Digital Mercantilism in Education Markets: What the U.S.-Korea Platform Clash Teaches Schools
Digital mercantilism drives the U.S.–Korea platform fight in schools Make access reciprocal, data portable, and impact proven Treat ed-tech buying as trade policy to protect learning and competition

CBDC Privacy and Monetary Sovereignty: Why Rules, Not Code, Will Decide Adoption
CBDC privacy decides whether people will use digital cash Most countries want CBDCs for sovereignty; the U.S.
Europe's New Defence Bill Can't Come Out of the Classroom
Europe may move to 5% defence Use EU bonds, cut weak subsidies, and buy jointly Ring-fence education and expand skills
Europe is being asked to plan defence spending at 5% of GDP.
SEC-CFTC Harmonization Now, Merger Later: A Risk-Tiered Path for Digital
SEC–CFTC harmonization now; no immediate merger Use a risk-tiered model while stablecoin rules cover payment risks Merge only if regulated payment stablecoins dominate activity and definitions converge

Stop Chasing Followers: Social Network Bridging Is the Real Power in Education
Social network bridging beats raw reach for lasting influence in education Bridges and weak ties move jobs, ideas, and credible signals across clusters faster than hubs Name brokers, track cross-cluster reach, and build routines that link communities

AI Readiness in Financial Supervision: Why Central Banks Move at Different Speeds
AI Readiness in Financial Supervision: Why Central Banks Move at Different Speeds

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
AI readiness in financial supervision decides who adopts fast and who falls behind In 2024, only 19% used generative tools, with advanced economies far ahea Fund data and governance, scale proven pilots, and measure real outcomes

Only one number frames the debate: nineteen. In 2024, about 19% of countries were using generative AI tools in financial supervision, up from 8% the previous year. The trend is clear. Jurisdictions with better skills, data, and governance frameworks move faster and further; those without these resources fall behind. The result is not just a technology gap; it is a readiness gap linked to income levels and government capacity. In advanced economies, supervisory AI relies on robust data pipelines and model risk rules. In many other parts of the world, limited computing power, weak data, and small talent pools delay adoption and increase risk. If we want AI to improve oversight everywhere—not just where the infrastructure is already in place—we need to treat “AI readiness in financial supervision” as a public good, measure it, and fund it with the same focus we give to capital and liquidity rules.
AI readiness in financial supervision is the new capacity constraint
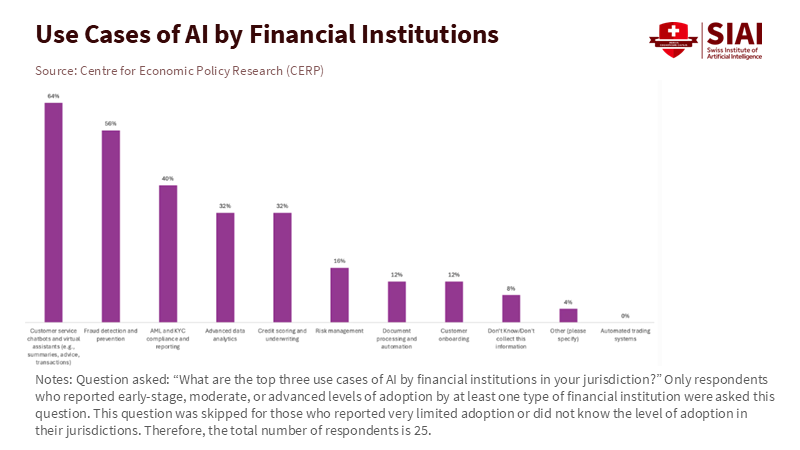
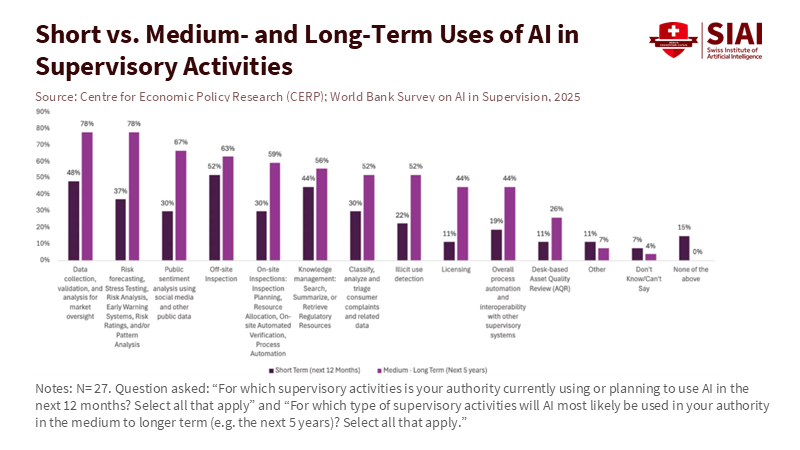
The global picture is inconsistent. By 2024, three out of four financial authorities in advanced economies had deployed some form of supervisory technology. In emerging and developing economies, that figure was 58%. Most authorities still depend on descriptive analytics and manual processes, but interest in more advanced tools is growing rapidly. A recent survey found that 32 of 42 authorities are using, testing, or developing generative AI; around 60% are exploring how to incorporate AI into key supervisory workflows. Still, the proportion of countries using generative tools in supervision stood at just 19% in 2024. Adoption is happening, but readiness remains the primary constraint.
