day: SVB bank run biggest in more than a decade.
Ofir, M., & Elmakiess, T. (2025). Bank runs in the digital era: technology, psychology and regulation. Oxford Business Law Blog (blog summary of forthcoming law review article).
Reuters. (2023, April 24). First Republic Bank deposits tumble more than $100 billion in the first quarter.
Reuters. (2025, February 14). AI-generated content raises risks of more bank runs, UK study shows.
SIAI – McGowan, E. (2025). From model risk to market design: why AI financial stability needs systemic guardrails. Swiss Institute of Artificial Intelligence Memo Series.
U.S. Federal Reserve Board Office of Inspector General. (2023). Material loss review of Silicon Valley Bank, Santa Clara, California.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Counting the Global Welfare Loss from Chinese Subsidies
Chinese subsidies lower prices now but create domestic misallocation and cross-border distortions Importers’ short-run gains are offset by capacity loss, concentration, and volatile input shocks Targeted remedies, resilient procurement, and updated curricula can cut the global welfare loss

The Real Economics of Workweek Productivity
Shorter hours raise workweek productivity only where overwork and waste are high Denmark shows pay falls when hours drop without real efficiency gains Cut low-value tasks and add smart AI, then trim hours in burnout hotspots
