When Voters Lead, Law Follows: Public Opinion and Climate Policy After the IRA
Support is broad, underestimated Local clean jobs drive votes Show local data; build pipelines

The most crucial fact in climate politics today is not about a molecule or a megawatt.
Beyond the Ban: Why AI Chip Export Controls Won’t Secure U.S. AI Leadership
Beyond the Ban: Why AI Chip Export Controls Won’t Secure U.S. AI Leadership

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
Export controls slow foes, not secure leadership Invest in compute, clean power, talent Make NAIRR-style Compute Commons permanent

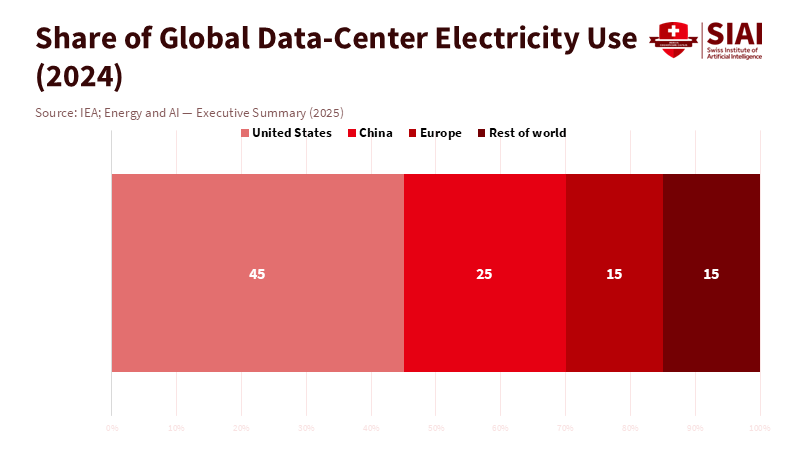
U.S. data centers used about 183 terawatt-hours of electricity in 2024, roughly 4% of total U.S. power consumption. This figure is likely to more than double by 2030. The United States already accounts for 45% of global data-center electricity use. These numbers reveal a clear truth: the future of American AI relies less on what leaves our ports and more on whether we can provide the computing power, energy, and talent needed to build and use systems domestically. While AI chip export controls may seem practical, they are not the deciding factor in who leads. They can slow rivals marginally, but do not build labs, wire campuses, or train students. We must focus on transforming energy, infrastructure, and education into a self-reinforcing system. With every semester we delay, the cost of missed opportunities increases, and our advantage shrinks.
AI chip export controls are a blunt tool
Recent proposals suggest a 30-month ban on licensing top accelerators to China and other adversaries, formalizing and extending the Commerce Department’s rules. The goal is straightforward: restrict access to advanced chips and make competitors fall behind. However, the policy landscape is already complicated. In 2023 and 2024, Washington tightened regulations; in 2025, Congress discussed new “SAFE CHIPS” and “Secure and Feasible Exports” bills; and the House considered a GAIN AI Act adding certification requirements for export licenses. These measures mainly solidify what regulators are already doing. They increase compliance costs but may complicate enforcement. They could also provoke reciprocal actions abroad and push trade into unclear channels, making it harder to monitor.
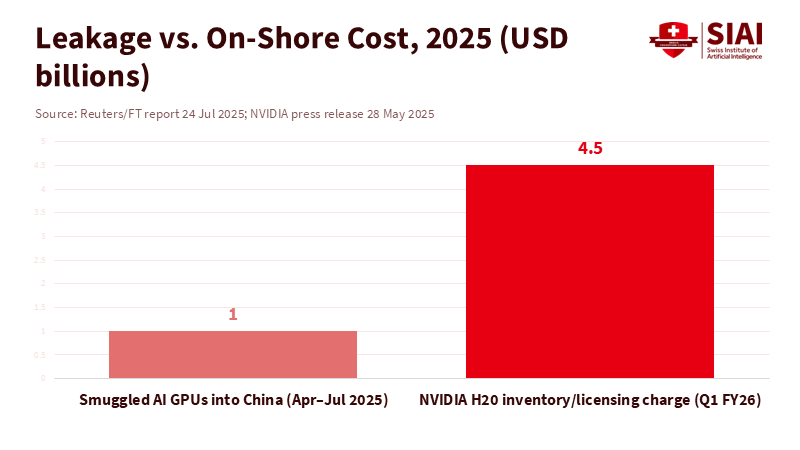
These unclear channels are real. According to a Reuters report, between April and July 2025, more than $1 billion worth of Nvidia AI chips entered China via black market channels despite strict U.S. export restrictions. Export-compliant “China-only” chips came and went as rules changed; companies wrote down their inventory; and one supplier reported no sales of its redesigned parts to China in a recent quarter after new licensing requirements were enforced. Controls produce effects, but those effects are messy, leaky, and costly domestically. In summary, AI chip export controls disappoint security advocates while imposing significant collateral damage at home.
