When the Buffer Runs Thin: Vietnam’s Public-Sector Ceiling and the Quiet Shift of Korean Capital
Vietnam’s public sector still drives too much of the economy, squeezing buffers and deterring investors Korean firms are diversifying as energy shortages, tariff shocks, and policy delays raise risk Cutting state dependence and upgrading power and skills can keep capital anchored

Europe's Inflation Problem Is a Budget Problem, and Schools Will Feel It
Credible budgets cut inflation Rising defense and debt threaten school funding Multi-year fiscal plans can protect education

In May 2010, Greece initiated a significant one-year budget cut in
"No Reason, No Model": Making Networked Credit Decisions Explainable
"No Reason, No Model": Making Networked Credit Decisions Explainable

Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
Network credit models aren’t “inexplicable”—they can and must give faithful reasons Adopt “no reason, no model”: require per-decision reason packets and auditable graph explanations Regulators and institutions should enforce this operational XAI so that denials are accountable and contestable

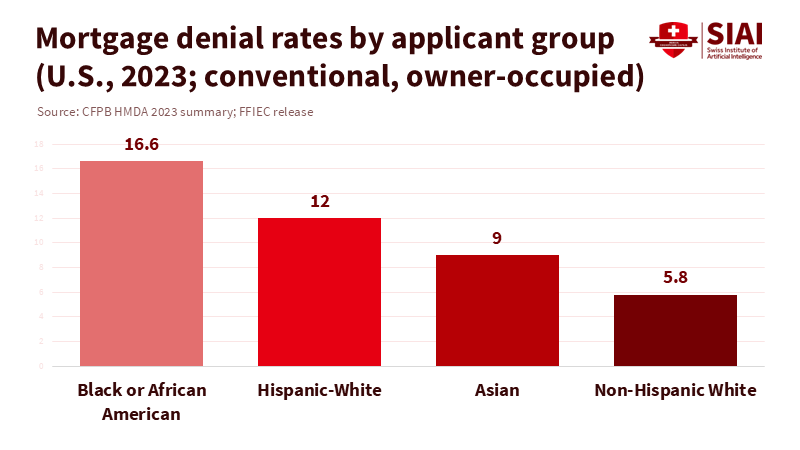
Consider this striking statistic: in 2023, the denial rate for Black applicants seeking conventional, owner-occupied home-purchase mortgages was 16.6%, nearly three times the 5.8% rate for non-Hispanic White applicants. These figures, reported under HMDA across millions of applications, underscore a significant disparity. As lenders shift from traditional scorecards to deep-learning models that comprehend relationships, these denials increasingly stem from network patterns—such as co-purchases, shared devices, and merchant clusters—rather than from three simple factors. Some institutions may label these systems as 'inexplicable.' However, the law does not permit complexity as an excuse. U.S. creditors are still required to provide specific reasons for denials. Europe's AI Act now categorizes credit scoring as a 'high-risk' activity, introducing phased requirements for logging and transparency. The central policy question isn't about accuracy versus explanations. It's whether we allow 'the network made me do it' to shield us from explanation, responsibility, and learning—especially in credit markets related to education that determine who completes degrees, starts programs, or maintains operations at community colleges.
We should change how we discuss this issue. Graph neural networks and other network models are not magical; they consist of linear transformations and simple nonlinear functions that communicate through connections. Near any given decision, these systems act like nested, piecewise-linear regressions. This means you can identify the critical variables and subgraphs, even if it requires more work than simply stating "debt-to-income ratio too high." The real issue is how operational: will lenders create systems that convert these technical explanations into clear, understandable reasons at the time of decision? The urgency and necessity of this issue cannot be overstated. Or will we accept a lack of clarity because it is easier to claim the networks cannot be made clear?
From Rule-Based Reasons to Graph-Based Reasons
For many years, adverse-action notices resembled a short checklist. When a loan was denied, institutions typically cited three reasons: insufficient income, a short credit history, and low collateral value. This approach worked because older underwriting models were additive and largely separable by feature. Network models change the process, not the obligation. When a GNN flags a loan, it might be because the applicant is two steps away from a group of high-risk merchants or because the transaction patterns mimic those that failed at a specific bank-merchant-device combination. Those are still reasons. To say "the model is inexplicable" confuses workflow choices with mathematical impossibility. Regulation B under ECOA requires creditors to provide "specific reasons" for denials. The CFPB has repeatedly warned that vague terms or generic reasons do not meet the law's standards—even for AI. Regulators play a crucial role in ensuring that the reasons provided are clear, understandable, and meet the law's standards. A regulator should hear "GNN" and say, "Fine—show me the subgraph and features that influenced the score and translate them into a consumer-friendly reason."
