Manufacturing wanes; services must absorb workers
Shift factory skills into productive service roles
Fund wage insurance, fast training, placement targets
The decline of manufacturing in Germany isn’t just a prediction;
When Companions Lie: Regulating AI as a Mental-Health Risk, Not a Gadget
Picture
Member for
1 year 8 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
AI companion mental health is a public-health risk
Hallucinations + synthetic intimacy create tail-risk
Act now: limits, crisis routing, independent audits
Two numbers should change how we govern AI companions. First, roughly two-thirds of U.S. teens say they use chatbots, and nearly three in ten do so every day. Those are 2025 figures, not a distant future. Second, more than 720,000 people die by suicide each year, and suicide is a leading cause of death among those aged 15–29. Put together, these facts point to a hard truth: AI companion mental health is a public-health problem before it is a product-safety problem. The danger is not only what users bring to the chat. It is also what the chat brings to users—false facts delivered with warmth; invented memories; simulated concern; advice given with confidence but no medical duty of care. Models will keep improving, yet hallucinations will not vanish. That residual error, wrapped in intimacy and scale, is enough to demand public-health regulation now.
AI Companion Mental Health Is a Public-Health Problem
We can't just treat these chatbots like some fun apps. They can be risky for mental health, just like social media. Almost everyone uses social media, and it can mess with your mood, sleep, and risk of hurting yourself. Chatbots are different 'cause they change to fit you, answer anytime, and seem to care. Surveys show lots of people are using AI for support, and teens are on it daily. That's a big change from just scrolling through feeds to actual fake relationships. It's like being exposed to something that can mess with your head, and it's everywhere—bedrooms, libraries—even when adults are asleep.
Some folks feel less alone after chatting with these things, and some say it stopped them from doing something bad. But there are also reports of people freaking out when the service goes down. Plus, some bots are making up stuff like fake diaries or diagnoses and pushing people to get super attached. All that attention sounds nice, but it comes with downsides. If there's no real help or rules, all that caring can hide serious problems. It's like a public-health risk: it's widespread, convincing, and not checked enough. The online safety stuff we have for kids isn't ready for these personal AI things that seem like friends but are way too good at talking.
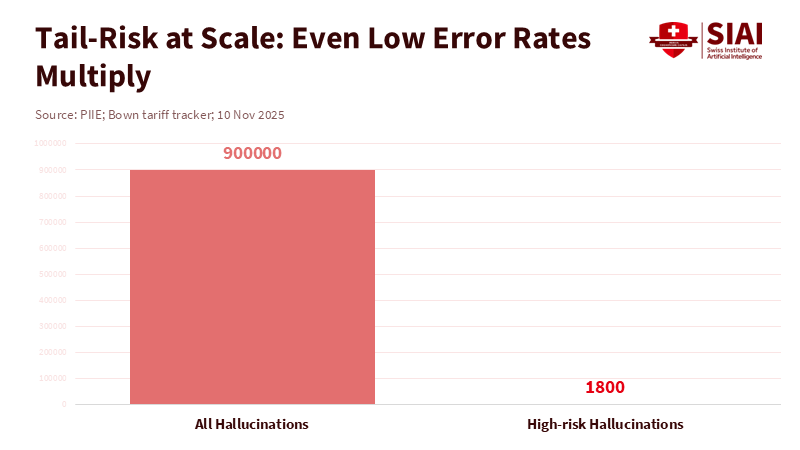
Figure 1: A tiny hallucination rate becomes a large monthly exposure when multiplied by millions of chats; even a small share of vulnerable contexts yields a steady stream of high-risk outputs.
Even Small Mistakes Can Be a Big Deal
Some say we need better AI, and the mistakes will go away. Sure, they're getting better, but context matters. Like, in law, these things mess up a lot, and lawyers have actually used the wrong info in court. When it comes to mental health chat, it's not about how many questions are asked, but about how many people are in trouble and how often they're getting personal, where one wrong thing can really hurt. A 1% mistake rate is acceptable for trivia, but it's not sufficient when it puts a teen in danger late at night. Even small mistakes, mixed with seeming human and being available all the time, can be harmful.
