The early-2020s inflation surge was driven by energy and supply shocks, not monetary excess
Energy costs set off pricing cascades and productivity losses across key sectors
Policy should prioritize supply resilience over demand tightening
The Third AI Stack Is a Hope, Not a Strategy: Why Europe and Korea Can’t Catch an entrenched US–China Duopoly
Picture
Member for
1 year 8 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
The third AI stack is a political ambition, not an industrial reality
China’s open-source push wins users, not hardware supremacy
Europe and Korea must focus on interoperability and skills, not full-stack rivalry
Between August 2024 and August 2025, Chinese open-model developers accounted for roughly 17% of global Hugging Face downloads—surpassing U.S. developers for the first time. That single data point captures a truth and a misreading at once: China has achieved scale in open-source and community adoption, but scale in downloads is not the same as an independent, competitive compute and platform stack. The talk of a third AI stack—a European or Korean alternative that will sit beside the U.S. and China—mixes aspiration with wishful thinking. Open-source diffusion buys influence and the breadth of users. It does not automatically produce the high-performance silicon, the global cloud infrastructure, or the developer lock-in that underpin dominant AI platforms. If decision-makers and instructors in Europe and Korea make strategy from comfort, they will misread the extent of capital, talent, and time required to translate downloads into durable industrial power.
Why the "third AI stack" is a mirage
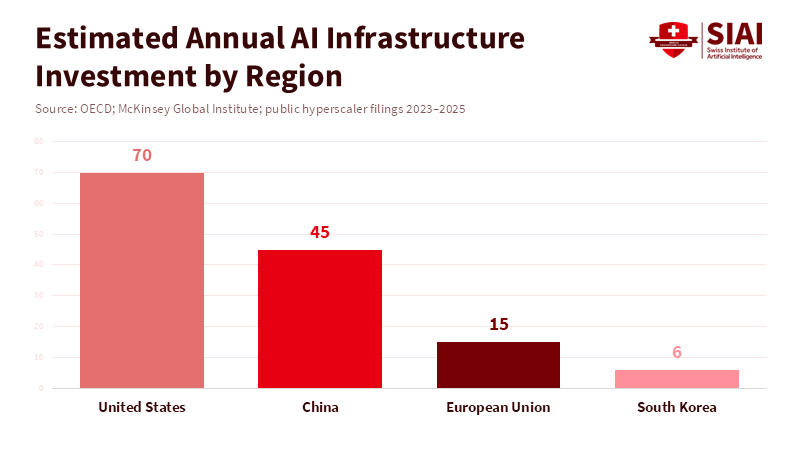
When we refer to the third AI stack, we mean a self-sustaining, region-led combination of hardware, software standards, and large-scale cloud services that can engage global customers and developers independently of U.S. or Chinese ecosystems. That is a very high bar. Building it requires three mutually reinforcing assets at an industrial scale: advanced silicon, a large installed base of high-end cloud nodes, and widely adopted developer tools and runtimes. Europe and Korea have pockets of strength—excellent researchers, healthy public funding, leading semiconductor firms in Korea—but they lack the simultaneous depth across all three pillars. Export controls and supply-chain frictions have altered incentives. The U.S. controls high-end GPU exports and has layered licensing reviews, slowing the direct flow of the world’s fastest inference hardware; this constrains some Chinese compute access but does not erase the huge lead that proprietary GPU frameworks and optimized software stacks already enjoy. Those controls alter incentives but do not shrink the technical gap overnight.
Capital matters more than rhetoric. To catch up after a decade of lag requires orders of magnitude more investment than typical national AI grants provide. Training the largest models needs sustained petaflop-years of compute and the advanced interconnects and memory hierarchies that only a few vendors can supply. Korea’s chipmakers can and do make excellent GPUs for consumer and embedded markets; competing at datacenter-class AI compute needs sustained foundry access, advanced packaging, and validated software toolchains that are expensive and time-consuming. Likewise, European cloud operators can focus on sovereign clouds and regulation-friendly offerings, but winning global developer mindshare requires low friction, competitive pricing, and a thriving community-driven ecosystem—things that privilege incumbents with broad scale. In short, the gap is structural, not simply financial or political.