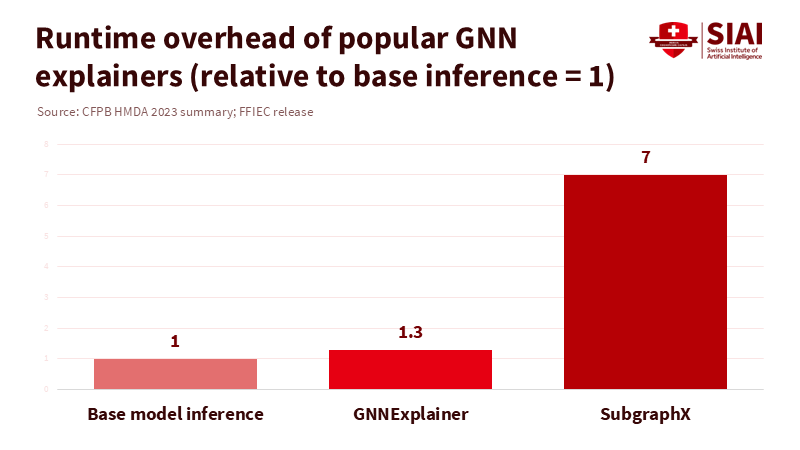
Technically, we know how to achieve this. Methods like LIME and SHAP create local surrogate models that approximate the complex model in the vicinity of a single decision. Integrated Gradients connects a prediction to input features along a path from a baseline. For graphs, GNNExplainer identifies a compact subgraph and feature mask that most influences the prediction. At the same time, SubgraphX uses Shapley values to find an explanatory subgraph with measured accuracy. Recent benchmarks in Scientific Data show that subgraph-based explainers produce more accurate and less misleading explanations than gradient-only methods. Newer frameworks, such as GraphFramEx, aim for standardized evaluations. None of this comes at no cost—searching for subgraphs can take several times longer than a single forward pass—but cost and complexity do not equal impossibility. Compliance duties do not lessen just because GPUs are expensive.
Making Networks Clear: Auditable XAI for Credit
The primary policy objective should be operational clarity: reasons that align with the model and are comprehensible to people, generated at the time of decision, and retained for audits. A practical framework consists of three key components. First, every high-stakes model should generate a structured' reason packet' that pairs feature attributions with an explanatory subgraph, outlining key connections, edges, and motifs that influenced the decision. Second, enforce 'reason passing' throughout the credit stack. Suppose a fraud or identity risk model impacts the underwriting process. In that case, it must transfer its reason packet to ensure the lender cannot simply attribute the decision to unnamed upstream risks. Third, compile reason packets into compliant notices: map features to standard reason codes when possible and add brief, clear network explanations when necessary (for instance, 'Recent transactions heavily concentrated in a merchant-device group linked to high default rates'). Vendors already provide XAI toolchains to facilitate this; regulators should mandate such systems before lenders implement network models at scale.
Methodological details are crucial. How reliable are these reasons? Subgraph-based explainers can be validated by removing the identified subgraph and checking the decline in the model's risk score. Auditors should sample decisions, run validations, and ensure that reasons are not just plausible but also practical in counterfactual scenarios. How quickly can this operate? SubgraphX has been reported to take multiple times the base inference time; in practice, lenders can use quicker explainers for every decision and reserve heavier audits for a select sample, with strict real-time requirements for adverse actions. How do we ensure privacy? Reason packets should be modified for notices, using terms like 'merchant category group' rather than specific store names, while keeping full details for regulators. The EU AI Act already mandates significant logging and documentation for high-risk systems. Maintaining accuracy is fundamental, but without reliable, testable reasons, accuracy becomes unsubstantiated—and that represents a governance failure.
The regulatory framework is already present. In the U.S., the CFPB has clarified that companies using complex algorithms must provide specific, accurate reasons for adverse actions; "black box" complexity is not acceptable. SR 11-7's Guidance on model risk still applies: banks must validate models, understand their limits, and monitor performance changes—responsibilities that easily extend to the explainability aspect. Europe's AI Act is scheduled to take effect in August 2024, with its obligations phased in over a period of time. Credit scoring is categorized as high-risk, triggering requirements for risk management, data governance, logging, transparency, and human oversight. Critical milestones are set for 2025-2027. NIST's AI Risk Management Framework offers organizations a structured approach to integrating XAI controls into their existing policies. The direction is clear: if you cannot explain it, you should not use it for important decisions, such as credit for students, teachers, and school staff.
Education stakeholders have a unique role because credit influences access, retention, and school finances. Rising delinquencies and stricter underwriting—seen in the first ongoing drops in average FICO scores since the financial crisis—push for quicker risk decisions in student lending, tuition payment plans, and teacher relocation loans. Faculty and administrators can promote model understanding in their curricula, develop credit-risk projects where students implement and audit GNNs, and collaborate with local lenders to test reason-passing systems. Schools that manage emergency aid or income-share agreements should request decision-specific reason packets from vendors rather than just receiving PDFs of ROC curves. Regulators and accreditors can encourage a shared set of reason codes that covers patterns from graphs without becoming vague. If we teach students to ask "why," our institutions should demand the same when an algorithm says "no."
A Practical Mandate: No Reason, No Model
The guiding principle for policy and procurement should be this: no model should influence a credit decision unless it can provide reasons that people can understand, contest, and learn from. "No reason, no model" is more than a phrase; it is a compliance standard that can be incorporated into contracts and regulatory examinations. Lenders would ensure that every model in the decision chain generates a reason packet, that these packets are stored and auditable, and that consumer-facing notices clearly communicate those packets in terms aligned with the model's logic. Regulators would verify a sample of denials by independently running explainers and counterfactuals to confirm the accuracy of the bank's system. If removing the identified subgraph does not alter the score, then the "reason" is not a valid reason. This method respects proprietary models while rejecting obscurity as a business practice.
