Make Thinking Visible Again: How to Teach in an Age of Instant Answers
Make Thinking Visible Again: How to Teach in an Age of Instant Answers

Published
Modified
AI doesn’t make students “dumber”; low-rigor, answer-only tasks do Redesign assessments for visible thinking—cold starts, source triads, error analysis, brief oral defenses Legalize guided AI use, keep phones out of instruction, and run quick A/B pilots to prove impact

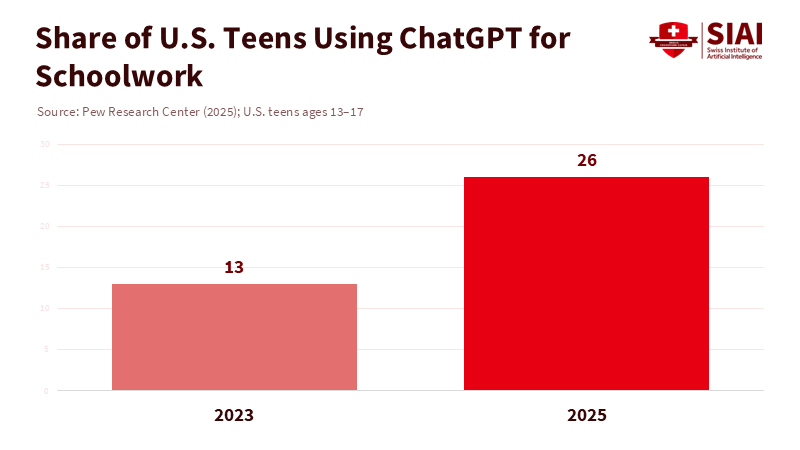
The most alarming number in today's classrooms is 49. Across OECD countries in PISA 2022, students who spent up to an hour a day on digital devices for leisure scored 49 points higher in math than those who were on screens five to seven hours a day. This gap approaches half a standard deviation, even after accounting for background differences. At the same time, one in four U.S. teens, or 26%, now uses ChatGPT for schoolwork. This is double the percentage from 2023. In simple terms, students are losing focus as finding answers has become effortless. When a system makes it easier to get a decent sentence than to think deeply, we can expect students to rely on it. The problem is not that kids will interact with an intelligent machine; it's that schoolwork often demands so little from them when such a machine is around.
The Wrong Debate
We often debate whether AI will make kids "dumber." This question overlooks the real issue. When a task can be completed by simply pasting a prompt into a chatbot, it is no longer a thinking task. AI then becomes a tool for cognitive offloading—taking over recall, organization, and even judgment. In controlled studies, people often rely too much on AI suggestions, even when contradictory information is available; the AI's advice overshadows essential cues. This behavior isn't due to children's brains but reflects environments that prioritize speed and surface-level accuracy over reasoning, evidence, and revision. To address this, we need to focus less on blocking tools and more on rebuilding classroom practices so that visible thinking—clear reasoning that is visible, open to questioning, and assessable—becomes the easiest option.
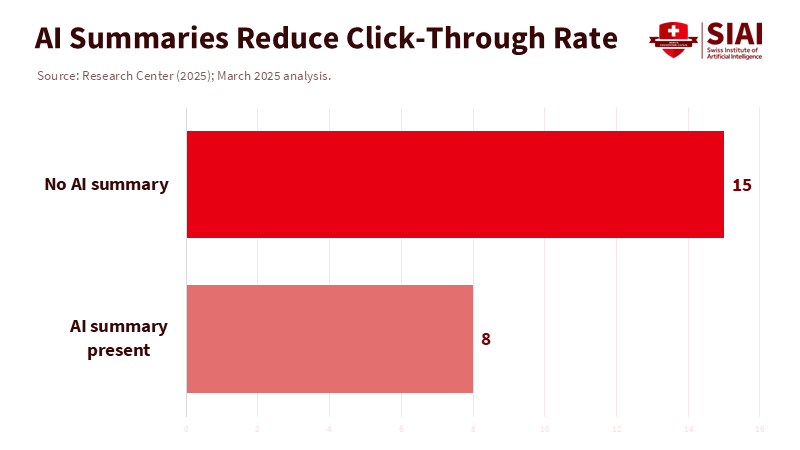
We also need to acknowledge the changes in the information landscape. When Google displays an AI summary, users click on far fewer links; many stop searching entirely after reading the summary. This "one-box answer" habit transfers to schoolwork. If a single synthetic paragraph seems trustworthy, why bother searching for sources, comparing claims, or testing counterexamples? Students are not lazy; they respond rationally to incentives. If the first neat paragraph gets full credit, the demand for messy drafts and thoughtful revisions goes away—exactly where most learning happens. We cannot lecture students out of this pattern while keeping assessments that encourage it. We must change the nature of the work itself.