Competition, revenue, and the U.S. innovation engine
There’s a second issue: innovation follows scale. U.S. semiconductor firms allocate a significant portion of their revenue to research and development, averaging around 18% in recent years and 17.7% in 2024. One leading AI chip company spent about $12.9 billion on R&D in 2025, despite rising sales, which lowered that percentage. That funding supports new architectures, training stacks, and tools that benefit universities and startups. A shrinking global market, as mandated by law, threatens the reinvestment cycle, particularly for suppliers and EDA tool companies that rely on the growth of system integrators.
However, supporters point out that the U.S. still commands just over 50% of global chip revenues, which they believe is strong enough to sustain industry leadership, according to the Semiconductor Industry Association. They cite record data-center revenue, long waitlists, and robust order books. All of this is true—and it underscores the argument. When companies are forced to withdraw from entire regions, they incur losses on stranded “China-only” products and experience margin pressure. Over time, these challenges affect hiring strategies, supplier decisions, and university partnerships. One research estimate shows China’s share of revenue for a key supplier dropping to single digits by late 2025; another quarter included a multi-billion-dollar write-off related to changing export rules. Innovation relies on steady cash flow and clear planning goals. AI chip export controls that fluctuate year to year do the opposite. The real question is not “ban or sell.” It’s about minimizing leakage while maintaining domestic growth.
China’s catch-up is real, but it has limits
China is making rapid progress. Domestic accelerators from Huawei and others are being shipped in volume; SMIC is increasing its advanced-node capacity; and GPU designers are eager to go public on mainland exchanges. One firm saw its stock rise by more than 400% on debut this week, thanks to supportive policies and local demand. Nevertheless, impressive performance on paper does not necessarily translate into equal capability in practice. Reports highlight issues with inter-chip connectivity, memory bandwidth, and yields; Ascend 910B production faces yield challenges around 50%, with interconnect bottlenecks being just as significant as raw performance for training large models. China can and will produce more, but its path remains uneven and costly, especially if it lacks access to cutting-edge tools. A CSIS report notes that when export controls are imposed, as seen with China, the targeted country often intensifies its own development efforts, which could lead to significant technological breakthroughs. This suggests that while export controls can increase challenges and production costs, they do not necessarily prevent a country from closing the competitive gap.
Where controls create barriers, workarounds appear. Parallel import networks connect orders through third countries; cloud access is negotiated; “semi-compliant” parts proliferate until rules change again. This ongoing dynamic strengthens China’s motivation to develop domestic substitutes. In essence, strict bans can accelerate domestic production when they are imposed without credible, consistent enforcement and without additional U.S. investments that push boundaries in a positive direction. In 2024–2025, policymakers proposed new enforcement measures, such as tamper-resistant verification and expanded “validated end-user” programs for data centers. This direction is right: smarter enforcement, fewer loopholes, and predictability, along with significant investment in American computing and power capacity for research and education.
An education-first industrial policy for AI
If the United States aims for lasting dominance, it needs a national education and computing strategy that can outpace any rival. The NAIRR pilot, initiated in 2024, demonstrated its effectiveness by providing researchers and instructors with access to shared computing and modeling resources. By 2025, it had supported hundreds of projects across nearly every state and launched a 'Classroom' track for hands-on teaching. This is more important than it may seem. Most state universities cannot afford modern AI clusters at retail prices or staff them around the clock. Shared infrastructure transforms local faculty into national contributors and provides students with practical experience with the same tools used in industry. Congress should make NAIRR permanent with multi-year funding, establish regional 'Compute Commons' driven by public universities, and link funding to inclusive training goals. According to a report from the University of Nebraska System, the National Strategic Research Institute (NSRI) has generated $35 in economic benefits for every $1 invested by the university, illustrating a strong return on investment. This impressive outcome underscores the importance of ensuring that all students in public programs can access and work with real hardware as a standard part of their education, rather than as an exception.