Predictably, there will be objections. One is cost: subgraph explanations can take longer, and building the necessary systems is complex. Yet compliance costs are mandatory. The time required for advanced explainers is manageable—seconds, not days—especially if lenders use varied strategies (quick local attributions for all decisions and deeper subgraph audits for a statistically valid sample). Another concern relates to intellectual property, arguing that revealing subgraphs discloses trade secrets. This is a distraction. Consumer notices don't need to show raw graphs; they must deliver transparent and trustworthy statements. Regulators can access the whole packet under confidentiality agreements. The final concern is performance: some argue that enforcing explainability might lower accuracy. However, benchmarks indicate that reliable explanations lead to better learning, and nothing in ECOA or the AI Act allows sacrificing people's right to reasons for a slight improvement in AUC. The responsibility to provide valid reasons lies with those who oppose them, not with those who demand them.
What should we do now? Regulators should provide Guidance that puts "no reason, no model" into practice for credit and related decisions, with clear testing procedures and sampling plans. They should also coordinate with NIST's AI RMF to specify requirements for documentation, resilience checks, and reporting of explanation failures, not just prediction mistakes. Lenders should create model cards that include metrics on explanation accuracy and subgraph validation tests, committing to reason-passing in vendor agreements. Universities and professional schools should establish "XAI for finance" programs that audit real models under NDAs and develop open-source reason packet frameworks. Civil society can assist consumers in challenging denials by utilizing the logic in those packets, translating complex graphs into practical steps ("spread transactions across categories," "avoid merchant groups known to relate to charge-offs"). This approach fosters governance that educates while making decisions.
A 16.6% denial rate in a significant market segment is more than just a number; it reflects the power dynamics at play. Network models can channel that power through connections too subtle for human observation. That is why we must insist on explanations that simplify complexity into accountable language. U.S. law already mandates this. European law is gradually introducing it. The science of explainability—local surrogate models, attributions, and subgraph identification—makes it achievable. When lenders claim "the network is inexplicable," they are not describing an unchangeable truth; they are choosing convenience over rights. We can choose differently. We can demand reason packets, reason passing, and accountable notices. We can train the next generation of data scientists and regulators to create and evaluate them. Suppose an organization asserts that its model cannot provide explanations. In that case, the solution is straightforward: that model should not be part of the market. No reason, no model.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Agarwal, C., et al. (2023). Evaluating explainability for graph neural networks. Scientific Data. https://doi.org/10.1038/s41597-023-01974-x.
Consumer Financial Protection Bureau. (2022, May 26). The CFPB acts to protect the public from black-box credit models that use complex algorithms.
Consumer Financial Protection Bureau. (2023, Sept. 19). Guidance on credit denials by lenders using artificial intelligence.
Consumer Financial Protection Bureau. (2024, July 11). Summary of 2023 data on mortgage lending (HMDA).
European Commission. (2024–2026). AI Act regulatory framework and timeline.
FICO. (2024, Oct. 9). Average U.S. FICO® Score stays at 717.
Lundberg, S., & Lee, S.-I. (2017). A unified approach to interpreting model predictions (SHAP).
Lumenova AI. (2025, May 8). Why explainable AI in banking and finance is critical for compliance.
National Institute of Standards and Technology. (2023). AI Risk Management Framework (AI RMF 1.0).
Skadden, Arps. (2024, Jan. 24). CFPB applies adverse action notification requirement to lenders using AI.
U.S. Federal Reserve. (2011). SR 11-7: Supervisory Guidance on model risk management.
Ying, R., et al. (2019). GNNExplainer: Generating explanations for graph neural networks.
Yuan, H., et al. (2021). On explainability of graph neural networks via subgraph explorations (SubgraphX).
Turner Lee, N. (2025, Sept. 23). Recommendations for responsible use of AI in financial services. Brookings.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.

















From Cheaper Capital to Smarter Risk: Capital Market Integration Sparks Europe’s Quality Revolution
Europe must shift from cheap capital to quality allocation Skilled investors channeling funds to R&D lift productivity and GDP far more than lower spreads Deliver it with a safe asset, harmonised disclosure, scale-up capital, and university pipelines that measure quality

When “looking through” looks away: inflation’s surprise, welfare loss, and what schools needed from monetary policy
Forecast errors turned a supply shock into larger welfare losses; “look-through” amplified them Make look-through state-contingent with public shock decompositions and automatic triggers Shield schools via indexed budgets, pooled energy hedging, and efficiency investments that cut volatile costs

Teach the Robots, Keep the Republic