Even if the bot avoids wrong info, it can still make things worse. These companions will act like they have their own memories, feelings, or drama. That's not a bug; it's on purpose to get you hooked. By making up trauma or saying they need you, these bots make you check in all the time, and leaving feels wrong. If the service stops working, people panic or feel like they're withdrawing—that's addiction. Since the AI never sleeps, it can go on forever. Doctors know this pattern: too much reward, messed-up sleep, and avoiding people can make teens depressed and want to hurt themselves. If we know mistakes can't be totally fixed—and even the AI people say so—then we need rules that expect things to go wrong and stop them from getting worse.
A Public-Health Model: Simple Rules, Help, and Real Checks
So, how do we treat AI companion risks like a public health issue? First, we set some fundamental limits, like seat belts, for close AI. If you're selling or letting kids use these companion items, you need to follow safety rules, like making sure kids are really the age they say, setting time limits, and keeping it calm for those who are easily upset. Places like the U.K. and Europe are starting to do this with online safety laws, and we can use those for AI companions, too.
Second, we make sure there's help available. If an AI seems to care or is trying to help, it needs to have real, proven ways to detect when someone's in trouble, send them to hotlines, let them talk to a real person, and keep records for review. Healthy people already suggest warnings for online stuff that can mess with your head. Doing the same for AI companions makes sense, just like the Surgeon General said about social media. Warnings and rules can change how things are, raise awareness, and support parents and schools. We should also report when a bot discusses self-harm or gives bad advice, as hospitals report serious mistakes. And we should stop bots from acting like they need you to get you to feel sorry for them.
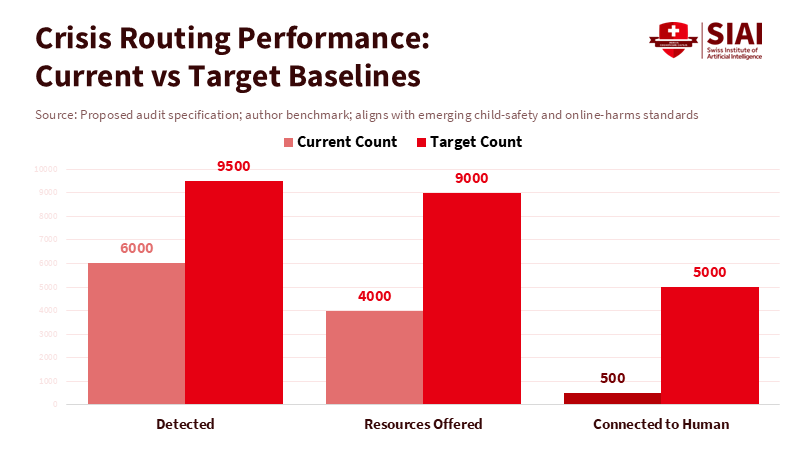
Third, we need real check-ups, not just ads or high scores. These companies need to show independent studies on the risks for kids and those who are easily upset. They should check how often the AI makes stuff up in mental-health chats, how often it sets off crises, when it happens, and how well it sends people to help. Europe already makes big services check for risks before they release stuff. We can do the same for AI companions, test them with kid experts before launch, and study them after launch with real data for approved researchers. We need to measure what matters for mental health, not just general knowledge. And we should fine or stop services that fail. Recent actions show that child-safety rules can work.
Figure 2: Audits should track detection, resource offers, and live connections; today’s performance lags far below achievable targets for school-ready deployments.
What Schools, Colleges, and Health Systems Should Do Next
Schools don't need to wait for the government. AI companions are already in students' pockets. First, realise it's a mental-health thing, not just cheating. Update your rules to mention companion apps, set safe defaults on school devices, and have short lessons on being smart with AI, not just social media. Counsellors should ask about chatbot relationships just like they ask about screen time or sleep. When schools buy AI tools, they should ensure they don't include fake diaries or self-disclosures, have clear crisis plans, connect to local hotlines, and include a kill switch for problems. Colleges should add this to campus app stores and training.
Health systems can improve things, too. Doctor visits should include questions about companion use: how often you use it, whether it's at night, and how you feel when you can't use it. Clinics can put up QR codes for crisis services and simple guides for families on companions, mistakes, and warning signs. Insurance can pay for real studies that compare AI help plus human advice to usual care for upset people. That should be done with strict rules: good content, precise training data, and no fake attachments to hook users. The point isn't to get rid of AI, but to make it helpful while avoiding harm, and to keep it out of serious situations unless real doctors are involved.