Computing without power is just a theory. AI demand is reshaping the power grid. U.S. computing loads accounted for about 4% of national electricity in 2024 and are projected to more than double by 2030. Commercial computing now accounts for 8% of electricity use in the commercial sector and is growing rapidly. One utility-scale deal this week included plans for multi-gigawatt campuses for cloud and social-media operators, highlighting the scale of what lies ahead. Federal and state policy should view university-adjacent power as a strategic asset: streamline connections near public campuses, create templates for long-term clean power purchase agreements that public institutions can actually sign, and prioritize transmission lines that connect "Compute Commons" to low-carbon energy sources. By aligning clean-power initiatives with campus infrastructure, we could spark the development of regional tech clusters. This would not only enhance educational capabilities but also attract industry partners eager to capitalize on a well-connected talent pool. The talent-energy feedback loop becomes essential, creating synergies that can broaden support far beyond energy committees. When AI chip export controls dominate the discussion, this vital bottleneck is often overlooked. Yet it determines who can teach, who can engage in open-science AI, and who can graduate students with real-world experience using production-grade systems.
Leadership is created, not blocked. It thrives in labs, on the grid, and within public universities, preparing the next generation of innovators. To ensure continued progress and maintain our competitive edge, we must embrace policies that amplify our strengths while fostering innovation. It is critical to envision and reach the next policy milestone that inspires collective action and drives us toward a future where American leadership in AI is unassailable.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Bloomberg. (2025, Dec. 4). Senators Seek to Block Nvidia From Selling Top AI Chips to China.
Bloomberg
Brookings Institution. (2025, Dec. 3). Why the GAIN AI Act would undermine US AI preeminence.
Brookings
CSET (Georgetown). (2024, May 8). The NAIRR Pilot: Estimating Compute.
CSIS. (2024, Dec. 11). Understanding the Biden Administration’s Updated Export Controls.
CSIS. (2025, Nov. 6). The Architecture of AI Leadership: Enforcement, Innovation, and Global Trust.
ExecutiveGov. (2025, Dec.). Bipartisan House Bill Seeks to Strengthen Enforcement of AI Chip Export Controls.
Financial Times. (2025, Dec.). Chinese challenger to Nvidia surges 425% in market debut.
Financial Times via Reuters summary. (2025, Jul. 24). Nvidia AI chips worth $1 billion entered China despite U.S. curbs.
IEA. (2024, Jan. 24). Electricity 2024.
IEA. (2025, Apr. 10). Global data centre electricity consumption, 2020–2030 and Share by region, 2024.
IEA. (2025). Energy and AI: Energy demand from AI and Executive Summary.
MERICS. (2025, Mar. 20). Despite Huawei’s progress, Nvidia continues to dominate China’s AI chips market.
NVIDIA. (2025, Feb. 26). Financial Results for Q4 and Fiscal 2025.
NVIDIA. (2025, May 28). Financial Results for Q1 Fiscal 2026. (H20 licensing charge.)
NVIDIA. (2025, Aug. 27). Financial Results for Q2 Fiscal 2026. (No H20 sales to China in quarter.)
Pew Research Center. (2025, Oct. 24). What we know about energy use at U.S. data centers amid the AI boom.
Reuters. (2025, Dec. 8). NextEra expands Google Cloud partnership, secures clean energy contracts with Meta.
Reuters. (2025, Dec. 4). Senators unveil bill to keep Trump from easing curbs on AI chip sales to China.
Semiconductor Industry Association (SIA). (2025, Jul.). State of the U.S. Semiconductor Industry Report 2025.
SemiAnalysis. (2025, Sep. 8). Huawei Ascend production ramp. (SMIC capacity estimates.)
The Information (archived via SOPA). (2024, Aug. 12). Nvidia AI chip smuggling to China becomes an industry.
Tom’s Hardware. (2025, Jul. 25). Underground China repair shops thrive servicing illicit Nvidia GPUs.
Tom’s Hardware. (2025, Dec.). Nvidia lobbies White House… lawmakers reportedly reject GAIN AI Act.
U.S. Bureau of Industry and Security (BIS). (2025, Jan. 15). Federal Register notice on Data Center Validated End-User program.
U.S. EIA. (2025, Jun. 25). Electricity use for commercial computing could surpass other uses by 2050.
The Wall Street Journal, LA Times, and other contemporaneous reporting on lobbying dynamics (cross-checked for consistency).
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.

















The New Literacy of War: Why Defense AI Education Must Move Faster Than the Drones
The New Literacy of War: Why Defense AI Education Must Move Faster Than the Drones

David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Published
Modified
Defense AI education is the bottleneck between record defense spending and real capability Train stack-aware teams with mission credentials Scale safely with oversight and shared compute

In 2024, global military spending soared to $2.718 trillion, the most significant annual rise since the Cold War. Simultaneously, Ukraine's frontline units lost 10,000 drones each month. This marks a shift in warfare from bodies to machines. Together, these facts highlight a critical issue: we do not educate enough people to direct, manage, and improve the software that now controls the pace and reach in the field and across defense agencies. Procurement budgets are racing ahead, while practice is falling behind. “Defense AI education” represents the gap between money and real outcomes—the difference between countless systems and genuine advantage. It now determines how fast ministries learn from battlefield data, how quickly logisticians adapt policies, and whether future officers can manage drone swarms as confidently as past leaders handled platoons. If we fail to teach and credential on a large scale, the drones will operate independently, unethically, and without impact.