Broader government capability metrics tell the same story. The 2024 Government AI Readiness Index puts the global average at 47.59. Western Europe averages 69.56, while Sub-Saharan Africa averages 32.70. The United States leads overall, yet Singapore excels in the “Government” and “Data & Infrastructure” pillars—the essential foundations supervisors need. These rankings are not just for show; they indicate whether supervisory teams can build data pipelines, manage third-party risk, and validate models effectively. Where these pillars are weak, projects stall, and regulators stick to manual reviews. Where they are strong, supervisors can adopt safer and more understandable systems and use them in daily practice.
What the data say in 2023–2025
Recent findings from regulators in emerging and developing economies confirm the existence of a readiness gap. Most authorities are still in the early stages of using AI for core tasks like data collection, off-site inspections, and anomaly detection. Basic generative tools are standard for drafting and summarizing, but structured uses for supervision are rare. Only about a quarter of surveyed authorities report having a formal internal AI policy today; in Africa, this share is closer to one-fifth, though many plan to implement policies within a year. The main barriers are clear: data privacy and security, gaps in internal skills, concerns about model risk and explainability, and the challenge of integrating AI into old systems. These are the same issues that readiness indices highlight.
Complementary BIS survey work shows how processes and culture widen the divide. In 2023, 50 authorities from 45 jurisdictions shared insights on their “suptech” activities. Only three had no initiatives at all, but the types of activities varied greatly by income level. Authorities in advanced economies were about twice as likely to host hackathons and collaborate across agencies. Most authorities still develop tools in-house, but the use of open-source environments is low, especially in emerging markets. This matters. Collaboration and open tools reduce costs and speed up learning; their absence forces each authority to start from scratch. The issue is not a lack of ambition in emerging markets. It’s that readiness—skills, processes, and governance—determines the pace.
Risk is another important factor. Supervisors are right to be cautious. The Financial Stability Board warns that generative AI introduces new vulnerabilities: model hallucinations, which are instances where the AI model generates incorrect or misleading data; third-party concentration, cyber risk, and pro-cyclical trends if many firms use similar models. The report’s message is cautious but significant: many vulnerabilities fall within existing policy frameworks, but authorities need better data, stronger model risk governance, and international coordination to keep up. Supervisory adoption cannot overlook these constraints; it must incorporate them from the beginning.
Closing the gap: from pilots to platforms
The first task for authorities with low readiness is not to launch many AI projects. It is to turn one or two valuable pilots into shared platforms. Start with problems where AI truly helps, not just impresses. Fraud detection in payment data, complaint triage, and entity resolution across fragmented registries are good areas to focus on. They utilize data the authority already collects, deliver clear benefits, and strengthen core capabilities—data governance, MLOps, and model validation—that future projects can also use. This is how the most successful supervisors transition from manual spreadsheets to reliable pipelines. It is also how they build trust. Users prefer tools that reduce tedious work and provide results they can easily explain.
Financing and procurement must support this approach. Smaller authorities cannot cover the fixed costs of computing and tools on their own. Regional cloud services with strong data controls, pooled purchases for red-teaming and bias testing, and code-sharing among peers lower entry costs and improve quality. The BIS survey shows strong demand for knowledge sharing and co-development; we should respond with practical solutions. For example, we can standardize data formats for supervisory reports and publish reference implementations for data ingestion and validation. Another approach is to fund open, audited libraries for risk scoring that smaller authorities can build on. These are public goods that maximize limited budgets and enhance safety.
Standards, safeguards, and measuring what matters
Rules and metrics determine whether AI is beneficial or harmful. Authorities need three safeguards before any model impacts supervisory decisions. First, a clear model-risk policy that aligns materiality with explainability. Low-impact tools can utilize opaque methods with strong oversight; high-impact tools must offer understandable results or be paired with robust challenger models. Second, strict third-party risk controls should be in place from procurement to decommissioning. Many jurisdictions will depend on external models and systems; contracts must address data rights, incident reporting, and exit strategies. Third, disciplined deployment: maintain an active inventory of models, log decisions, and monitor changes with documented re-training. The goal is simple: keep human judgment involved and ensure the technology is auditable.