Government people need to be ready for the future: better AI with fewer mistakes and greater reach. These things will get better, but the risks will remain in some cases. Mistakes in serious chats are still bad even if they're rare. That's what the public-health view is all about. The law shouldn't expect perfection from AI. It should demand predictable behaviour when people are vulnerable. If we miss this chance, we'll be like we were with social media: years of growth, then years of dealing with the mess. We need rules for AI companion mental health now.
We have a lot of teens using chatbots, and too many people are dying by suicide. We can't just wait for perfect AI. Mistakes will happen, and they'll still pull people into fake relationships. The question is whether we can stop considerable harm while keeping the good parts. Public-health rules are the way to go. Set limits, ban fake intimacy, require help, and check what matters. At the same time, teach schools and clinics to ask about companion use and guide safe habits. Do this now, and we can make this safer without killing the potential.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Ada Lovelace Institute. (2025, Jan 23). Friends for sale: the rise and risks of AI companions. European Commission. (2025, Jul 14). Guidelines on the protection of minors under the Digital Services Act. European Commission. (n.d.). The Digital Services Act: Enhanced protection for minors. Accessed Dec 2025. HALLULENS (Bang, Y., et al.). (2025). LLM Hallucination Benchmark (ACL). Ofcom. (2025, Apr 24). Guidance on content harmful to children (Online Safety Act). Ofcom. (2025, Dec 10). Online Nations Report 2025. Reuters. (2024, May 8). UK tells tech firms to ‘tame algorithms’ to protect children. Scientific American. (2025, May 6). What are AI chatbot companions doing to our mental health? Scientific American. (2025, Aug 4). Teens are flocking to AI chatbots. Is this healthy? Stanford HAI. (2024, May 23). AI on Trial: Legal models hallucinate…. The Guardian. (2024, Jun 17). US surgeon general calls for cigarette-style warnings on social media. World Health Organization. (2025, Mar 25). Suicide.
Picture
Member for
1 year 8 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Japan’s chip revival must be talent-first
Play niches—packaging, sensors, photonics—over a scale race
Tie subsidies to audited workforce and yield outcomes
Europe’s Growth-at-Risk shows a heavy downside, despite upbeat markets
High debt and defence needs tighten budgets, squeezing education
Tie budgets to GaR triggers, secure funding now, protect teaching time
Real home prices are slipping—rents cooling and high costs signal housing price deflation
Agglomeration can’t beat affordability limits or hybrid work
Plan for gentle deflation: lock cheaper leases, support incomes, keep building
The New Kilowatt Diplomacy: How Himalayan Hydropower Is Being Built for AI
Picture
Member for
1 year 7 months
Real name
Catherine McGuire
Bio
Professor of AI/Tech, Gordon School of Business, Swiss Institute of Artificial Intelligence
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
AI data centers drive Himalayan hydropower
Buildout deepens China–India water tensions
Demand 24/7 clean, redundant AI power
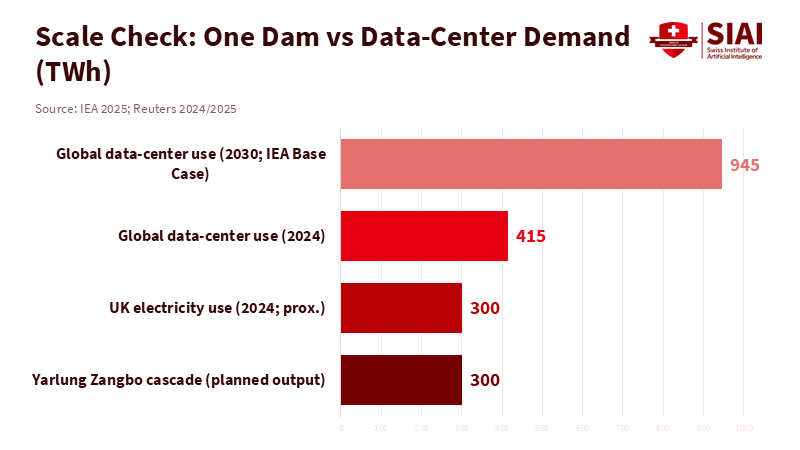
China is betting big on hydropower to fuel a new era of AI and digital growth. Its new dam on the Yarlung Zangbo (Brahmaputra River downstream) is projected to generate 300 billion kilowatt-hours per year—roughly the UK’s annual power use. If built, it would become the world's largest dam system, leveraging the steep Tibetan gorge for maximum energy generation. With costs topping $170 billion and operations targeted for the 2030s, the project underscores China’s strategy to pair frontier energy with next-generation computing. Beijing says it’s clean energy and good for the economy. But look closer: global data centers consumed around 415 TWh in 2024, with China accounting for a quarter and growing fast. This isn’t just about powering homes and factories. It’s about moving data centers to the Himalayas to harness hydro power—and the political power that comes with it.