Defense AI Education Is Now the Bottleneck
The past two years have driven this point home. NATO’s European members and Canada boosted defense spending by 18% in 2024. Twenty-three allies hit the 2% GDP target, more than double the number four years ago. Europe is urgently launching new industrial programs under EDIS and EDIP to push funds toward production and joint procurement. But time is running out: money alone will not deliver strategic gains. Training pathways, credentialing standards, and access to computing resources now determine whether AI tools can impact operations before the pace of threats accelerates further. That is what we must define as defense AI education: not just courses but rapid training to transform procurement, maintenance, planning, and policy toward faster, safer, and more accurate decisions. Note: the NATO figures reflect official ally submissions; EDIS/EDIP documents are legislative and program materials, not survey estimates.
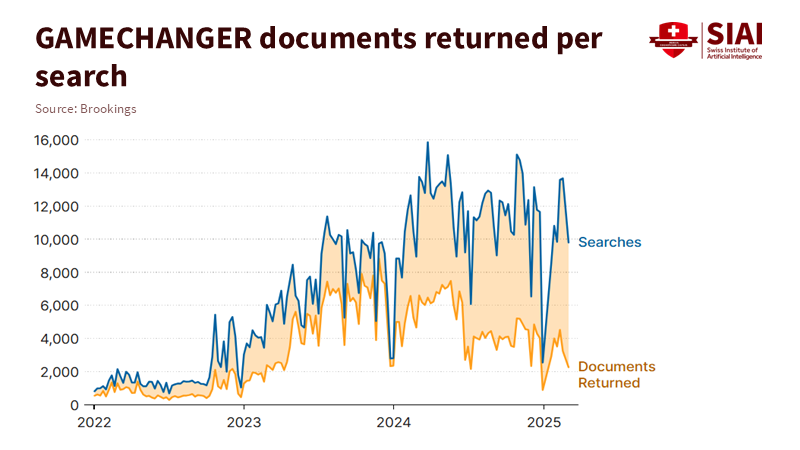
We already have a proof of concept in the U.S. Department of Defense. According to Brookings, GAMECHANGER is an AI-enabled search and association platform for policy that was developed to process unclassified policy documents and improve the management of complex directives and authorities. The lesson here is not that one tool can solve all problems. Instead, enterprise AI adoption increases when users can find, test, and tailor software for specific tasks, then apply that knowledge in the future. A report from the Brookings Institution discusses the importance of addressing workforce challenges and modernizing education in national security fields, emphasizing the need for effective recruitment, retention, and up-to-date training to prepare for emerging technologies such as AI. Teach policy staff how to question models. Teach program managers how to assess task-level value. Teach leaders to maintain tools through rotations. Note: usage numbers and institutional details are from the Brookings analysis; the scope is non-classified and focused on the enterprise side.
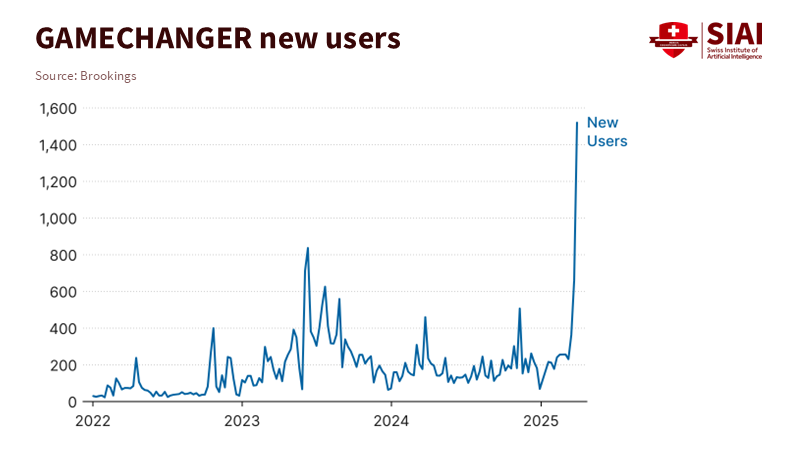
Defense AI Education for the Drone Age
The battlefield is already teeming with affordable autonomous systems. RUSI reports that Ukraine loses 10,000 drones per month, largely to electronic warfare—an urgent sign that success relies on learning, adapting, and replenishing at scale, not on a single advanced platform. U.S. policy has responded with haste: the Replicator initiative aims to deploy “thousands of autonomous systems” across all domains within the next 18 to 24 months. Funding, experimentation, and transition updates will come fast through late 2024. Europe’s industrial surge under EDIS and EDIP likewise calls for immediate mass production and speed. Defense AI education must not wait; it is the critical link that connects swarm tactics, resilient communications, electronic warfare-aware autonomy, and agile teamwork between humans and machines. Note: drone loss data comes from RUSI’s open-source report; Replicator details are based on official DoD announcements and analyses.