Robots should be Europe’s first responder to ageing, handling routine work so people focus on human-only tasks Education must pivot fast—stackable credentials for robot operation, integration, and safety Use migration where irreplaceable in care and teaching; automate the rest to stabilize growth

The Perils of the Now: How to Stop Real-Time Data from Making Policy Worse
Real-time data can mislead because overload and autocorrelation turn noise into policy Treat fresh numbers as estimates: blend vintages (replay-style), weight by revision risk, and require causal identification Teach revision-aware literacy and measure decisions by how well they age, not how fast they react

The Dollar's Self-Defeat and Why Schools Will Pay for It
The dollar’s slide is a self-inflicted wound from tariffs, aid cuts, and fiscal drift Market confidence punished these choices, raising costs for campuses and squeezing budgets Fix it with boring credibility: a real fiscal path, rules-based trade, and strategic re-engagement

If You Can't Insure It, You Can't Permit It
If You Can't Insure It, You Can't Permit It
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
AVs must pass an insurance test—no policy, no deployment Permits should hinge on corridor-specific coverage and quarterly audited claims data Keep driver-assist and driverless distinct; if it’s not insurable at market rates, it’s not permissible

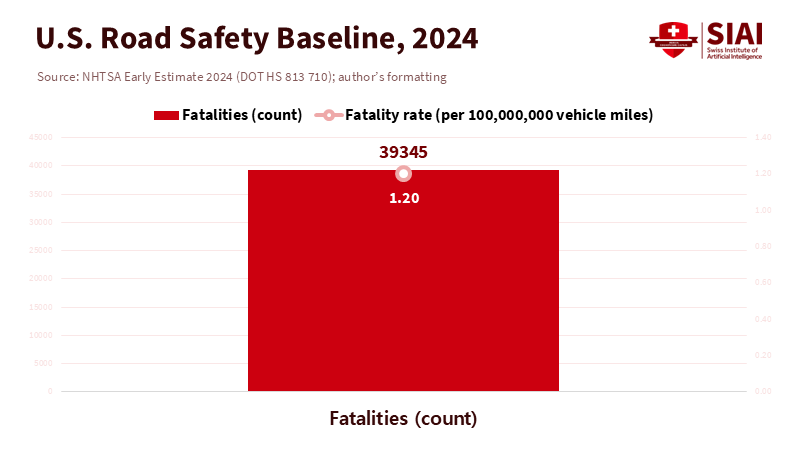
The most critical number in this debate is not the number of lidar beams or neural-network parameters; it's 39,345. This is the National Highway Traffic Safety Administration's early estimate of U.S. road deaths in 2024. While this number has decreased from 2023, it still represents about 1.20 fatalities for every 100 million vehicle miles traveled. Even in a so-called "good" year, this is an unacceptable baseline risk that we address every day through insurance. If self-driving technology is truly safer, it should be easy to prove this in a domain that relies on quantifiable risk: insurance. If an actuary cannot price your system without public support or legal protection, it doesn't deserve to operate at scale. Insurability is not a minor detail in regulation; it is the market's test of credibility. If we can't ensure it, we shouldn't let it go into operation.
From Liability Theory to Priceable Risk
To make that test concrete, we need to start with liability assignments that can actually be priced. The United Kingdom has progressed the most, with Parliament establishing a scheme that puts primary responsibility on motor insurers while an automated system is in use. This allows insurers to seek recovery from the manufacturer as needed. This clarity, set out in the Automated and Electric Vehicles Act and updated through the Automated Vehicles Act 2024, turns a philosophical debate into a contract that the market can handle. If a crash happens while the system is in "automated mode," the policy responds. If a software defect is to blame, the insurer can seek compensation from the developer. This is a key regulatory change because it outlines the losses for which insurers are accountable and under what conditions. In the United States, we, by contrast, have an inconsistent mix of tort laws and state-level pilot regulations; federal safety reporting exists, but liability clarity is lacking. A reasonable standard is straightforward: no large-scale deployment without a policy that a licensed insurer is willing to underwrite at market rates for the specific automated use-cases, such as a driverless robotaxi operating within a designated area or highway-only automation with a human supervisor.
Underwriters do not price hopes or ambitions; they price exposure. They care about a company's loss history, not its confidence. A growing set of data sources can help clarify the situation. California's disengagement and mileage datasets, although imperfect, still provide valuable insight into operational reliability. NHTSA's Standing General Order requires the timely reporting of crashes involving advanced driver assistance (Level 2) and automated driving systems (Levels 3-5), finally creating a minimum standard for evidence. None of these datasets is flawless, but they are vital for the credibility calculations actuaries need to determine whether past performance can inform future loss ratios. The aim is not to achieve absolute certainty; it is to establish insurability with precise confidence intervals and identifiable exclusions.
The Current Signal from Insurance Data Is Mixed
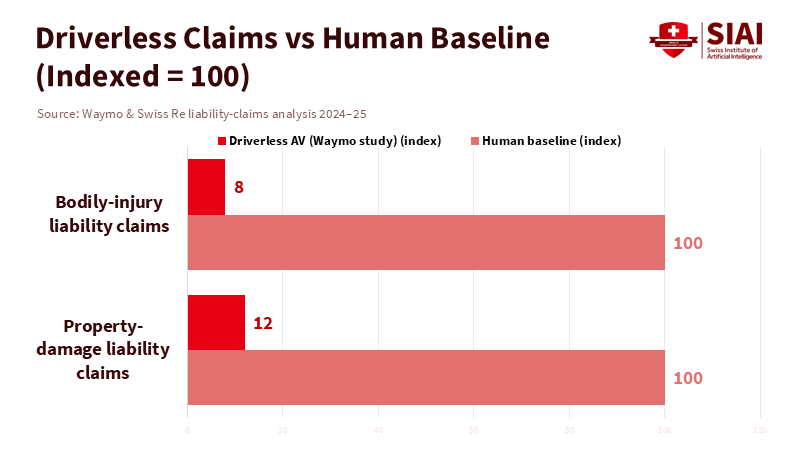
If we look at where insurers focus—on claims, not social media—the signals point in two directions. On the bright side, Swiss Re's analysis of 25.3 million fully driverless miles operated by Waymo in Phoenix, San Francisco, Los Angeles, and Austin reveals significant reductions in liability claims compared to baselines from over 200 billion human-driven miles: about an 88% drop in property damage claims and a 92% drop in bodily injury claims. Nine property-damage claims and two bodily-injury claims over that exposure are a small sample. Still, it represents the type of evidence that can shift underwriters from "maybe" to "what premium reflects that improvement?" This isn't just a marketing claim; substantial data from a major reinsurer support it. The findings may not apply to every technology stack or city, but they demonstrate that risk can be measured and priced when operations are well defined.