Figure 1: Global AI competition is shaped by sustained capital at scale; Europe and Korea operate an order of magnitude below the US–China frontier.
Finally, we should separate user-facing openness from platform control. China’s success in open-model downloads shows how well governments and firms can seed ecosystems when proprietary hardware is constrained. But hosting, inference, and production deployments still congregate where performance, reliability, and developer convenience converge. Until an alternative stack meets those baseline expectations on cost and latency, enterprises and researchers will keep one foot in the U.S. or Chinese ecosystems, and hedging will win over wholesale migration.
How China’s open-source play reshapes the “third AI stack” narrative
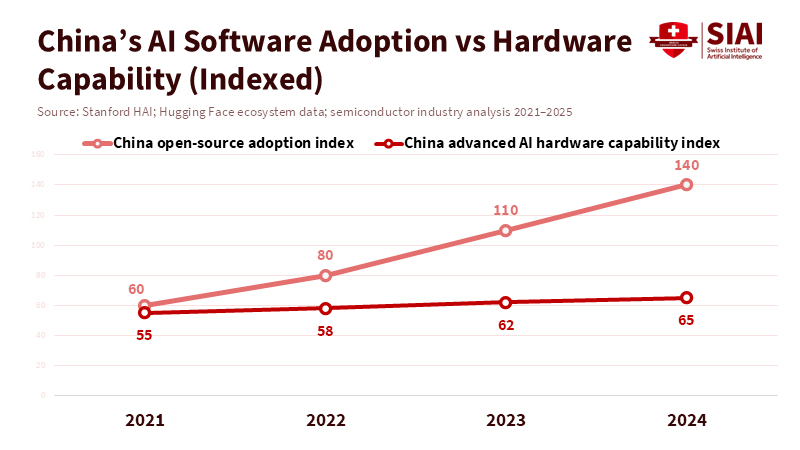
China’s open-weight push is clever and consequential. By freely releasing model weights and encouraging derivative works, Chinese firms have multiplied global usage and created an optics advantage in the Global South and among developers who prize openness. That movement is not trivial: an ecosystem of lighter models, efficient condensation techniques, and developer tools can make AI useful inside constrained settings. This becomes a form of platform-building that competes on accessibility rather than raw exaflops. The result is a two-track competition: one axis is the top-tier compute race; the other is broad-based software adoption. China leads the latter. That matters for standards, formats, and the flows of talent and data that shape long-term software interoperability.
Figure 2: China’s open-source models scale globally through adoption, while domestic hardware capability lags at the frontier.
But this competitive win has limits. Open models need inference capacity to power commercial services at scale. When the highest-performance accelerators are absent or restricted, the economics and latency of large-scale services change. China’s response has been to develop indigenous chips and high-volume data center capacity. Early chips are serviceable and serve many workloads well, but independent analyses suggest they lag top-tier Nvidia chips in raw throughput and capability—sometimes by margins that matter for the most demanding training and inference uses. The engineering deficit combines node-level performance gaps with deficits in software maturity: compiler toolchains, distributed training orchestration, and optimized kernels are hard to replicate quickly. Engineers can reduce gaps over time, but these gaps interact with supply chains and standards in ways that compound the incumbent's advantage.
Another realistic implication: China’s open strategy has bought it a different kind of influence. If Chinese models, libraries, and runtimes become the de facto norms in many emerging markets, they shape developer expectations and institutional procurement. Europe and Korea can still set rules about data governance, privacy, and ethical uses. But norm-setting without compatible infrastructure is incomplete. The countries that combine standards with market-simulacra—deployable clouds, certified hardware, and developer incentives—will have more leverage. The open-source approach gives China a broad base from which to project standards through use; it is not yet a claim on high-end performance, but it is a claim on adoption and default formats.