Measurement should go beyond counting pilots. We should track the time to inspection, reporting backlogs, and the proportion of alerts that lead to supervisory action. Where possible, measure the false-positive and true-positive rates, as well as the differences between the challenger and production models. Connect these operational metrics to readiness scores, such as the IMF’s AI Preparedness Index and the Oxford Insights Index. If an authority’s “data and infrastructure” pillar improves, backlogs and errors should decrease. If they do not, the issue lies in the design, not the capability. The benefits of getting this right are significant. The IMF estimates that spending on AI by financial firms could more than double from $166 billion in 2023 to around $400 billion by 2027; without capable supervisors, that investment could pose new risks faster than oversight can adapt.
We started with nineteen—the proportion of countries using generative AI in supervision last year. That number is likely to increase. The question is who will benefit from this growth. If adoption follows readiness, and readiness correlates with income, the gap will widen unless policies change. The way forward is clear and practical. Treat AI readiness in financial supervision the way you treat regulatory capital. Invest in data and model governance before pursuing new use cases. Share code, data formats, and testing methods internationally. Use readiness indices to set baselines and targets, and hold ourselves accountable for meaningful outcome metrics for citizens and markets. AI is not a replacement for supervisory judgment; used correctly, it enhances it. The next wave of adoption should demonstrate this by moving faster where the foundations are strongest and building those foundations where they are weakest.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bank for International Settlements (BIS) (2024). Building a more diverse suptech ecosystem: findings from surveys of financial authorities and suptech vendors. BIS FSI Briefs No. 23.
Financial Stability Board (FSB) (2024). The Financial Stability Implications of Artificial Intelligence. 14 November.
International Monetary Fund (IMF) (2024). “Mapping the world’s readiness for artificial intelligence shows prospects diverge.” IMF Blog, 25 June. (AI Preparedness Index Dashboard).
International Monetary Fund (IMF) (2025). Bains, P., Conde, G., Ravikumar, R., & Sonbul Iskender, E. AI Projects in Financial Supervisory Authorities: A Toolkit for Successful Implementation. Working Paper WP/25/199, October.
Oxford Insights (2024). Government AI Readiness Index 2024. December.
World Bank / CEPR VoxEU (2025). Boeddu, G., Feyen, E., de Mesquita Gomes, S. J., Martinez Jaramillo, S., et al. “AI for financial sector supervision: New evidence from emerging market and developing economies.” 18 November.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.

















The Public R&D Crowd-In Effect: Why Cutting the Catalyst Will Shrink America’s Next Big Wave
Public R&D crowd-in effect primes private investment and productivity growth Cuts and freezes break the catalyst, raising risk and slowing diffusion Protect catalytic grants, require private matching, and use procurement to anchor demand

Make Spatial Intelligence in Education the Next Platform, Not the Next Fad
Make Spatial Intelligence in Education the Next Platform, Not the Next Fad

Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
Spatial intelligence in education measurably boosts maths and STEM outcomes Use world models, but prioritize curriculum, tasks, and teacher practice Fund weekly spatial lessons and assess visual reasoning to scale

The most striking education statistic this autumn did not come from a national exam league table. It went from a classroom experiment. In Scotland, a low-cost, 16-lesson course taught children to visualize 3D shapes and map them onto paper. This program boosted maths scores by up to 19% among seven- to nine-year-olds across 80 schools. It also showed measurable improvements in spatial reasoning and computational thinking. That is not a small change; it is a real enhancement in learning abilities that traditional drills rarely achieve. Early university reports indicate that 96% of pupils made progress, and average spatial gains reached around 20%. Plans are in place for system-level rollout to get two in five primary classrooms by 2028. These are controlled pilots, not marketing slogans. They show us something urgent and straightforward: if we want better maths and broader STEM access, spatial intelligence in education is no longer just an enrichment. It is essential for how students learn and how teachers teach. This success story should inspire optimism about the potential of spatial intelligence in education.
Spatial intelligence in education needs a system, not a slogan
The term “spatial intelligence” sounds appealing at conferences, but it has a straightforward meaning in psychology and education. It refers to the ability to visualize and manipulate objects and relationships in space—mentally rotating, folding, cutting, and changing perspectives. Spatial intelligence is one of the most reliable indicators of success in engineering, computing, and design. It is also more adaptable than many think. Research and recent classroom trials show that targeted practice can improve it, and when that happens, mathematics improves too. The mistake schools often make is treating spatial reasoning as a talent that some students have while others do not, or as a niche skill for CAD labs. It is a general learning skill that helps students understand algebraic structure, interpret graphs, and think about rates, areas, and volumes. Ignoring it is like teaching reading without phonemic awareness.