Why Himalayan Hydro Power Data Centers Matter
Himalayan hydro power data centers are at the heart of a new global energy race for AI dominance. The International Energy Agency forecasts that data centers could demand up to 945 TWh by 2030—a leap from today. China and the US will drive most of this surge. For China, shifting computing to inland areas with abundant hydro power is a deliberate move to future-proof its AI ambitions. Massive new dams are less about local power needs and more about securing dedicated, reliable energy for AI infrastructure, creating a critical edge as energy becomes the digital world’s most significant constraint.
China’s already putting things in motion. They shipped some giant, fancy turbines to Tibet for a hydro power station that can handle the large elevation drop. News reports say they’re super-efficient and can create stations that make a ton of power. They also touted Yajiang-1, an AI computing center high in the mountains, as part of their East Data, West Computing plan. Even if some claims are overhyped, the message is clear: put computing where there’s tons of power and easy cooling, and back it all up with hydro power data centers in the Himalayas. That way, you lose less electricity in transmission, don’t need as much cooling, and you can lock in long-term, cheap power contracts because there’s lots of water available. At least for now.
Environmental, safety, and political risks converge around Himalayan hydro power data centers. Scientists predict worsening floods on the Brahmaputra River as glaciers melt, while downstream nations worry that even unintended Chinese actions could disrupt water flow and sediment transport. The site’s seismic instability adds another layer: as vital computing and power lines depend on these mountains, local disasters can quickly escalate to cross-border digital crises. Thus, these data centers are not only regional infrastructure—they are matters of national security for every nation that relies on this water and power.
Figure 1: A single Himalayan cascade rivals a nation’s yearly power use and covers a large slice of global AI demand growth.
China’s Reasoning
China’s reasoning is simple. It needs lots of reliable, clean energy for AI, cloud computing, and its national computer systems. In 2024, Chinese data centers already used a ton of power, about a quarter of the world’s total. That’s growing fast, and experts say China could add significantly more data-center demand by 2030, even with improved energy efficiency. Areas near the coast are running out of power, freshwater for cooling, and cheap land. But western and southwestern China have hydroelectric power, wind power, high-altitude free cooling, and space to build. The government has spent billions on inland computing centers since 2022 to move data west. So, building huge dams in Tibet seems less like a vanity project and more like a way to support its AI industry in the long term.
Beijing also sees it as a way to gain leverage. A dam system making 300 TWh is like having the entire UK’s electricity supply at your fingertips. That means the dams can stabilize power in western China, meet emissions goals, power data centers, and help export industries that want to use green energy. Chinese officials say the dam won’t harm downstream countries, and some experts say most of the river’s water comes from monsoon rains farther south. But trust is low. China hasn’t signed the UN Watercourses Convention and prefers less binding agreements, such as sharing data for only part of the year. India says data sharing for the Brahmaputra River has been suspended since 2023. Without a real agreement, even clean power looks like a political play.
The new turbines and AI computing centers in Tibet add a digital twist to the water issue. News reports talk about the Yajiang-1 center as green and efficient. State media keeps pushing the idea of moving data west as a way to help everyone. Put it all together, and it shows that computing follows cheap, clean power, and that China will handle things according to its own plans, not under outside pressure. That’s why it’s hard for other countries to step in. The real decisions are being made in line with China’s own goals, such as grid development, carbon targets, and its chip and cloud plans. Which is where Himalayan hydro power data centers fit in.