Policy choices for educators, administrators, and policy makers in a US–China duopoly
Educatorshave to adapt curricula to the new terrain. Teaching neural network architecture without hands-on experience on modern accelerators is increasingly theoretical. Universities and vocational programs should prioritize access to a mix of cloud credits that expose students to both leading commercial stacks and popular open-source stacks used in real-world settings. That means negotiating partnerships to rotate cloud access, funding GPU hours for labs, and building coursework that evaluates compromises between performance and cost. Policymakers should treat computer access as infrastructure—like labs or telescopes—rather than an ephemeral grant. Subsidizing access to testbeds, investing in software toolchains, and underwriting open benchmarking projects will have outsized returns compared to one-off research grants. When students learn to optimize for latency and cost on real hardware, they graduate with industrially relevant skills rather than abstract knowledge.
Administrators and procurement officials face a choice matrix. They can double down on national sovereignty—buying local hardware and mandating local deployment—or pragmatically hedge by instrumenting multi-cloud and multi-stack interoperability. The latter is the wiser posture. Insisting on a pure “third AI stack” that isolates education systems and public services risks lock-in to immature platforms that will carry higher long-run operating costs. Instead, public institutions should require interoperability layers, fund open benchmarks, and sponsor translator tooling so models and datasets can port across stacks. That approach safeguards the regulatory agency while keeping operational performance within tolerable bounds. It also creates an exportable product: governments that can demonstrate safe, portable, and efficient AI deployments will have a stronger voice in global standards negotiations.
We must also face hard political-economic questions. China’s decision to prefer domestic stacks is a deliberate infant-industry strategy. If those domestic engineers succeed, the global configuration shifts; if they fail, China will still have bought time for its software standards to entrench in pockets of the world. Either outcome imposes costs and benefits on education systems. For universities and think tanks, the practical implication is clear: invest in cross-sectional analysis and applied deployments now. Trial projects that benchmark similar services on different stacks, publish the methods and results, and teach students to reason about trade-offs. In short, convert geopolitical uncertainty into a pedagogical advantage.
From wishful thinking to workable strategy
The third AI stack continues as a compelling political slogan. It promises national autonomy and dignity. It will not, however, spring into being because leaders declare it. The evidence is simple: open-model downloads are a form of influence but not an immediate substitute for exascale compute, top-shelf hardware, or mature software stacks. Europe and Korea can and should aim for partial sovereignty—investing in secure clouds, supporting open toolchains, and training engineers across multiple stacks—but the clearer path to impact lies in pragmatic interoperability, targeted industrial investment, and educational reform. We should treat compute and developer access as public goods, not prizes to be hoarded. That means real budgets for testbeds, transparent benchmarks, and curriculum revisions that privilege operational competence. If policymakers act with that realism, educators will graduate learners who can move between stacks rather than waiting for a mythical third column to appear. The world will be safer and more plural if alternative stacks grow by winning customers with clear trade-offs, not by political proclamation. The opening statistic matters because it highlights where influence is currently accumulating; our job now is to convert that influence into durable, responsible capacity—practically, cheaply, and with an eye on standards, not slogans.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Chin, C. L. (2026). Standards are the new frontier in the US–China AI competition. East Asia Forum. CSIS. (2025). The limits of chip export controls in meeting the China challenge. Center for Strategic and International Studies. Financial Times. (2025). China leapfrogs the US in the global market for 'open' AI models. Financial Times. Hugging Face / Stanford HAI analysis. (2025). China's diverse open-weight AI ecosystem and its policy implications. Stanford HAI briefing. International analysis of chip performance. (2025). The H20 problem: inference, supercomputers, and US hardware. Independent analysis. Reuters. (2026). NVIDIA AI chip sales to China stalled by US security review. Reuters.