This training must reach beyond operators. The key advantage lies with “stack-aware” talent—people who understand sensors, data links, model behavior, and mission outcomes as a cohesive unit. Industry evidence supports this view. BCG estimates the aerospace and defense sector spent about $26.6 billion on AI in 2024, roughly 3% of its revenue. Yet 65% of programs remain stuck in the proof-of-concept stage. Value emerges when user-friendly solutions, domain-tailored models, and redesigned workflows come first—not yet another data pool. To translate this into curricula, it means creating capstone projects that assess mission-based return on investment rather than just model accuracy. It also means teaching students to work with electronic warfare-decoyed data, degraded GPS signals, or high-latency environments. Note: the spending and maturity estimates are from BCG’s 2025 sector report and accompanying PDF; these figures are based on surveys and modeling.
A Curriculum Playbook for Scale
Defense AI education should shift from specialized fellowships to widespread programs with quick time-to-value. First, establish mission studios that reflect real industry tasks. Pair an air base logistics dataset with a policy graph, and ask students to create prompts and agents that reduce parts approval time while adhering to ethical and legal guidelines. According to Purdue University, the Anvil supercomputer joined the National AI Research Resource (NAIRR) Pilot in May, providing expanded access to advanced computing power. Adopting successful methods like GAMECHANGER and integrating NAIRR resources could allow public universities without extensive infrastructure to conduct multi-GPU experiments and improve machine learning operations education, potentially benefiting fields such as finance, healthcare, and maintenance in realistic conditions. According to the U.S. National Science Foundation, efforts to expand access to AI resources through the NAIRR pilot are strengthened by collaboration with organizations like Voltage Park; building on this momentum, there is a growing push to establish a standardized and trusted system of credentials that ranges from foundational micro-credentials for operators to advanced leadership residencies. Link each credential to mission-based test events so learning directly supports deployment needs. Leverage European and NATO programs to coordinate and standardize, and use resources like NAIRR to ensure access is affordable and widespread. The goal: make education actionable, efficient, and directly connected to defense priorities.
Anticipating Critiques—and Meeting Them
To address the moral concern that defense AI education could militarize universities, take these actions: require safety cases and ethics reviews, implement export-control education, and separate research focused on lethal applications from that aimed at enterprise performance or humanitarian protection. Also, make curricula and assessment criteria public. These safeguards create transparent processes and oversight, supporting responsible AI adoption in defense.
The economic critique—why train for AI at scale if organizations cannot absorb it—demands three steps: teach practical adoption ("absorption") in courses, focus on user-friendly solutions beyond technical models, and evaluate students on their ability to drive operational change and return on investment. Capstone projects should deliver measurable outcomes—reduced policy alignment time, fewer false alarms, and less maintenance downtime. Making value visible prompts leaders to invest in talent and projects that advance organizational goals.
To address the talent supply concern, implement three key recommendations: expand the recruiting pool through apprenticeships and flexible pay, create crossover programs for educators in math and computing, and define clear roles for AI-focused jobs, such as product owners, data engineers, safety testers, and mission designers. This will help meet urgent demand and broaden access to high-priority defense roles.
A final concern is strategic: Europe’s increase in defense spending may stem more from geopolitical anxiety than from a coherent strategy. This is true, and that’s why education must be the priority. NATO’s spending increases and the EU’s industrial strategy create an opportunity to standardize training, evaluation, and data sharing, ensuring coalitions can work together seamlessly. Shared syllabi, common credentials, and NAIRR-like computing partnerships can prevent a mix of incompatible tools. If we teach to a common standard now, the next crisis won’t force us to rebuild skills while under pressure. Note: NATO statements are official records; the EU roadmap is a Commission document; computing partnerships refer to NAIRR designs.