However, the negative signals are equally important. During the same time frame, the most widely recognized "self-driving" brand in the U.S. rebranded its offering to "Full Self-Driving (Supervised)," highlighting that a human must remain accountable. Regulators have consistently pursued investigations and scrutinized recalls, with official reports linking the company's Level 2 system to several fatal crashes. This does not end the conversation—Level 2 is fundamentally different from driverless Level 4—but it stresses that not all automation should be treated the same. A supervised assist feature relying on human fallback is not a proof of autonomy for insurance; it is a traditional auto policy that comes with new risks of misuse and defects. The firm's labeling change is an acknowledgment of this reality and serves as a reminder that insurability hinges on the mode and operational design domain, not just branding.
Method matters. Claims-frequency comparisons must account for exposure and be matched based on context: time of day, weather, road type, crash reporting standards, and average annual miles per vehicle. The Waymo-Swiss Re study attempts to address this by benchmarking against both general and "latest-generation" human-driver standards. Still, even then, a reinsurer will adjust the improvement until the confidence intervals tighten. Meanwhile, NHTSA's 2024 fatality rate serves as a reminder that the human baseline is not static. If human risk is declining—1.20 fatalities per 100 million miles in 2024, with early 2025 trends looking better—then the standard for an AV system to prove superiority rises. This is precisely why a market standard should be adaptable: a moving benchmark that insurers can and must adjust as the human baseline changes.
A Practical Insurability Standard for AV Pilots
So what does an "insurance-first" standard look like in practice? It starts with specificity. Policies must be clearly defined for a declared operational design domain (ODD): streets and times, weather conditions, fallback behavior, and whether a paid safety operator is present. Underwriters should provide an expected claims frequency and severity range for that ODD, along with a stated limit and retention, and confirm reinsurance support. An acceptable entry requirement could involve an A-rated insurer ready to issue primary coverage at typical market margins; transferring at least 30% of gross risk to an A-rated reinsurer; and implementing a parametric stop-loss that activates at predefined frequency or severity thresholds based on a human-driver baseline. The policy should consider software updates as endorsements that change risk, necessitating new rates when the technology stack undergoes significant changes. This is not excessive regulation; it ensures capital believes in the safety case enough to price it accurately.
The second pillar is data sharing that justifies those prices. The baseline is what California and NHTSA already require: reports on disengagements, miles driven, and crashes with standardized information. The next step is obtaining insurer-grade exposure and loss data: insured miles segmented by ODD, near-miss indicators (hard braking and significant lateral movement beyond set thresholds), third-party claims with injury coding, and repair cost distributions by component. Regulators should mandate that, as a condition for renewing permits, operators publish anonymized quarterly exposure and claims tables verified by an independent party. This framework won't make immature systems safe but will make unsafe systems costly, while rewarding mature systems with lower costs. That is the right incentive.
To align permitting with market signals, cities or states should approve driverless services only when insurers are willing to provide coverage without extra legal protections beyond standard measures. Public authorities can create "risk corridors" for pilots, co-funded with operators committed to transparency. At the same time, the UK model, where insurers act as first payers, offers a valuable framework for the U.S.
Concerns about insurers being gatekeepers are misdirected, as they already play this role due to the nature of capital. Although early-stage technologies may lack loss history, specific thresholds for each corridor can provide clarity. Insurance markets may shift, but stable data sharing and pilot testing can maintain standards without relaxing regulations.
Education should focus on practical risk engineering over theoretical ethics, fostering skills in areas like safety-case development and actuarial theory. Policymakers should budget for independent data audits as essential to AV permitting, promoting better measurement as a vital subsidy.Messaging must differentiate between levels of automation. Levels 2 and 3 are driver-assistance tools covered by traditional policies, while Level 4 requires distinct insurance based on specific usage rules.
By 2024, improvements in driverless operations are expected to prompt a shift towards formal testing, with the expectation that by 2026, all jurisdictions will mandate clearly priced primary policies alongside reinsurance for each operational design domain (ODD). This approach acknowledges where autonomy is safer while maintaining regulatory standards.The insurability test is not about reducing regulation or providing moral exemptions; it ensures accountability. Cities may subsidize premiums for data collection, but with strict limits. Ethical considerations around mobility and urban planning remain crucial as deployment progresses.
The starting point and the endpoint are the same number. Thirty-nine thousand three hundred forty-five is the floor we are trying to break. Suppose autonomy can lower that number in real corridors, in real weather, with real claims. In that case, insurers will rush to get involved, and regulators will see a strong market signal that allows for expansion without any drama. If autonomy cannot be insured without public backing, then we have our answer for now: we need more engineering, more measurement, and stricter ODDs until the actuarial math changes. The only rule we need to state—and the one we should enforce strictly—is simple: if you can't insure it, you can't allow it. That rule aligns incentives, protects the public, and gives the technology a fair chance to prove itself where it matters—on the balance sheet of risk.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Association of British Insurers (2024). Insurer requirements for automated vehicles. Retrieved from abi.org.uk (PDF).