Picture
Member for
1 year 8 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Europe’s problem is not a lack of firms, but a system that keeps them small
An EU federation is best understood as industrial infrastructure, not constitutional ambition
Without enforced market integration, Europe will keep exporting its champions instead of building them
Misaligned climate policy shifts emissions across borders instead of cutting them globally
Uneven rules push firms to relocate production rather than invest in deep decarbonisation
Only coordinated incentives can stop carbon leakage and restore policy credibility
Cheap solar has reshaped the growth logic for power-scarce economies
Solar-first strategies deliver faster, cheaper energy than nuclear in most cases today
The challenge is timing: build solar now and scale complexity only when demand rises
Light for Sale: Reframing the Data Center Community Impact as a Power and Trust Problem
Picture
Member for
1 year 8 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
Published
Modified
AI data centers are straining local power systems
Donations cannot replace enforceable community agreements
Real benefits require binding commitments to the grid
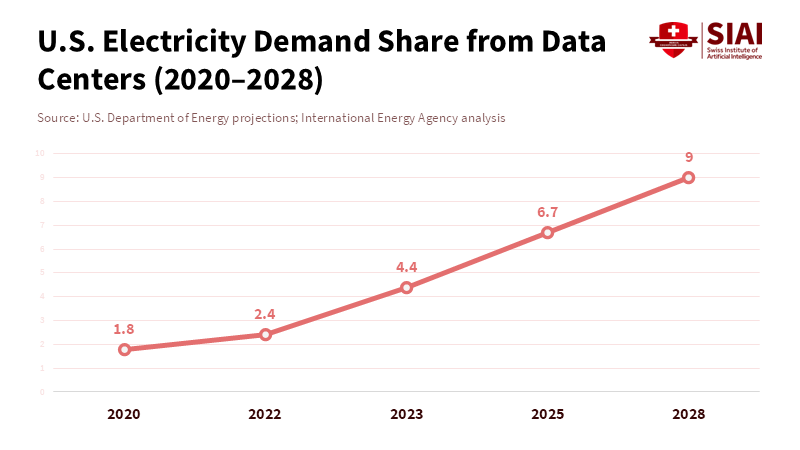
In 2023, U.S. data centers consumed about 4.4% of the country's electricity. Some predict this will go up a lot in the next five years. Now, 4.4% might not sound like much, but it's enough to make any mayor, school head, or utility company think hard about those energy bills and possible power shortages in the winter. Here's the thing: when companies build these huge AI data centers, they're not merely setting up servers. They're changing the local energy landscape, the town's negotiating position, and public trust in the system. So, those donations to schools, promises of jobs, and fancy community events? They're nice, but they don't replace solid, legally binding agreements that address energy and the community's needs directly. If we keep treating these donations as the only factor in data center community impact, we're letting private deals obscure risks everyone shares. This is about changing the way we talk about this issue. Community benefits are important, but only if they're tied to clear, verifiable commitments on energy, jobs, and governance. This way, we protect regular people from being left in the dark.
Why Charity Isn't Enough
We all know the usual routine: A big company promises money for schools, says they'll train local people, and maybe builds a nice public space. These things do help. Schools get stuff, some people get jobs, and some groups get more money. But these are often one-time things that don't really solve the main problem: the huge amount of electricity needed to run AI and the decisions about how to reliably get that energy. In the U.S., data centers are using more and more electricity. It's more than a possibility anymore. Government reports and international energy groups all show that this demand is going way up. When we treat community benefits as just for show, rather than as legally tied to energy outcomes, we're making a deal where the community takes on the risks while the companies get good publicity. This difference between what looks good and what's really required is the main thing we need to fix.
What happens because of this? Places with many AI data centers experience higher energy demand, less available energy, and higher prices when there are issues with energy delivery or fuel. Energy companies and studies warn of real risks: winter peaks, cold weather, and fuel shortages can disrupt the system when these large new energy users come online. The usual response – thank-you ceremonies and awards – doesn't do anything to make more electricity, improve energy delivery, or create reserve energy options. A real data center community impact plan connects those gifts to long-term investments that change the energy supply: promises of energy capacity, on-site energy generation with strict rules about pollution and reliability, and legal support for energy grid upgrades. These are very different from just handing out donations.