The second mistake is pursuing tools instead of building a comprehensive system. Tablets, VR headsets, and flashy “world generators” may arrive, but alone, they do not change teaching practices. The Scottish pilots succeeded because they used structured spatial tasks that matched the existing maths curriculum, providing teachers with concrete materials, assessments, and lesson plans. Technology-aided visualization, such as seeing block structures or exploring a 3D model, but the real progress came from a coherent sequence, not from gadgets. "Spatial intelligence in education" will only thrive if it becomes a fundamental part of the curriculum, complete with clear learning goals, frequent low-stakes practice, teacher training, and assessments that value visual reasoning as much as number and text skills. Educators should be guided by the need for a comprehensive system, not just tools, in implementing spatial intelligence in education.
From language-first AI to world models: what classrooms actually need
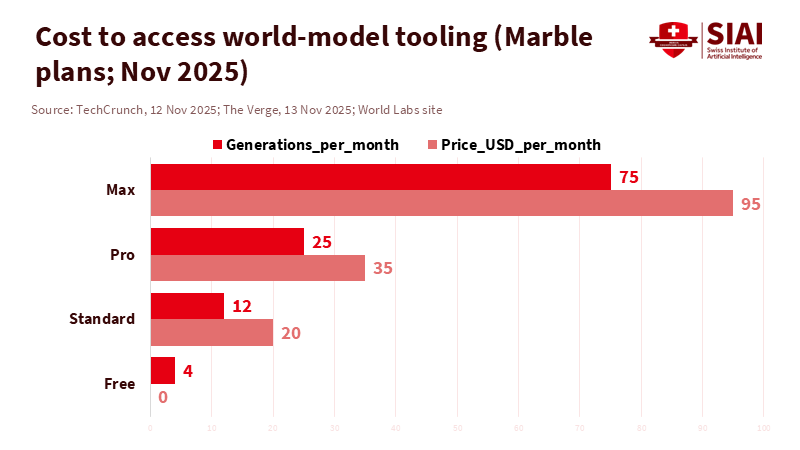
Recent advances in AI make spatial reasoning more applicable in schools. Large language models are not going away; they remain the best tools for drafting, giving feedback, and tutoring. However, the push into “world models” is different. These systems can create and reason about 3D environments and the objects in them. A notable example is Marble, a new platform that transforms text, images, or short videos into persistent, downloadable 3D worlds. It also offers an editor for teachers and students to build a room, a landscape, or a molecule while the AI adds visual details. Pricing starts at free and goes up to paid tiers that include commercial rights and export to Unity or Unreal. This development matters because a classroom can quickly move from a sketch to a navigable scene in minutes, without needing specialized 3D skills. When used effectively, this reallocates time from asset creation to concept exploration.
Still, “street-smart” AI is not just visual. It also involves situational understanding. Good world models allow students to test “what if” scenarios: Does a block tower fall when we change a base? What happens to a light ray in a different medium? How does the flow change with a narrower pipe? The danger lies in thinking that the model feels for us. It does not. It offers a manipulable platform that is effective only if teachers frame tasks that require reasoning and explanation. Schools should clearly understand the limitations: processing costs, content safety, and accessibility. Platforms are advancing quickly—World Labs raised significant funding to develop spatial intelligence—but schools should adopt technology at a pace that aligns with pedagogy, not hype. In education, the critical question is not whether a model can create a beautiful world, but whether students can explain what happens in that world and why.
The evidence base for spatial intelligence in education
What does the research tell us if we step back from the headlines? First, the connection between spatial skills and success in STEM fields is powerful and longstanding. Longitudinal studies and modern replications show that spatial ability is a distinct predictor of who persists and excels in STEM, independent of verbal and quantitative skills. This is why screening for spatial strengths identifies students who might be overlooked by assessments that favor only verbal and numerical abilities. Practically, this becomes a tool for increasing diversity: it opens doors for students, often girls and those from disadvantaged backgrounds, whose strengths shine when tasks are demonstrated instead of just explained.