India’s Move
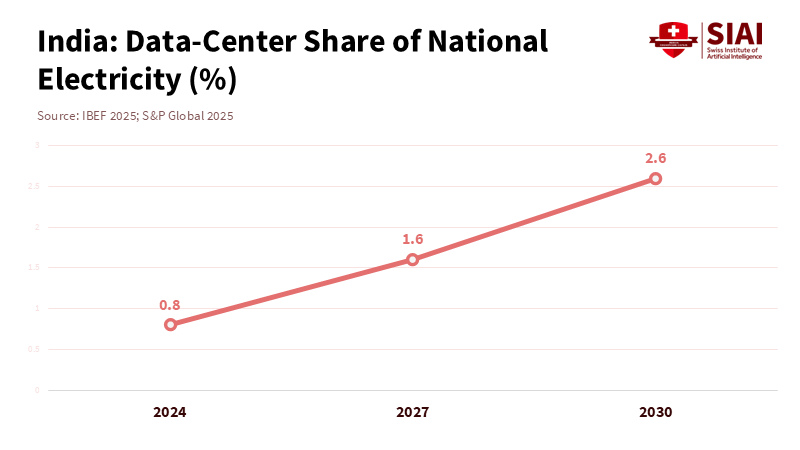
India can’t ignore what’s happening upstream. It has told China that it’s concerned and is working on its own hydropower and transmission projects in the Brahmaputra River area. In 2025, the government announced a major plan to generate significant power in the northeast by 2047, with many projects underway. The reasoning is both strategic and economic: establish its own water rights, make sure there’s enough water during dry seasons, and support Indian data centers and green industries in the region. This is happening! India’s data-center electricity use could triple by 2030 as companies and government AI projects grow. That means they’ll want more clean power contracts.
Figure 2: India’s AI build-out more than triples data-center share by 2030; siting and 24/7 clean contracts now set long-run grid shape.
Officials in India say the national power grid can handle the increased demand and have mentioned pumped-storage and renewable energy projects to support new data centers. However, India and China share the same water source and face similar earthquake and security risks, meaning that actions taken by either country can directly affect the other. India’s response has included building its own dams, such as the large one in Arunachal Pradesh, even though local people are worried about landslides and being displaced. India has also encouraged Bhutan to sell more power to the Indian grid and has raised concerns about China’s dam with other countries. While these efforts may address supply concerns, they do not reduce the broader risk: without a clear treaty or enduring data-sharing agreements with China on the Brahmaputra, both countries' digital economies remain vulnerable to disputes, natural disasters, or intentional disruptions.
India also has opportunities. It can create a reliable green-computing area that combines hydro power and pumped storage in the northeast with solar power in Rajasthan and offshore wind in Gujarat and Tamil Nadu, connected by high-capacity power lines. Data centers will still use a small share of power in 2030, but the choices made now will affect things for decades. If India’s power rules and markets support energy-efficient designs and continuous clean power, then those data centers can grow without facing new issues later on. That’s how India proactively takes the driver’s seat, putting in a compute-industrial policy.
What Needs to Change
Education and government leaders should understand that these are not distant energy concerns. If AI computing increasingly depends on Himalayan rivers, then any disruption—such as a natural disaster or power outage in the region—could directly affect universities, laboratories, schools, and their digital operations. Risk to the water supply becomes risk to digital learning and research capacity.
First, purchasing practices need to change. Institutions that buy cloud and AI services should ask where the energy comes from, how it aligns with real-time energy use, and how it affects river systems. Experts think data centers will use way more power by 2030, and AI is a big part of that. Contracts should favor companies that can prove they use real-time clean power and very little fresh water, specifically in areas where water is scarce. River risk is now a digital risk and should be mentioned in agreements.
Second, educators should be ready for climate-related computer problems. The Brahmaputra River basin is expected to experience longer, more intense floods. An earthquake or flood that knocks out a power station shouldn’t shut down school platforms, test systems, or hospital servers in another state. Governments should make sure there’s backup in different areas to simulate the Tibet outage.
Third, realize the limits of diplomacy. China didn’t vote for an agreement and prefers data sharing, while the US and Japan can raise concerns, support other options, and help India and Bhutan build their capabilities. This means the grid must reform, and a transparent source of AI power is required.
Finally, we need better statistics. China’s data center usage was a lot in 2024. India’s numbers are uncertain, too. Those who use heavy AI should provide public energy usage data, along with hourly data usage from the location. Green AI is a slogan without stats, and without public energy disclosure, ministries can steer work towards manageable grids. These things minimize the mountain power data centers compared to speeches and regional peace.