Figure 1: Data centers are moving from a marginal load to a system-level stressor within a single decade.
Looking at the Money Behind the Gifts
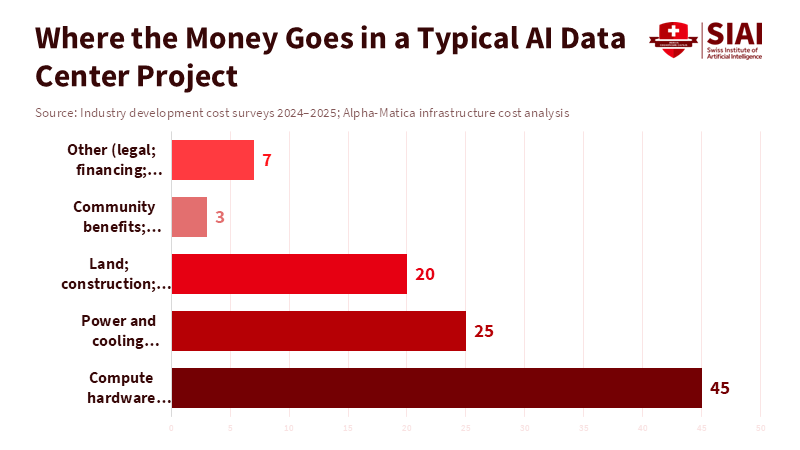
To create enforceable deals, we must understand the costs and what matters in negotiations. Building an AI data center can cost hundreds of millions, sometimes over half a billion, for a typical-sized facility. Equipment, especially high-powered computer processors and energy infrastructure, is a high cost up front.
Figure 2: Community donations remain financially marginal compared to hardware and power investments.
That's why companies talk about local benefits: jobs and donations are cheap compared to long-term investments in energy. But these gestures can't replace what the community needs to keep the lights on. When a data center needs new energy sources or major upgrades to the energy grid, the community has to wait years for approvals and construction before it sees any benefit. And the community's trust is easily broken if the only visible benefits are temporary and cannot be enforced.
Smart community benefit agreements can change this situation. Instead of accepting a one-time payment for approval, local governments should require commitments contingent on specific conditions: starting operations only when the energy grid is ready, contributing to energy delivery or generation, and clear job-training programs with defined employment and wage targets.
This changes who the community is in the data center community impact, from people who watch the PR to people who sign contracts with the right to check on things. It's important to remember that many companies don't have unlimited money. Hardware costs and financial cycles limit their cash. That means getting creative with money – using public and private funds, long-term energy contracts, or even local bonds – can assist in bridging the gap while keeping the risks public and the benefits enforceable.
Governance, Fairness, and the Energy Grid
Saying that community benefits should be part of a contract isn't simply a technical thing. It's concerning fairness. Voluntary donations often go to visible places – schools, parks, sports fields – while less obvious problems happen elsewhere: small businesses paying higher rates, renters living near power stations, or communities dealing with construction issues.
Binding agreements can specify how benefits are shared, require community monitoring, and fund investments that reduce local risks, such as helping people make their homes more energy-efficient or providing targeted assistance with energy bills. The more that deals link company actions to scheduled grid improvements, the less likely it is that a whole area will have to cut back on energy use to keep the system working. This puts the community at the center of the discussion, not on the sidelines.
To make this happen, companies, energy providers, and local leaders need to share responsibility for planning over longer periods than companies usually plan. Data center community impact means creating new systems: regional groups that include community representatives, monitoring systems that can be enforced, and rules that stop operations if energy reliability goals aren't met. These aren't unusual things. They're similar to environmental or labor agreements used in other areas. Using them here would turn donations into tools that lock in investments in energy capacity and reliability. In short, charity becomes powerful when it's combined with enforceable engineering.