The phone debate serves as a cautionary tale. Bans can minimize distractions and improve classroom focus. The Netherlands has reported better attention after a national classroom ban, and England has provided guidance for stricter policies. However, research on the relationship between grades and mental health is mixed. Reviews show no consistent academic increase from blanket bans. To put it simply, reducing noise is helpful, but it doesn't enhance learning. A school can ban phones, yet still assign tasks that a chatbot can complete in 30 seconds. If we only focus on control, we may temporarily address symptoms while leaving the main learning problem—ask-and-paste assignments—untouched.
Build Cognitive Friction
The goal is not to make school anti-technology; it's to make it pro-thinking. Start by creating cognitive friction—small, deliberate hurdles that make getting unearned answers challenging and earned reasoning rewarding. One method is implementing "cold-start time": the first ten minutes of a task should involve handwritten or whiteboard notes capturing a plan, a claim, and two tests that could disprove it. AI can support brainstorming later, but students must first present their foundation. During a pilot of this approach in math and history departments last year (about 180 students across two grade bands), teachers noted fewer indistinguishable responses and richer class discussions. Note: since there was no control group, these results should be seen as suggestive; we tracked argument quality based on rubrics, not final grades. Available research supports this change: meta-analyses indicate positive effects of guided AI on performance while cautioning against unguided reliance. The takeaway is to design effectively, not deny access.
Next, create prompts that are complex for AI and easier for humans. Ask students for an answer plus their rationale: what three counterclaims they considered and the evidence they used to dismiss them. Require students to utilize triads of sources—two independent sources that don't cite each other and one dataset—and then ask them to reconcile any differences in the data. In science, place more weight on error analysis than on the final answer; in writing, assess the revision memo that explains what changed and why. In math, have students verbally defend a solution for two minutes to a randomly chosen "what if" scenario (like changing a parameter or inverting an assumption). These strategies make thinking visible and turn simple answer-chasing into a losing tactic. They also align with the field's direction: the OECD's "Learning in the Digital World" pilot for PISA 2025 emphasizes computational thinking and self-regulated learning—skills that will endure despite the rise of automation.
Finally, use AI as a counterpoint. Provide every student with the same AI-generated draft and assess their critiques: what is factually correct, what is plausible but lacking support, what is incorrect, and what is missing? The psychology at play is significant. Research shows that people often over-trust AI suggestions. Training students to identify systematic errors—incorrect citations, flawed causal links, hidden assumptions—fosters a healthy attitude of trust but verify. Teachers can facilitate this with brief checklists and disclosure logs: if students use AI, they must provide the relevant content and explain how they verified the claims. Note: This approach maintains academic integrity without requiring punitive oversight and can be implemented on a large scale. As districts increase AI training for teachers, the ability to implement these routines is rapidly improving.
Policy Now, Not Panic
At the system level, the principle should be freedom to use, yet the duty to demonstrate. Schools need clear policies: students may use generative tools as long as they can show how the answer was derived in a way that is traceable and partially offline. This requires rubrics that reward planning work, oral defenses, and revision notes, along with usage disclosures that protect privacy while ensuring transparency. UNESCO's 2023 global review states clearly: technology can help with access and personalization, but can also harm learning if it substitutes for essential tasks; governance and teaching should take the lead. A policy that allows beneficial uses while resisting harmful ones is more sustainable than outright bans. It also views students as learners to be nurtured, not issues to be managed.
Regarding phones, aim for a managed quiet rather than a panicked response. Research shows distractions are common and linked to worse outcomes; structured limitations during instructional time are justifiable. However, complete bans should be accompanied by redesigned assessments; otherwise, we may applaud compliance while critical skills lag. The OECD's 2024 briefs offer valuable insights: smartphone bans can reduce interruptions; however, the effectiveness of learning improvements depends on enforcement and effective teaching methods. Countries are making changes: the Netherlands has tightened classroom rules and reports better focus, while England has formalized schools' powers to limit and confiscate phones when necessary. Districts should implement effective strategies—clear rules and consistent enforcement—while creating lessons that make phones and chatbots irrelevant to grades because those make grades dependent on reasoning.