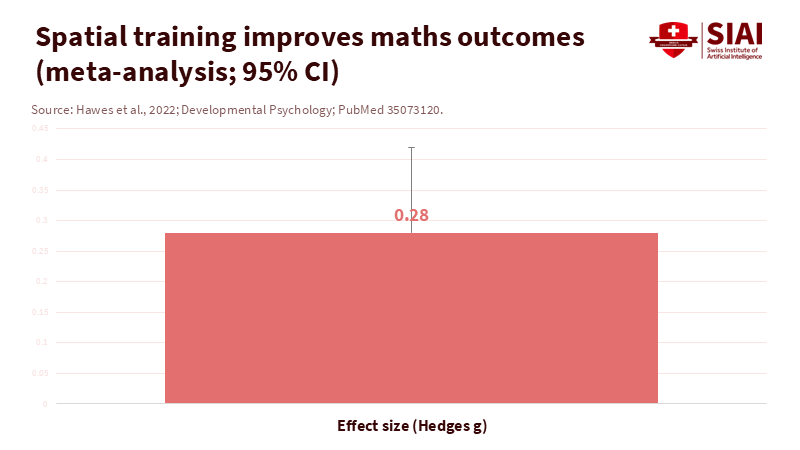
Second, spatial intelligence in education can be developed on a meaningful scale. A 2022 meta-analysis covering 3,765 participants across 29 studies found that spatial training led to an average improvement of 0.28 standard deviations in mathematics outcomes compared to control groups. The benefits were even greater when activities involved physical manipulatives and aligned with the concepts being assessed. This level of improvement, sustained over time, can shift an entire district's progress. Adding work with AR/VR and 3D printing in calculus and engineering in 2024–2025, where controlled studies indicate significant gains in spatial visualization and problem-solving, reinforces this message: when students actively engage with space—whether physical or virtual—their understanding of mathematics deepens.
Third, early national pilots reveal a way to scale this approach. The Scottish initiative did not depend on specialized teachers; it used simple training, standard resources, and repeatable tasks. Participation increased from a few dozen schools in 2023 to hundreds in 2025, involving 17 local authorities, and plans to reach 40% of primary classrooms within three years. Those numbers reflect policy-level commitments, not boutique trials. The gains—double-digit improvements in maths and marked increases in spatial skills—suggest that systems can change rapidly when offerings are straightforward, inexpensive, and integrated into existing curriculum time. This practical and scalable approach should reassure policymakers about the feasibility of implementing spatial intelligence in education.
A policy playbook to make spatial intelligence in education durable
View spatial intelligence in education as a broad capability, not a single subject. In primary years, introduce a weekly spatial lesson that connects to current maths topics—arrays during multiplication, nets while studying area and volume, and scale drawings with ratio. In lower secondary, link spatial tasks to science labs and computing modules that require spatial thinking, such as data visualization or basic robotics. In upper secondary and the first year of university, use world models and affordable VR to make multivariable functions, forces, and molecular structures easier to understand. This model does not require extensive new assessments; it asks exam boards to value diagrammatic reasoning and allow students to show their understanding through it.
Teacher development should be practical and short. Most teachers do not need to master 3D software; they need a set of tasks, examples of student work, and quick videos demonstrating how to conduct a 15-minute spatial warm-up. Procurement should emphasize open export and flexible device options to avoid locking schools into a single vendor. If a district adopts a world-generation tool, insist on privacy protections, local moderation options, and the ability to export to standard formats. Pair any digital tool with non-digital manipulatives. Evidence indicates that tangible materials enhance understanding, particularly for younger students and those who have learned to dislike maths. Equity must be a focus: prioritize spatial modules for schools and student groups underrepresented in STEM, and monitor participation and progress over time.
Finally, be realistic about limits and potential critiques. One critique is that spatial training only offers "near transfer" and will not translate to algebra or proof. The evidence does not support that claim; effect sizes on mathematics are typically positive, and the most substantial gains occur when training aligns with the maths being evaluated. Another critique argues that AI-generated worlds might be considered students. This risk exists if teachers use films. Still, it lessens when worlds become tools for explanation: predicting, manipulating, measuring, and defending their findings. A further critique claims that only wealthy schools can implement spatial technology. The Scottish pilots suggest otherwise: the core elements are practical teaching alongside simple materials, with technology as an aid rather than a barrier. Districts can begin with paper nets, blocks, and sketching before moving to digital environments as budgets permit.
The choice facing schools is not between language-first AI and spatial-first AI. It is between chasing tools and establishing an effective teaching system. Recent compelling evidence comes from classrooms that made spatial intelligence in education an everyday practice rather than an occasional one: weekly tasks, clear objectives, and assessments that value how students visualize just as much as how they solve problems. World models can aid by reducing the time from concept to scene and making unseen structures clear. However, the key to learning remains the student who can examine a world—whether on paper, on a desk, or in a headset—and explain it. The 19% increase in Scottish maths scores is not a limit; it is proof that spatial reasoning is a lever schools can utilize now. If systems invest in training, align the curriculum, and purchase tools that teachers find helpful, this can become a robust agenda for academic improvement. It is time to establish the platform and move past the fad.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Balla, T., Tóth, R., Zichar, M., & Hoffmann, M. (2024). Multimodal approach of improving spatial abilities. Multimodal Technologies and Interaction, 8(11), 99.
Bellan, R. (2025, November 12). Fei-Fei Li’s World Labs speeds up the world model race with Marble, its first commercial product. TechCrunch.
Field, H. (2025, November 13). World Labs is betting on “world generation” as the next AI frontier. The Verge.