Addressing the Criticisms: Profit, Speed, and Competition:
Two common complaints will come up. First, this will slow investment and cost jobs. Second: Tougher deals will send projects to other countries or more friendly states during the AI boom. Both deserve honest answers. According to a report from Solar Power World, nearly 2,600 gigawatts of new power generation and energy storage are now seeking grid interconnection across the United States, showing that setting permit requirements in stages that align with business schedules and ensuring that grid upgrades are on track can help protect jobs and communities while supporting project progress. It ensures that the benefits occur at the same time as the impacts.
On the second point, the notion that any U.S. restriction will cause us to lose ground to competitors is exaggerated. The world needs secure, well-regulated data centers, and that favors places that combine reliability with clear rules. Investors want predictability, and communities want certainty. A report from Data Center Watch notes that in the past three months alone, 20 data center projects worth $98 billion faced delays or blockage due to local opposition. This highlights the importance of reducing political risk through careful planning and addressing community concerns to improve the chances of long-term project success.
There's also a technical argument that companies often use: We'll solve this with on-site gas generation or batteries. Many companies are using on-site fuels or combined ways to meet immediate needs. This can reduce short-term stress on the grid, but it can also increase pollution if natural gas is used without strict limits. Recent reports indicate that more people are using natural gas for short-term reliability, raising environmental concerns that communities must consider. Good community benefit agreements include conditions about pollution and efficiency, and a clear plan for adding renewable energy and storage as the energy grid improves. The goal isn't to ban all temporary solutions, but to make them conditional, transparent, and connected to progress toward cleaner energy.
A Policy for Light and Trust
If 4.4% seems abstract, imagine a winter evening when the city asks people to use less electricity because a few new data centers are using a lot of power. That's the risk we take when we stop the conversation at charitable giving. A real data center community impact policy treats benefits as binding agreements that protect public resources and share the benefits fairly. Cities and counties should require operations to happen in stages based on verified grid upgrades, demand financial plans which support long-term energy capacity, and insist on governance systems that give residents the right to check on things and have real ways to fix problems.
To be clear: donations, training programs, and community projects are good things. But they only become fair when they're part of enforceable agreements that precede, not follow, company operations. We can welcome new ideas without losing power. The choice isn't between jobs and reliability. It's between careful, enforceable partnerships and the slow loss of citizen trust when charity tries to fill the gaps that infrastructure investment should cover. Let's create rules that make the benefits of AI real and lasting, not just a show.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Department of Energy. (2024). DOE Releases New Report Evaluating Increase in Electricity Demand from Data Centers. U.S. Department of Energy. International Energy Agency. (2024). Energy and AI: Energy Demand from AI. IEA. Lancaster City. (2025). Lancaster AI Hub: Community Benefits Agreement (Draft). City of Lancaster (PA). National Association for the Advancement of Colored People (NAACP). (2026). Community Benefits Agreement Template. NAACP. Reuters. (2026, January 28–29). Forecast record electricity demand to test largest US power grid; US faces growing risks of power outages due to rising winter demand, changing fuel mix. Reuters. Cleanview / Axios reporting. (2026, Feb). The AI boom is making natural gas great again (analysis of planned on-site power equipment). Cushman & Wakefield. (2025). Data Center Development Cost Guide 2025. Cushman & Wakefield. Industry market reports on GPU and data center equipment costs (2024–2025), including market surveys and pricing guides.
Picture
Member for
1 year 8 months
Real name
Keith Lee
Bio
Keith Lee is Professor of AI and Finance at the Gordon School of Business, Swiss Institute of Artificial Intelligence (SIAI). His primary research lies in financial mathematics and AI-driven computational science, with a focus on quantitative modeling of complex economic and financial systems. His work integrates machine learning, stochastic modeling, and data-centric methods to study structural transformations in markets and institutions.
In recent years, his research has extended to the economic and fiscal implications of technological change, including the interaction between artificial intelligence, demographic shifts, and public finance sustainability.
He holds a PhD in Mathematical Finance from Boston University, and previously earned an MSc in Finance and Economics from the London School of Economics. He completed his undergraduate studies in Economics at Seoul National University under the Korea Foundation for Advanced Studies scholarship program.