Brookings Institution (2025, August 8). Setting the standard of liability for self-driving cars. Retrieved from brookings.edu.
California DMV (2023). Autonomous vehicle disengagement and mileage reports. Retrieved from dmv.ca.gov.
European Commission (2025, March 18). EU road fatalities drop by 3% in 2024, but progress remains slow. Retrieved from transport.ec.europa.eu.
MarketWatch Guides (2025). How will self-driving cars be insured in the future? Retrieved from marketwatch.com.
NHTSA (2025, April). Early estimate of motor vehicle traffic fatalities in 2024 (DOT HS 813 710). Retrieved from crashstats.nhtsa.dot.gov.
NHTSA (n.d.). Standing General Order on crash reporting. Retrieved from nhtsa.gov.
Reuters (2024, August 30). Life on autopilot: Self-driving cars raise liability and insurance questions and uncertainties. Retrieved from reuters.com.
Shoosmiths (2024, June 17). Automated Vehicles Act: spotlight on liability. Retrieved from shoosmiths.com.
Tesla (n.d.). Full Self-Driving (Supervised) subscriptions. Retrieved from tesla.com/support.
VICE (2025, September 9). Tesla is dropping the dream of human-free self-driving cars. Retrieved from vice.com.
Waymo & Swiss Re (2024, December 19). Comparison of liability claims for Waymo driverless operations vs. human baselines (25.3M miles). Waymo blog and technical PDF. Retrieved from waymo.com/safety and storage.googleapis.com.
Zurich Insurance (2025). Driverless vehicles and the future of motor insurance. Retrieved from zurich.co.uk.
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Not Guinea Pigs, Not Glass Domes: How to Design AI Toys That Help Babies Learn
Not Guinea Pigs, Not Glass Domes: How to Design AI Toys That Help Babies Learn

Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.
Published
Modified
babies is inevitable—focus on smart guardrails, not bans Mandate strict privacy, proven developmental claims, and designs that boost caregiver–infant serve-and-return Advance equity with vetted, prompt-only co-play tools in public settings and firm vendor standards

A child born today will likely spend their early years in a home where a voice assistant is always listening. In the United States, about one in three people aged 12 and older have a smart speaker. Many of these owners have more than one device placed around the house, where babies nap, babble, and play. At the same time, the global market for connected toys is racing toward tens of billions of dollars by the end of the decade. These facts reveal an uncomfortable reality: whether we like it or not, infants will grow up around artificial intelligence. However, the potential of AI toys is not to be feared. Our choice is not between exposure and purity. We must decide between passive gadgets that collect data and impair human interaction, and well-regulated tools that have the potential to enhance it. If we want the latter, we must establish rules now that prioritize what matters most in the first thousand days: responsive human conversation and touch.
The Right Question: Replace or Relate?
The main issue is not whether a device is "AI." The problem is whether it replaces or relates. Language and cognitive skills in the early years depend on "serve-and-return" exchanges—those quick conversations between a caregiver and a child. Multiple studies show that the number of exchanges, rather than the total number of words a child hears, is linked to stronger language development and later success. These findings are based on observational audio recordings and neuroimaging studies that link conversational exchanges to both white-matter connectivity and language outcomes, with consistent effects across various research designs. For policy, it is essential to note that a bot talking to a baby is not the same as a tool that encourages a parent to interact with that baby. We should evaluate AI toys based on whether they effectively promote conversations and shared attention between humans, not on their ability to "engage a child."
This distinction also explains why screens continue to pose a problem for infants. Pediatric guidance is clear: for children under 18 months, avoid screen media except for video chatting. For toddlers, focus on high-quality content that adults watch with children, and set clear limits. The physiological findings align with this behavioral guidance. Babies learn best from responsive and interactive cues—voices that respond to their sounds, faces that match their expressions, and hands that share visible objects. A static video, no matter how well-made, cannot provide the same feedback. Pediatric recommendations are based on a combination of observational studies, parent coaching trials, and developmental neuroscience, emphasizing context rather than a universal time limit. This is not an argument against all technology. The standard is simple: if a device cannot show that it increases responsive human interaction, it does not belong in an infant's daily routine.
Guardrails That Enable, Not Ban
We should reject the false choice between fear and permissiveness. The way forward is to establish specific rules that distinguish between helpful and harmful designs. This will provide a sense of reassurance and security to parents, caregivers, policymakers, educators, toy manufacturers, regulators, and researchers. Privacy and security must come first, as trust is essential. Independent researchers have demonstrated that many "smart toys" transmit behavioral data to companies, often with inadequate encryption. This is unacceptable for any product aimed at children, especially babies. Regulators are making some progress. In the United States, new rules on children's privacy now require stricter consent and limit the monetization of kids' data. In Europe, the AI framework and existing children's design code focus on data reduction and best-interest principles, while the Digital Services Act prohibits targeted advertising to minors. These changes do not resolve every question about connected toys. Still, they establish a legal baseline: no silent data logging, no unclear user profiles, and no manipulative designs to increase screen time for toddlers. Procurement leaders in early-childhood systems should adopt this baseline immediately.