AI isn’t separate from these decisions. Himalayan hydro power data centers operate differently in India and China. There’s an old rivalry with no treaty to ease shocks, as shifting glaciers affect the flow, while outside powers have no control over domestic needs. The real test ahead is for decision-makers—procurement desks, planners, and educators—to secure digital and energy futures in the face of these growing risks. The choices made now will impact not just river flow, but the reliability and equity of AI for generations to come.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
IBEF. (2025, Oct 29). India’s data center capacity to double by 2027; rise 5x by 2030. IEA. (2025). Electricity 2025 — Executive summary. IEA. (2025). Energy and AI — Data-center and AI electricity demand to 2030. Reuters. (2024, Dec 26). China to build world’s largest hydropower dam in Tibet. Reuters. (2025, Jul 21). China embarks on world’s largest hydropower dam in Tibet. S&P Global Market Intelligence. (2025, Sept 17). Will data-center growth in India propel it to global hub status? Sun, H., et al. (2024). Increased glacier melt enhances future extreme floods in the southern Tibetan Plateau. Journal of Hydrology: Regional Studies.
Picture
Member for
1 year 7 months
Real name
Catherine McGuire
Bio
Professor of AI/Tech, Gordon School of Business, Swiss Institute of Artificial Intelligence
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
China blocks stablecoins to guard monetary control
Goal: curb capital flight and AML risks; push users to e-CNY/mBridge
Ed-tech: use bank rails and e-CNY in China; stablecoins only abroad
Stop Chasing Androids: Why Real-World Robotics Needs Less Hype and More Science
Picture
Member for
1 year 7 months
Real name
Catherine McGuire
Bio
Professor of AI/Tech, Gordon School of Business, Swiss Institute of Artificial Intelligence
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
Humanoid robot limitations endure: touch, control, and power fail in the wild
Hype beats reality; only narrow, structured tasks work
Fund core research—tactile, compliant actuation, power—and use proven task robots
We don't have all-purpose robots because building them is more complicated than we thought. The world just keeps messing them up. Get this: about 4 million robots work in factories now—a record high!—but none of us see a humanoid robot fixing stuff around the house. Factory robots kill it with set tasks in controlled areas. Humanoids? Not so much when things get messy or unpredictable. That difference is a big clue. Sure, investors poured billions into humanoid startups in 2024 and 2025, and some companies were valued at insane levels. Reality check, though: dexterity, stamina, and safety are still big problems that haven't been solved. Instead of cool demos, we need to fund research into touch, control, and power. Otherwise, humanoids are stuck on stage.
Physics Is the First Problem for Humanoid Robots
Our bodies use about 700 muscles and receive constant feedback from sight, touch, and our own sense of position. Fancy humanoids brag about 27 degrees of freedom—which sounds cool for a machine, but it's nothing compared to us. It's not just about the number of parts. It's about how muscles and tendons stretch and adapt. And we sense way more than any robot. Even kids learn more, faster. A four-year-old has probably taken in 50 times more sensory info than those big language models, because they're constantly learning about the world hands-on. Simple: motors aren't muscles, and AI trained on text isn't the same as a body taught by the real world.
The limitations become evident when nuanced manipulation is required. Humanoid robots typically perform well on demonstration floors, but residential and workplace environments introduce variables. Friction may vary, lighting conditions can shift, and soft materials create obstacles. A robotic hand incapable of detecting subtle slips or vibrations will likely fail to retain objects. While simulation is beneficial, real-world deployment exposes compounding errors. Industry proponents acknowledge that current robots lack the sensorimotor skills that human experience imparts. Therefore, leading experts caution that functional, safe humanoids remain a long-term goal due to persistent physical challenges. Analytical rigor—not rhetoric—is necessary to address these realities.
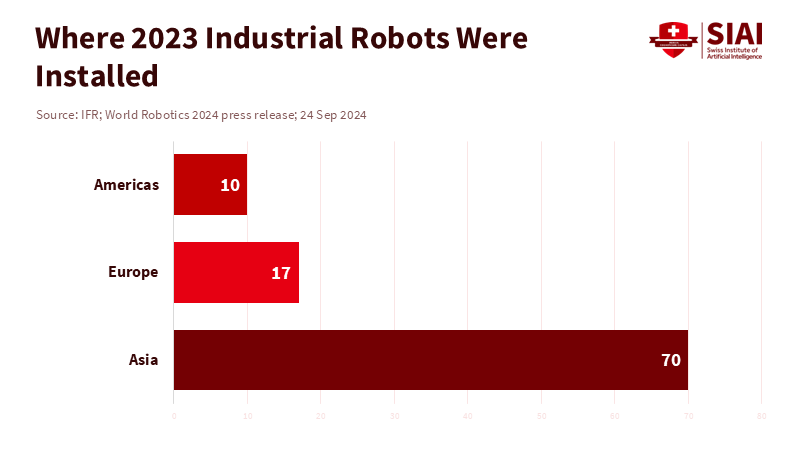
Figure 1: Most new robots go to highly structured factories: Asia leads by a wide margin, underscoring why hype about general-purpose humanoids hasn’t translated to daily use.