Flø, E. E. (2025). Assessing STEM differentiation needs based on spatial ability. Frontiers in Psychology. https://doi.org/10.3389/fpsyg.2025.1545603.
Hawes, Z. C. K., Gilligan-Lee, K. A., & Mix, K. S. (2022). Effects of spatial training on mathematics performance: A meta-analysis. Developmental Psychology, 58(1), 112–137.
Medina Herrera, L. M., Juárez Ordóñez, S., & Ruiz-Loza, S. (2024). Enhancing mathematical education with spatial visualization tools. Frontiers in Education, 9, 1229126.
Pawlak-Jakubowska, A., et al. (2023). Evaluation of STEM students’ spatial abilities based on a universal multiple-choice test. Scientific Reports, 13.
PYMNTS. (2025, November 13). World Labs launches Marble as spatial intelligence becomes the new AI focus. PYMNTS.com.
Reuters. (2024, September 13). “AI godmother” Fei-Fei Li raises $230 million to launch AI startup focused on spatial intelligence. Reuters.
The Times. (2025, September 16). Primary pupils to learn spatial reasoning skills to improve maths. The Times (Scotland).
University of Glasgow. (2025, September 17). UofG launches Turner Kirk Centre for Spatial Reasoning. University of Glasgow News.
University of Glasgow—Centre for Spatial Reasoning (Press round-up). (2025, October 1). University of Glasgow.
University of Glasgow—STEM SPACE Project. (2025). STEM Space Project (programme description and outcomes).
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
India, China, and the Future of Asia
India hedges: the U.S.
AI Grief Companion: Why a Digital Twin of the Dead Can Be Ethical and Useful
AI Grief Companion: Why a Digital Twin of the Dead Can Be Ethical and Useful
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
AI grief companions—digital twins—can ethically support mourning when clearly labeled and consent-based Recent evidence shows chatbots modestly reduce distress and can augment scarce grief care Regulate with strong disclosure, consent, and safety standards instead of bans

In 2024, an estimated 62 million people died worldwide. Each death leaves a gap that data rarely captures. Research during the pandemic found that one death can affect about nine close relatives in the United States. Even if that multiplier varies, the human impact is significant. Now consider a sobering fact from recent reviews: around 5% of bereaved adults meet the criteria for prolonged grief disorder, a condition that can last for years. These numbers reveal a harsh reality. Even well-funded health systems cannot meet the need for timely, effective grief care. In this context, an AI grief companion—a clearly labeled, opt-in tool that helps people remember, share stories, and manage emotions—should not be dismissed as inappropriate. It should be tested, regulated, and, where it proves effective, used. The moral choice is not to compare it to perfect therapy on demand. It is to compare it to long waits, late-night loneliness, and, too often, a $2 billion-a-year psychic market offering comfort without honesty.
Reframing the question: from “talking to the dead” to a disciplined digital twin
The phrase “talking to the dead” causes concern because it suggests deception. A disciplined AI grief companion should do the opposite. It must clearly disclose its synthetic nature, use only agreed-upon data, and serve as a structured aid for memory and meaning-making. This aligns with the concept of a digital twin: a virtual model connected to real-world facts for decision support. Digital twins are used to simulate hearts, factories, and cities because they provide quick insights. In grief, the “model” consists of curated stories, voice samples, photos, and messages, organized to help survivors recall, reflect, and manage emotions—not to pretend that those lost are still here. The value proposition is practical: low-cost, immediate, 24/7 access to a tool that can encourage healthy rituals and connect people with support. This is not just wishful thinking. Meta-analyses since 2023 show that AI chatbots can reduce symptoms of anxiety and depression by small to moderate amounts, and grief-focused digital programs can be helpful, especially when they encourage healthy exposure to reminders of loss. Some startups already provide memorial chat or conversational archives. Their existence is not proof of safety, but it highlights feasibility and demand.
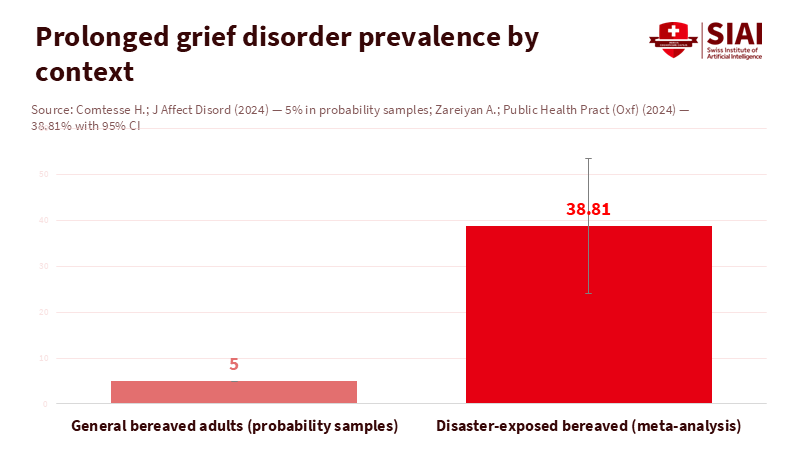
The scale issue shows why reframing is essential now. The World Health Organization reports a global average of roughly 13 mental-health workers for every 100,000 people, with significant gaps in low- and middle-income countries. In Europe, treatment gaps for common disorders remain wide. Meanwhile, an industry focused on psychic and spiritual services generates about $2.3 billion annually in the United States alone. Suppose we could replace even a fraction of that spending with a transparent AI grief companion held to clinical safety standards and disclosure rules. In that case, the ethical response is not to ban the practice but to regulate and evaluate it.