From Spending to Understanding
The numbers that began this essay should capture our attention. $2.718 trillion in global military spending. Drone losses in the tens of thousands each month on one front. These figures describe a world where software dictates pace, and where disruption, jamming, and losses penalize those who cannot learn quickly. The challenge for universities, ministries, and industry is whether education itself can expand. Defense AI education is how we make this shift—from purchasing to understanding, from pilots to practical application, from hype to real value. It involves more than just courses. It requires credentials linked to missions, computing resources reaching both provinces and capitals, and leadership training that views governance as a skill, not just paperwork. If we align budgets, programs, and standards now, we can transform quantity into quality and risk into resilience. If we do not, we will spend more and comprehend less—and see the gap widen with every flight hour and every update cycle. The choice is ours, and time is not on our side.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Boston Consulting Group. (2025). Three Truths About AI in Aerospace and Defense (report and PDF). Retrieved June 2025.
Brookings Institution. (2025, Dec. 1). GAMECHANGER: A case study of AI innovation at the Department of Defense.
European Commission. (2025, Nov. 19). EU Defence Industry Transformation Roadmap.
European Commission. (2024). European Defence Industrial Strategy (EDIS) and EDIP overview.
NATO. (2024, June 17–18). Remarks and joint press conference transcripts.
National Science Foundation (NSF). (2024). NAIRR Pilot announcements and resource access.
RUSI. (2023). Russia and Ukraine are filling the sky with drones (drone loss estimates).
SIPRI. (2025, Apr. 28). Trends in World Military Expenditure, 2024 (press release and fact sheet).
U.S. Department of Defense / DIU. (2023–2024). Replicator initiative overview and updates.
U.S. DoD / CDAO. (2024). Task Force Lima executive summary (public release).
U.S. Government reporting. (2024). Cyber workforce vacancy updates.
David O’Neill is a Professor of AI/Policy at the Gordon School of Business, SIAI, based in Switzerland. His work explores the intersection of AI, quantitative finance, and policy-oriented educational design, with particular attention to executive-level and institutional learning frameworks.
In addition to his academic role, he oversees the operational and financial administration of SIAI’s education programs in Europe, contributing to governance, compliance, and the integration of AI methodologies into policy and investment-oriented curricula.
Agent AI Reliability in Education: Build Trust Before Scale
Agent AI Reliability in Education: Build Trust Before Scale

Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
Agent AI is uneven—pilot before student use Start with internal, reversible staff workflows, add human-in-the-loop and logs Follow EU AI Act/NIST; publish metrics; scale only after proof

School leaders should pay attention to a clear contrast: nearly all teens have a smartphone, but agent AI still struggles with multi-step, real-world tasks. In 2024 surveys, 95% of U.S. teens reported having access to a smartphone at home. This infrastructure far outstrips any other learning technology. Meanwhile, cutting-edge web agents based on GPT-4 only completed about 14% of complex tasks in realistic website environments. Recent mobile benchmarks show some improvement, but even the most powerful phone agents completed fewer than half of 65 fundamental functions. This gap between universal access and uneven performance highlights a policy issue in education. Schools feel pressure to provide constant, on-device help, but agent AI can’t be counted on for unsupervised student use. The solution isn’t to ban or to buy these tools unthinkingly. Schools should require proof of reliability in controlled environments, publish the results, and expand use only when solid evidence exists.
Agent AI Reliability: What the Evidence Actually Says
The notable improvements in conversational models mask a stubborn reality: agent AI reliability decreases when tasks involve multiple steps, screens, and tools. For example, errors in SIS lookups or gradebook updates can lead to misrecorded student data. In WebArena, which replicates real sites for forums, e-commerce, code, and content management, the best initial GPT-4 agent achieved a success rate of only 14.41%. In contrast, humans performed above 78%. The failure points may seem mundane, but they are significant—misreading a label, selecting the wrong element, or losing context between steps. For schools, these errors matter. Tasks like gradebook updates, SIS lookups, purchase orders, and accommodation settings require long-term planning. The key measure is not eloquence; it is the reliability of agent AI.
Results on phones tell a similar story, with considerable variation. In November 2025, AI Multiple conducted a field test evaluating four mobile agents across 65 Android tasks in a standardized emulator. The top agent, “DroidRun,” completed 43% of tasks. The mid-tier agent completed 29%, while the weakest managed only 7%. They also showed notable differences in cost and response time. Method note: tasks included calendar edits, contact creation, photo management, recording, and file operations. The test used a Pixel-class emulator with a shared task list under the AndroidWorld framework. While not perfect proxies for schools, these tests reflect reality more than staged demonstrations do. The lesson is clear: reliability improves when tasks are narrow, the user interface is stable, and the required actions are limited. This is the design space that schools can control.