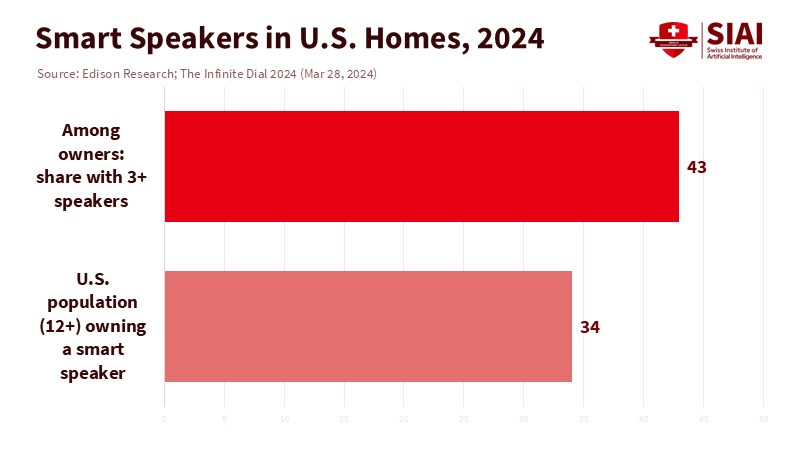
The second rule concerns claims. If a product advertises "language boost," it should be able to substantiate that claim. This involves conducting independent trials using validated measures, including tracking conversational exchanges through full-day audio recordings, measuring parent-reported outcomes against standardized tools, and incorporating stress or sleep measures when relevant. We do not need decade-long studies to take action, but we do need studies large enough to eliminate placebo effects and publication bias. Devices that monitor health require even stricter standards. Recent regulatory approvals have begun to separate true medical devices from consumer gadgets. That is progress, but the guidance for pediatric care remains straightforward: families should not depend on home monitors to lower the risk of SIDS. The proper path for AI-based infant health tools is narrow and supervised—through clinicians—and the claims should be limited to what the device is cleared to do. This emphasis on evidence-based claims will empower parents, caregivers, policymakers, educators, toy manufacturers, regulators, and researchers to make informed decisions about AI toys for infants.
The third rule is the design for co-play. An AI toy suitable for infants should function more like a "language mirror" than a talking advertisement. It should respond to a child's vocalizations and encourage the parent to identify what the baby is touching or to sing a timely song. It should quickly turn off unless an adult is present. It should work on-device by default, upload nothing without explicit permission for each use, and clearly explain—in simple terms—what data is stored, the purpose, and the duration. These principles are based on pediatric practices that emphasize parent coaching and legal requirements focused on data minimization and the best interests of children. They can support innovation by shifting the goal from "engagement time" to "human interactions per hour."
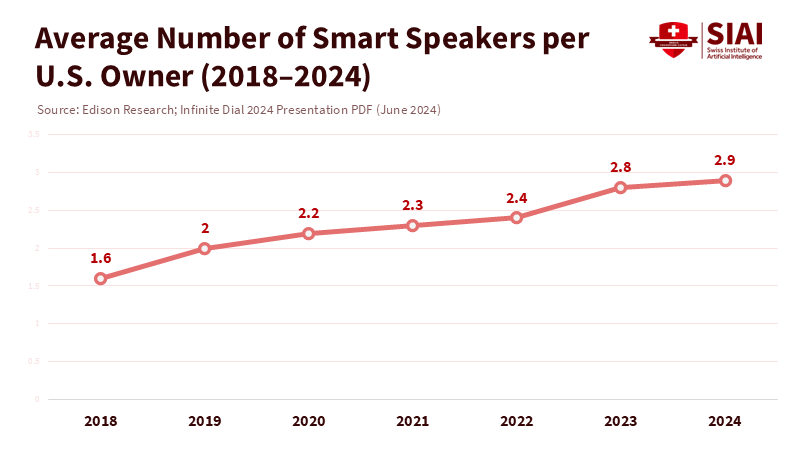
The final rule addresses equity. Wealthier families are more likely to buy structured toys or access parenting classes and speech therapy. If AI products become high-end items—or if "free" versions exploit data while paid versions keep it safe—we risk widening gaps in early language development. Public spaces, such as libraries or community health centers, can change this dynamic by providing supervised "co-play corners" equipped with evaluated devices and caregiver training. The key outcome to monitor is not how cleverly a toy speaks, but whether it helps busy adults communicate more often and effectively with their children.
What We Should Build Next
With these rules in place, we can consider future possibilities. Imagine a soft toy without a screen, equipped with a few touch sensors, and an on-device speech model designed to prompt rather than perform. The toy listens as a baby babbles while holding a soft block. Instead of lecturing, it signals the closest adult: "I hear sounds—want to try 'ba-ba-block' together?" The toy then goes silent. If the adult responds, it records the exchange and periodically offers another prompt based on the infant's movements—a tap song, a peekaboo rhythm, or a shared label for what the child holds. Over time, the parent receives a summary on their phone—not dopamine-driven "streaks," but patterns in their interactions with tips based on research. This represents AI as a conversational enhancer, not a substitute caregiver.