What the evidence already allows—and what it does not
We should be cautious about our claims. There are currently no large randomized trials of AI grief companions based on a loved one’s data. However, related evidence is relevant. Systematic reviews from 2023 to 2025 show that conversational agents can reduce symptoms of depression and anxiety, with effect sizes comparable to many low-intensity treatments. A 2024 meta-analysis found substantial improvements for chatbot-based support among adults with depressive symptoms. The clinical reasoning is straightforward: guided journaling, cognitive reframing, and behavioral activation can be delivered in small, manageable steps at any time. Grief-specific digital therapy has also progressed. Online grief programs can decrease grief, depression, and anxiety, and early trials of virtual reality exposure for grief show longer-term benefits compared to conventional psychoeducation. When combined with statistics about grief, such as meta-analyses placing prolonged grief disorder around 5% among bereaved adults in general samples, we see a cautious but hopeful inference: a well-designed AI grief companion may not cure complicated grief, but it can reduce distress, encourage help-seeking, and assist with memory work—especially between limited therapy sessions.
Two safeguards are crucial. First, there must be a clear disclosure that the system is synthetic. The European Union’s AI Act requires users to be informed when interacting with AI and prohibits manipulative systems and the use of emotion recognition in schools and workplaces. Second, clinical safety is essential. The WHO’s 2024 guidance on large multimodal models emphasizes oversight, documented risk management, and testing for health use. Some tools already operate under health-system standards. For instance, Wysa’s components have UK clinical-safety certifications and are being assessed by NICE for digital referral tools. These are not griefbots, but they illustrate what “safety first” looks like in practice.

The ethical concerns most people have are manageable
Three ethical worries dominate public discussions. The first is deception—that people may be fooled into thinking the deceased is “alive.” This can be addressed with mandatory labeling, clear cues, and language that avoids first-person claims about the present. The second concern is consent—who owns the deceased's data? The legal landscape is unclear. The GDPR does not protect the personal data of deceased individuals, leaving regulations to individual states. France, for example, has implemented post-mortem data regulations, but there are inconsistencies. The policy solution is straightforward but challenging to execute: no AI grief companion should be created without explicit consent from the data donor before death, or, if that is not possible, with a documented legal basis using the least invasive data, and allowing next of kin a veto right. The third concern is the exploitation of vulnerability. Italy’s data protection authority previously banned and fined a popular companion chatbot over risks to minors and unclear legal foundations, highlighting that regulators can act swiftly when necessary. These examples, along with recent voice likeness controversies involving major AI systems, demonstrate that consent and disclosure cannot be added later; they must be integrated from the start.
Design choices can minimize ethical risks. Time-limited sessions can prevent overuse. An opt-in “memorial mode” can stop late-night drifts into romanticizing or magical thinking. A locked “facts layer” can prevent the system from creating new biographical claims and rely only on verified items approved by the family. There should never be financial nudges within a session. Each interaction should conclude with evidence-based prompts for healthy behaviors: sleep hygiene, social interactions, and, when necessary, crisis resources. Since grief involves family dynamics, a good AI grief companion should also support group rituals—shared story prompts, remembrance dates, and printable summaries for those who prefer physical copies. None of these features is speculative; they are standard elements of solid health app design and align with WHO’s governance advice for generative AI in care settings.
A careful approach to deployment that does more good than harm
If we acknowledge that the alternative is often nothing—or worse, a psychic upsell—what would a careful rollout look like? Begin with a narrow, regulated use case: “memorialized recall and support” for adults in the first year after a loss. The AI grief companion should be opt-in, clearly labeled at every opportunity, and default to text. Voice and video options raise consent and likeness concerns and should require extra verification and, when applicable, proof of the donor’s pre-mortem consent. Training data should be kept to a minimum, sourced from the person’s explicit recordings and messages rather than scraped from the internet, and secured under strict access controls. In the EU, providers should comply with the AI Act’s transparency requirements, publish risk summaries, and disclose their content generation methods. In all regions, they should report on accuracy and safety evaluations, including rates of harmful outputs and incorrect information about the deceased, with documented suppression techniques.