Consumer rollouts illustrate this caution. ByteDance’s Doubao voice agent is launching first on a single device in limited quantities, despite the widespread adoption of the underlying chatbot. Scientific American reports that the system can book tickets, open tabs, and interact at the operating system level, but it remains in beta. Reuters notes its debut on ZTE’s Nubia M153, with plans for future expansion. This approach is not a failure; it is a thoughtful way to build trust. Education should be even stricter, as errors can significantly affect students and staff.
Where Agent AI Works Today
Agent AI reliability shines in internal processes where clear guidelines are in place. This is where education should begin. Business evidence supports this idea. Harvard Business Review’s November 2025 guidance is clear: agents are not suited to unsupervised, consumer-facing work, but they can perform well in internal workflows. Schools have many such tasks. A library acquisitions agent prepares shopping lists based on usage data. A dispatcher agent suggests bus route changes after schedule updates. A facilities agent reorders supplies within a set budget. Each task is reversible, well-defined, and trackable. The agent acts as a junior assistant, not a primary advisor to a student. This distinction is why reliability can improve faster in internal settings than in more public contexts.
Device architecture also plays a significant role. Many school tasks involve sensitive information. Apple’s Private Cloud Compute showcases one effective model: perform as much as possible on the device, then offload more complex reasoning to a secure cloud with strict protections and avenues for public scrutiny. In education, this approach allows tasks such as captioning, live translation, and note organization to run locally. In contrast, more complex planning can run in a secure cloud. The goal is not to endorse one vendor; it is to minimize risk through thoughtful design. By combining limited tools, private execution when possible, and secure logs, agent AI reliability can improve without increasing vulnerability or risking student data.
For student-facing jobs, start with low-risk tasks. Reading support, language aids, captioning, and focused prompts are reasonable initial steps. These tasks provide clear off-ramps and visible indicators when the agent is uncertain. Keep grading, counseling, and financial-aid navigation under human supervision for now. The smartphone's widespread availability—95% of teens have access—is hard to overlook, but access does not equal reliability. A careful rollout that prioritizes staff workflows can still free up time for adults and promote a culture of measuring success before opening up tools for students.
Governance That Makes Reliability Measurable
Reliability should be a monitored characteristic, not just a marketing claim. Schools need clear benchmarks, such as success rates above 80%, to evaluate AI systems effectively. The policy landscape is moving in that direction. The EU AI Act came into effect on August 1, 2024, with rules being phased in through 2025 and beyond. Systems that affect access to services or evaluations are high-risk and must demonstrate risk management and monitoring. Additionally, NIST’s AI Risk Management Framework (2023) and its 2024 Generative AI Profile offer a practical four-step process—govern, map, measure, manage—that schools can apply to agents. These frameworks do not impede progress; they require transparent processes and evidence. This aligns perfectly with the reliability standards we need.

Guidance from the education sector supports this approach. UNESCO’s 2025 guidance on generative AI in education emphasizes targeted deployment, teacher involvement, and transparency. The OECD’s 2025 policy survey shows countries establishing procurement guidelines, training, and evaluation for digital tools. Education leaders can adopt two practical strategies from these recommendations. First, include reliability metrics in requests for proposals and pilot programs: target task success rates, average handling times, human hand-off rates, and error rates per 1,000 actions. Second, publish quarterly reports so staff and families can track whether agents meet the standards. Reliability improves when everyone knows what “good” means and where issues arise.
We also need to safeguard limited attention. Even “good” agents can overwhelm students with notifications. Set limits on alerts for student devices and establish default time windows. If financial policies permit, direct higher-risk agent functions to staff computers on managed networks rather than student smartphones. These decisions are not anti-innovation. They help make agent AI reliability a system-wide property rather than just a model characteristic. The benefits are considerable: fewer mistakes, better monitoring, and increased public trust over time.
A Roadmap to Prove Agent AI Reliability Before Scale
Start with a three-month pilot focused on internal workflows where mistakes are less costly and easier to correct. Good candidates are library purchases, routine HR ticket sorting, and cafeteria stock management. Connect the agent only to the necessary APIs. Equip it with a planner, executor, and short-term memory with strict rules for data retention. Each action should create a human-readable record. From the beginning, measure four key metrics: end-to-end task success rate, average handling time, human hand-off rate, and incident rate per 1,000 actions. At the midpoint and end of the pilot, review the logs. If the agent outperforms the human baseline with equal or fewer issues, broaden its use; if not, retrain or discontinue it. This approach reflects the inside-first logic that business analysts now recommend for agent projects. It respects the strengths and limitations of the technology.