We also need prompt evidence, not years of discussion. School networks can conduct simple A/B tests in a single term: one group of classes adopts the cognitive-friction strategies (cold starts, triads, oral defenses, AI critiques), while another group continues with existing methods; compare reasoning and retention based on rubrics one month later. Note: keep the stakes low, pre-register metrics, and maintain intact classes to prevent contamination. Meanwhile, state agencies should fund updates to assessments—developing AI-resistant prompts and scoring guidelines along with teacher training. The good news is that we aren't starting from scratch; controlled studies and meta-analyses have already shown that guided AI can enhance performance by improving feedback and revision cycles. Our task is to tie these gains to judgment habits rather than outsourcing.
Anticipating potential pushback is essential. Some may argue that any friction is unfair to students who struggle with writing fluency or multilingual learners who need AI support. The key is to distinguish between support and shortcuts. Allow AI for language clarity and brainstorming outlines, but evaluate argument structure—claim, evidence, warrant—through work that cannot be pasted. Others might say oral defenses are logistically demanding. They don't have to be: two-minute "micro-vivas" at random points, once per unit, scored on a four-point scale, reveal most superficial work with minimal time commitment. A third concern is that strict phone rules could affect belonging or safety. In this case, policies should be narrow and considerate: phones should be off during instruction but accessible at lunch and after school, with exceptions made for documented medical needs. The choice is not between total freedom and strict control. It is about creating classrooms that focus on visible thinking rather than just submitted text.
What about the argument that AI makes us think less? The evidence is mixed by design: in higher education, AI tutors and feedback tools often improve performance when integrated into lessons. At the same time, experiments reveal that people can overtrust confident but incorrect AI advice, and reviews highlight risks to critical thinking due to cognitive offloading. Both outcomes can coexist. The pivotal factor is the design of the task. If a task requires judgment across conflicting sources, tests a claim against data, and demands a transparent chain of reasoning, AI becomes an ally rather than a substitute. If the task asks for a neat paragraph that any capable model can produce, outsourcing wins. Our policy should not aim to halt technology. It should increase the cost of unearned answers while decreasing the effort needed for earned ones.
A final note on evidence: PISA correlations do not establish causation, but the direction and magnitude of these associations—especially after adjusting for socioeconomic factors—match what teachers observe: increased leisure screen time at school and peer device use correlate with weaker outcomes and reduced attention. Conversely, structured technology use, including teacher-controlled AI tutors, can be beneficial. The reasonable policy response is to minimize ambient distractions, ensure visible reasoning, and use AI for feedback rather than answers. This framework is now implementable and can be audited by principals, making it understandable to families.
Return to the number 49. It does not suggest "ban technology." It indicates that as leisure screen time in school increases, measured learning decreases. It shows that attention is limited and fragile. With a world filled with instant answers, we risk short-circuiting the very skills—argument, analysis, revision—that education aims to strengthen. The solution is attainable. Make thinking the only route to earning grades through cold starts, counterclaims, source triads, error analysis, and brief oral defenses. Use AI where it accelerates feedback, but requires students to demonstrate their reasoning process, not just deliver their conclusions. Keep phones out during instruction unless they serve the task; create policies that permit beneficial uses and disclose them. If we do this, the machine will no longer serve as a crutch for weak prompts but as a tool that clarifies strong thinking. In a decade, let the takeaway be not that AI made students "dumber," but that schools became more thoughtful about what they ask young minds to achieve.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Campbell, M. et al. (2024). Evidence for and against banning mobile phones in schools: A scoping review. Journal of Children's Services Research.
Department for Education (England). (2024). Mobile phones in schools: Guidance.
Deng, R., Benitez, J., & Sanz-Valle, R. (2024). Does ChatGPT enhance student learning? A systematic review. Computers & Education.
EdWeek (reporting RAND). (2025, Apr. 8). More teachers than ever are trained on AI—are they ready to use it?
Klingbeil, A. et al. (2024). Trust and reliance on AI: An experimental study. Computers in Human Behavior.
OECD. (2024a). Students, digital devices and success. OECD Education and Skills.
OECD. (2024b). Technology use at school and students' learning outcomes. OECD Education Spotlights.
Pew Research Center. (2025, Jan. 15). About a quarter of U.S. teens have used ChatGPT for schoolwork—double the share in 2023.
Pew Research Center. (2025, July 22). Google users are less likely to click on links when an AI summary appears in the results.
Reuters. (2025, July 4). Study finds smartphone bans in Dutch schools improved focus.
UNESCO. (2023). Global Education Monitoring Report 2023: Technology in education—A tool on whose terms?
Wang, J. et al. (2025). The effect of ChatGPT on students' learning performance: A meta-analysis. Humanities and Social Sciences Communications.
Zhai, C. et al. (2024). The effects of over-reliance on AI dialogue systems on student learning: A systematic review. Smart Learning Environments.