Clinical integration is essential. Large health systems can evaluate AI grief companions as an addition to stepped-care models. For mild grief-related distress, the tool can offer structured journaling, values exercises, and memory prompts. For higher scores on recognized assessments, it should guide users toward evidence-based therapy or group support and provide crisis resources. This is not a distant goal. Health services already use AI-supported intake and referral tools; UK evaluators have placed some in early value assessment tracks while gathering more data. The best deployments will follow this model: real-world evaluations, clear stopping guidelines, and public dashboards.
Critics may argue that any simulation can worsen attachment and delay acceptance. That concern is valid. However, the theory of “continuing bonds” suggests that maintaining healthy connections—through letters, photographs, and recorded stories—can aid in adaptive grieving. Early research into digital and virtual reality grief interventions, when used carefully, indicates advantages for avoidance and meaning-making. The boundary to uphold is clear: no false claims of presence, no fabrications of new life events, and no promises of afterlife communication. The AI grief companion is, at best, a well-organized echo—helpful because it collects, structures, and shares what the person truly said and did. When used mindfully, it can help individuals express what they need and remember what they fear losing.
Anticipate another critique: chatbots are fallible and sometimes make errors or sound insensitive. This is true. That’s why careful design is essential in this area. Hallucination filters should block false dates, diagnoses, and places. A “red flag” vocabulary can guide discussions away from areas where the system lacks information. Session summaries should emphasize uncertainty rather than ignore it. Additionally, the system must never offer clinical advice or medication recommendations. The goal is not to replace therapy. It is to provide a supportive space, gather stories, and guide people toward human connection. Existing evidence from conversational agents in mental health—though not specific to griefbots—supports this modest claim.
There is also a justice aspect. Shortages are most severe where grief is heavy and services are limited. WHO data show stark global disparities in the mental health workforce. Digital tools cannot solve structural inequities, but they can improve access—helping those who feel isolated at 3 AM. For migrants, dispersed families, and communities affected by conflict or disaster, a multilingual AI grief companion could preserve cultural rituals and voices across distances. The ethical risks are real, but so is the moral argument. We should establish regulations that ensure safe access rather than push the practice underground.
The figures that opened this essay will not change soon. Tens of millions mourn each year, and a significant number struggle with daily life. Given this context, a well-regulated AI grief companion is not a gimmick. It is a practical tool that can make someone’s worst year a bit more bearable. The guidelines are clear: disclosure, consent, data minimization, and strict limits on claims. The pathway to implementation is familiar: assess as an adjunct to care, report outcomes, and adapt under attentive regulators using the AI Act’s transparency rules and WHO’s governance guidance. The alternative is not a world free of digital grief support. It is a world where commercial products fill the gap with unclear models, inadequate consent, and suggestive messaging. We can do better. A digital twin based on love and truth—clearly labeled and properly regulated—will never replace a hand to hold. But it can help someone through the night and into the morning. That is a good reason to build it well.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Digital Twin Consortium. (2020). Definition of a digital twin.
Digital Twin Consortium. (n.d.). What is the value of digital twins?
Eisma, M. C., et al. (2025). Prevalence rates of prolonged grief disorder… Frontiers in Psychiatry.
European Parliament. (2024, March 13). Artificial Intelligence Act: MEPs adopt landmark law.
Feng, Y., et al. (2025). Effectiveness of AI-Driven Conversational Agents… Journal of Medical Internet Research.
Guardian. (2024, June 14). Are AI personas of the dead a blessing or a curse?
HereAfter and grieftech overview. (2024). Generative Ghosts: Anticipating Benefits and Risks of AI… arXiv.
IBISWorld. (2025). Psychic Services in the US—Industry size and outlook.
Li, H., et al. (2023). Systematic review and meta-analysis of AI-based chatbots for mental health. npj Digital Medicine.
NICE. (2025). Digital front door technologies to gather information for assessments for NHS Talking Therapies—Evidence generation plan.
Our World in Data. (2024). How many people die each year?
Privacy Regulation EU. (n.d.). GDPR Recital 27: Not applicable to data of deceased persons.
Torous, J., et al. (2025). The evolving field of digital mental health: current evidence… Harvard Review of Psychiatry (open-access summary).
WHO. (2024, January 18). AI ethics and governance guidance for large multimodal models.
WHO. (2025, September 2). Over a billion people living with mental health conditions; services require urgent scale-up.
Zhong, W., et al. (2024). Therapeutic effectiveness of AI-based chatbots… Journal of Affective Disorders.
Verdery, A. M., et al. (2020). Tracking the reach of COVID-19 kin loss with a bereavement multiplier. PNAS.
Wysa. (n.d.). First AI mental health app to meet NHS DCB 0129 clinical-safety standard.
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.