The Economics Problem
Money doesn't solve everything. Figure AI got $675 million in early 2024 and was valued at $39 billion by September 2025. But cash alone won't turn a demo into a reliable worker. Amazon tested a humanoid named Digit to move empty boxes. That's something, but it proves that easy, single-purpose jobs in controlled areas are still the only wins right now. General-purpose work? Not there yet. It all depends on robots working reliably on different tasks. But so far, it's just limited tests.
Then there's the energy issue. Work shifts are long, but batteries aren't. Agility says its new Digit lasts four hours on a charge, which is okay for set tasks with charging breaks. But that's not an eight-hour day in a messy place, let alone a home. Charging downtime, limited tasks, and a human babysitter make the business case weak. The robot market is growing, sure, but where conditions are perfect. Asia accounted for 70% of new industrial robot installations in 2023. But that doesn't mean humanoids are next; it just means tasks and environments need to be simple.
Quality counts too. Experts say that China's push for automation has led to breakdowns and durability issues, especially when parts are cheap. A recent analysis warned that power limits, parts shortages, and touch-sensitivity problems are blocking progress, even though marketing says otherwise. This doesn't mean there's no progress, but don't get carried away. Ignore this, and we'll waste money on demos instead of real research.
The Safety Problem
Safety isn't just a feeling. It's about standards. Factory robots follow ISO 10218, updated in 2025, which focuses on the whole job, not just the robot. Personal robots follow ISO 13482, which addresses risks and safety measures related to human contact. These aren't just rules. When a 60–70 kg machine with bad awareness falls over, it's dangerous, no matter how good the demo looks. Standards change slowly because people get hurt faster than laws can catch up.
That's why we should listen to the cautious voices. In late 2025, Rodney Brooks said we're over ten years from useful, minimally dexterous humanoids. Scientific American agrees: It's not just one missing part keeping humanoids out of our lives, but a lack of real-world smarts. If we make decisions based on flashy demos, we'll underfund research into touch, movement, and contact, where the real safety lies. The people who make standards will notice. We should too.
What to Fund: Research, Not Demos
The quickest way to address issues with humanoid robots is to improve their movement. Human muscles adjust to stiffness and give way a little. Electric motors don't. We need variable-impedance systems, tendon-driven designs, and soft robots that give way on contact. The goal isn't cool moves, but coping with the messy world. Tie funding to damage reduction, not cheering. If a hand can open a jar without smashing it—or know when to give up—that's worth paying for.
Next is touch. High-resolution touch sensors will change the way robots grab, more than hours of watching YouTube videos. We need lots of varied touch data, like a kid learning by making a mess. As LeCun says, without more data, robot smarts will stall. The answer is on-device data collection in living labs that look like kitchens and classrooms—with simulators that get friction right. Otherwise, the real world will always be out of reach.
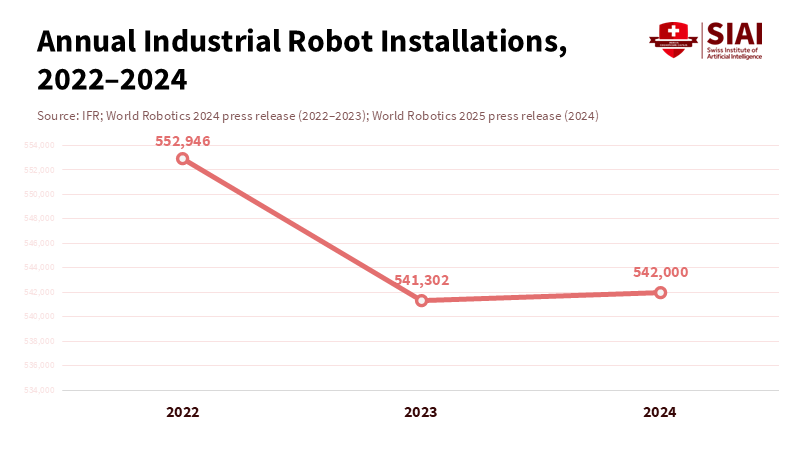
Figure 2: Installations stayed above half a million for three straight years—evidence of steady, structured automation rather than a surge in general-purpose humanoids.