Next, prepare for the reality of smartphones without overcommitting. Devices are already in students’ hands, and integrations like Doubao show how quickly embedded agents can operate when vendors manage the entire stack. However, staged rollouts—including in consumer markets—exist for a reason: to protect users while reliability continues to improve. Schools should adopt the same cautious approach. Keep student-facing agents in “assist only” mode, with clear pathways to human intervention. Route sensitive actions—those that affect grades, attendance, or funding—to staff desktops or managed laptops first. As reliability data grows, gradually expand the toolset for students.
Finally, ensure transparency in every vendor contract. Vendors should provide benchmark performance data on publicly available platforms (e.g., WebArena for web tasks and AndroidWorld-based tests for mobile), the model types used, and any security measures intended to protect legitimate operations. Request independent red-team evaluations and a plan to quickly address performance regressions. Connect payment milestones to observed reliability in your specific environment, not to promises made in demonstrations. In 12 months, the reliability landscape will look different; the right contracts will allow schools to upgrade without starting over. The goal is straightforward: by the time agents interact with students, we need to know they can perform reliably.
We began by highlighting a stark contrast: nearly every teen has a smartphone, yet agent AI reliability in multi-step tasks still falls short. Web agents struggle with long-term tasks; mobile agents perform better but still exhibit inconsistencies; and consumer launches proceed in stages. This reality should not stifle innovation in schools; instead, it should guide it. Focus on where the tools are practical: internal workflows that are reversible and come with clear guidelines. Measure what’s essential: task success, time spent, hand-offs, and incidents. Use existing frameworks. Opt for device patterns that prioritize privacy and focus. Publish the results. Only when data prove that agents perform reliably should we allow students to use them. The future of AI in education isn’t about having a new assistant in every pocket. It’s about having reliable tools that give adults more time and provide students with efficient services. Because we have demonstrated, transparently, that agent AI reliability meets the necessary standards.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Apple Security Engineering and Architecture. (2024, June 10). Private Cloud Compute: A new frontier for AI privacy in the cloud.
Apple Security Engineering and Architecture. (2024, October 24). Security research on Private Cloud Compute.
European Commission. (2024, August 1). AI Act enters into force.
Harvard Business Review. (2025, November 25). AI Agents Aren’t Ready for Consumer-Facing Work—But They Can Excel at Internal Processes.
OECD. (2025, Mar). Policies for the digital transformation of school education: Results of the Policy Survey on School Education in the Digital Age.
Pew Research Center. (2025, Jul 10). Teens and Internet, Device Access Fact Sheet.
Reuters. (2025, December 1). ByteDance rolls out AI voice assistant for Chinese smartphones.
Scientific American. (2025, December 1). ByteDance launches Doubao real-time AI voice assistant for phones.
UNESCO. (2025, April 14). Guidance for generative AI in education and research.
Zhou, S., Xu, F. F., Zhu, H., et al. (2023). WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv.
AI Multiple (Dilmegani, C.). (2025, November 6). We tested mobile AI agents across 65 real-world tasks.
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
How to Make Industrial Policy Work Now
Success means steady investment and capacity Milestones and blended finance sustain momentum Run a live portfolio and fix bottlenecks

Every policymaker should keep seventy-five billion in mind.
After Hegemony: Why Japan's New Pluralism Could Reshape Learning as Much as Politics
LDP hegemony breaks; multipartism rises Japan political diversification is reshaping education Act now: language support, student metrics, local compacts

Japan's politics are not just shifting to the right; they are changing dramatically
Europe's EU Innovation Gap Is Relative and Fixable
Europe lags by scale, not ideas: U.S.
Getting Old Before Getting Rich: Why “Aging and Productivity” Will Reshape Education and Growth
Aging erodes productivity and growth Migration buys time, not productivity—see Singapore Youthful regions gain only if they scale learning, health, and adoption

In the economies from the Baltics to the Balkans, the
Truncated Supply Chains, Local Damage: Why Italy's Margin for Error Is Thinner
Supply bottlenecks cut euro-area output ~2.6%; Italy’s hit is larger Foreign-input reliance and SME limits slow substitution, raising costs in factories and classrooms Priorities: multi-sourcing, energy diversification, and digital tracking for public buyers and SMEs

Stop Calling It a Free Lunch: Why Biotech Spillovers Make Everyone Safer
Biotech knowledge spillovers cut global wait times for lifesaving therapies Rich countries gain when diffusion is designed, priced, and measured—not blocked Universities and funders should hard-wire reciprocity, open methods, and cross-border teams