Now imagine a toddler's reading nook in a child care center. A small speaker sits beside board books. When an adult opens a book, the system listens for key words and suggests questions: "Where did the puppy go?" "Can you find the red ball?" The assistant does not narrate the entire story; it only supports interactive reading. Trials with preschoolers show that AI partners can, in specific settings, help with question-asking and engagement in stories at levels close to those with human partners. The transition to infants is not straightforward—infants require gestures and turn-taking more than questions—but the research is emerging. A responsible project would initially conduct pilot studies in high-need communities, designed with input from educators and parents, monitoring conversational exchanges and caregiver stress over several months.
Health devices will pursue a different direction. Here, the value is not "smarter parenting" but clinical supervision and peace of mind in specific circumstances: for a preterm infant just discharged, a baby with respiratory problems, or a family caring for a child on supplemental oxygen. Regulators have started approving infant pulse-oximetry devices for specified uses. That is helpful for those narrow cases. However, for healthy babies, the safest and most effective investments remain unchanged: practicing safe sleep, supporting breastfeeding when possible, ensuring smoke-free environments, and coaching caregivers. Policies should keep these priorities clear. Consumer wearables should not suggest they can prevent tragic outcomes when they cannot.
Educators and administrators have a fundamental role beyond procurement. Early-childhood programs can incorporate "talk-first tech" into staff training. A brief training session can show how to use a prompt-only toy to encourage naming, turn-taking, and gesture games with one-year-olds, while gradually reducing the device's role. Directors can require vendors to provide straightforward "evidence labels" detailing the product's aims, the studies backing those claims, and the data the device collects. State agencies can support this initiative with small grants for independent, community-based assessments, rather than relying solely on vendor-funded trials. Universities can contribute by standardizing outcome measures and making analysis methods public. The goal is to establish a feedback loop that drives product improvement by facilitating meaningful interactions between adults.
Parents also need clarity in a sea of marketing. A simple guideline can help: if a company cannot provide independent evidence that its product increases human interactions or caregiver responsiveness, view its claims as mere marketing. Another rule: if the device cannot function with most capabilities without an account, internet connection, or broad recording permissions, it is not designed with your child's best interests at heart. These guidelines are practical, not punitive. Babies do not need the latest features. They need consistent prompts that turn everyday moments—like feeding, changing, or bath time—into opportunities for language-rich interactions. The best AI remains in the background and lets human voices take the lead.
Policies can solidify these norms into action. New children's privacy rules in the United States now make it harder to monetize kids' data without explicit parental consent. Europe's AI regulations and the U.K.'s Children's Design Code focus on the best interests and data minimization. Enforcers should prioritize connected toys and baby monitors as early tests; assessments should include code reviews and real-world data analysis, rather than relying solely on checklists. Consumer labels can be helpful, but enforcement is crucial for changing the underlying incentives that drive these behaviors. If companies understand that they must validate their claims and protect their data, products will be developed with a focus on co-play and safety by design, rather than relying on shortcuts for growth.
A Better Ending
Let's return to where we began: a home where a voice assistant is always active and a child is just starting to explore the world. We will not eliminate these devices from our living rooms any more than we removed radios or smartphones from our lives. But we can change their role around babies. We can enforce privacy rules that prevent silent data collection. We can demand proof for both developmental and clinical claims. We can create toys that encourage adults to engage with children rather than interfere with them. We can focus on equity, ensuring that beneficial tools are available first where they are most needed. If one in three households already has a conversational device, the responsible course is to use that presence as an opportunity to deepen human connection, not replace it. The choice is in our hands. Let's develop AI that assists adults in doing what only they can: enriching the early years filled with conversation, touch, and trust.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
American Academy of Pediatrics. (2024, Feb. 1). Screen time for infants. Retrieved from aap.org.
American Academy of Pediatrics. (2024, Feb. 26). The role of the pediatrician in the promotion of healthy digital media use in children. Pediatrics.
American Academy of Pediatrics. (2025, May 22). Screen time guidelines. Retrieved from aap.org.
Edison Research. (2024, Mar. 28). The Infinite Dial 2024.
European Commission. (2022, Oct. 27). The EU's Digital Services Act.
European Parliament. (2025, Feb. 19). EU AI Act: first regulation on artificial intelligence.
Grand View Research. (2024/2025). Connected toys market size, share & trends.
Information Commissioner's Office (U.K.). (n.d.). Age-appropriate design code (Children's Code).
Owlet. (2023, Nov. 9). FDA grants De Novo clearance to the Dream Sock. Contemporary Pediatrics.
Romeo, R. R., et al. (2018). Beyond the 30-million-word gap: Children's conversational experience is associated with language-related brain function. Developmental Cognitive Neuroscience. See also Romeo et al., 2021 review.
University of Basel. (2024, Aug. 26). How smart toys spy on kids: what parents need to know.
U.S. Federal Trade Commission. (2025, Jan. 16). FTC finalizes changes to children's privacy rule.
World Health Organization. (2019, Apr. 24). To grow up healthy, children need to sit less and play more.
Catherine McGuire is a Professor of Computer Science and AI Systems at the Gordon School of Business, part of the Swiss Institute of Artificial Intelligence (SIAI). She specializes in machine learning infrastructure and applied data engineering, with a focus on bridging research and large-scale deployment of AI tools in financial and policy contexts. Based in the United States (with summer/winter in Berlin and Zurich), she co-leads SIAI’s technical operations, overseeing the institute’s IT architecture and supporting its research-to-production pipeline for AI-driven finance.