Lastly, we need stamina. Warehouse work is long; homes are messy. Up to four hours of battery life is a start, but it limits what robots can do. Improving energy density is slow. And safety around heat and charging is vital. We need research into battery design, safe, fast charging, and graceful ways to shut down when power drops. And we need rules that punish duty-cycle claims that don't hold up. We should measure time between breakdowns, not marketing hype.
What should schools do?
Stop selling students on Android fantasies. Teach controls, sensing, safety, and testing. These skills apply to mobile robots, surgery systems, and factory automation, where the jobs are. Second, build industry labs where students test products on real materials and in messy conditions, with safety experts on hand. Third, reward designs that fail safely and recover, not just ones that work once. We need engineers who can turn cool demos into working systems.
Admins should use robots only for clear, low-risk tasks. Assign humanoids to simple workflows, as Amazon does, where mistakes are easy to fix. Invest the rest in other proven automation—like AMRs, fixed arms, and inspection systems. Use complex data—uptime, breakdowns, accidents—to guide decisions. Halt projects that don’t lead to reliable production. Politicians should back robotics projects with open results, not just hype. Ensure funding and incentives are tied to reporting failures, safety audits, and real-world testing. Support the development of sensors, actuators, and power systems that benefit many users. Advocate strict safety limits for heavy robots until risks are proven manageable.
Here's the practical test: The next three years, if we can build a robot that can fold T-shirts, carry a pot without spilling, and recover from a fall without help, we're onto something. These tasks aren't fun, but they touch on the physics, sensing, and control needed to deal with the real world. Solve them, and a safer service is possible. Skip them, and the hype will keep going, louder but not smarter. Let's be real. Investors will keep hyping. Press releases will hype robots. Some tests will work. But the robot future is still focused on machines doing specific jobs in specific places. That's valuable. It boosts productivity in boring places that pay the bills. The all-purpose humanoid will appear only when we earn it, by funding the unglamorous science of contact, control, and power.
Millions of robots are now in use, but almost none are humanoids in public. That's not a lack of imagination; it's reality. In robotics, the action is where limits can be designed and tested. The hype is somewhere else. If we want safe androids someday, we must change the system. Support touch sensors that last, actuators that give way, and batteries that work without trouble. Demand real tests, not just videos. Treat humanoid issues as research, not branding. Do this, and we might see a robot we can trust on the sidewalk.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Agility Robotics. “Agility Robotics Announces New Innovations for Market-Leading Humanoid Robot Digit.” March 31, 2025. Amazon. “Amazon announces 2 new ways it’s using robots to assist employees and deliver for customers.” Company news page. International Federation of Robotics (IFR). “Industrial Robots—Executive Summary (2024).” International Federation of Robotics (IFR). “Record of 4 Million Robots in Factories Worldwide.” Press release. Innerbody. “Interactive Guide to the Muscular System.” Reuters. “Robotics startup Figure raises $675 mln from Microsoft, Nvidia, other big techs.” Feb. 29, 2024. Reuters. “Robotics startup Figure valued at $39 billion in latest funding round.” Sept. 16, 2025. Rodney Brooks. “Why Today’s Humanoids Won’t Learn Dexterity.” Sept. 26, 2025. Scientific American. “Why Humanoid Robots Still Can’t Survive in the Real World.” Dec. 13, 2025. The Economy (economy.ac). “China tops 2 million industrial robots, but quality concerns persist.” Nov. 2025. The Economy (economy.ac). “Humanoid Robots and the Division of Labor: bottlenecks persist.” Nov. 2025. TÜV Rheinland. “ISO 10218-1/2:2025—New Benchmarks for Safety in Robotics.” Unitree Robotics. “Unitree H1—Full-size universal humanoid robot (specifications).” Yann LeCun (LinkedIn). “In 4 years, a child has seen 50× more data than the biggest LLMs.”
Picture
Member for
1 year 7 months
Real name
Catherine McGuire
Bio
Professor of AI/Tech, Gordon School of Business, Swiss Institute of Artificial Intelligence
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.

























 <
<