He regularly contributes analytical essays on the broader socioeconomic implications of AI to The Economy Review.
LLM-powered tutoring and the Discreet Reordering of Teaching
Picture
Member for
1 year 7 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Published
Modified
LLM-powered tutoring is already automating routine teaching at scale
The core challenge is redesigning education labor and governance around AI
Without reinvestment in human expertise, automation will widen inequality
Picture classrooms where AI tutors are helping students learn. These aren't just high-tech gadgets; they're changing how teaching works. These AI tutors can quickly answer many student questions, much faster than a teacher could grade a single paper. Since 2023, studies have shown that students using AI tutors improve their skills in practice and analytical reasoning. With AI handling quick answers and explanations, schools can free teachers for more critical tasks, such as understanding each student's needs and creating better lessons. The big question isn't whether AI can teach, but how schools will use experienced teachers once AI takes over some of the routine work. If we don't plan carefully, AI could make education even more unequal and lessen the demand for skilled teachers who can create engaging lessons. AI-powered tutoring is already changing who does the teaching.
Rethinking Teaching
We need to rethink teaching. Instead of seeing it as a single job, we should view it as a team effort. AI tutors can handle simple, repetitive tasks, such as giving examples, answering basic questions, and providing quick feedback. Human teachers can then focus on designing the curriculum, determining each student's needs, and supporting students with social and emotional challenges. Many large educational programs already divide tasks among different roles. So, instead of asking whether AI will replace teachers, we should ask which tasks are better suited to machines and which require human involvement.
Two important considerations are teacher pay and the rate at which AI is being adopted. Teachers in many developed countries don't earn as much as other professionals with similar levels of education. A Forbes report notes that, while AI tools have been increasingly adopted in schools between 2024 and 2025, many teachers feel unprepared: 76% of teachers in the UK and 69% in the US report receiving little to no formal AI training from their schools. This means that the choices we make now will shape how students learn for years to come.
Figure 1: LLM-powered tutoring shifts human effort away from repetition toward design and intervention, changing teaching from delivery to system stewardship.
Changing Incentives
Thinking about teaching in this new way changes how everyone in a school system acts. If administrators can use AI to provide basic instruction, they should reduce the number of human teachers. This is more likely to happen if teachers are paid poorly and there isn't enough oversight. We've seen schools use pre-made lesson plans when money is tight. AI is just a faster and cheaper way to do the same thing.
But if we see teaching as a team effort, we can see where human teachers are most valuable: creating lessons and assisting students. Expert teachers should focus on designing the AI tutoring system, choosing the best materials, and helping students who are struggling. These tasks require more skill and have a bigger impact than simply following a script. Teachers who do these tasks should be paid more and get more support. If we don't reward these roles, AI will create a system in which some teachers are highly skilled, and others are not, widening the gap between rich and poor schools.
In places where school districts already decide on the curriculum, it will be easier to use AI because everyone can share and check the same materials. In the classroom, teachers can spend more time mentoring students, giving feedback, and supporting their emotional needs. These are things that machines can't do well. For those in charge of education, this means changing how we license and evaluate teachers to recognize the value of lesson design and mentoring. Sharing knowledge and materials lowers the cost of maintaining high-quality education across all schools. It also enables hiring smaller, highly skilled teams to manage the AI tutoring system.
What the Evidence Shows
The evidence from 2023 to 2025 shows both the benefits and drawbacks of AI tutoring. Studies have found that AI tutors can improve practice, understanding, and time spent on learning when used with an appropriate curriculum. A 2025 study in Nature found that an AI tutor outperformed traditional active learning in the classroom, particularly for practice-based tasks. Reviews of intelligent tutoring systems show mixed results overall, but they are more positive when the AI aligns well with the curriculum, provides clear feedback, and offers support. This is why elementary and high schools have adopted AI tutoring more quickly than colleges: their curricula are often more structured, making it easier to evaluate the AI's performance.
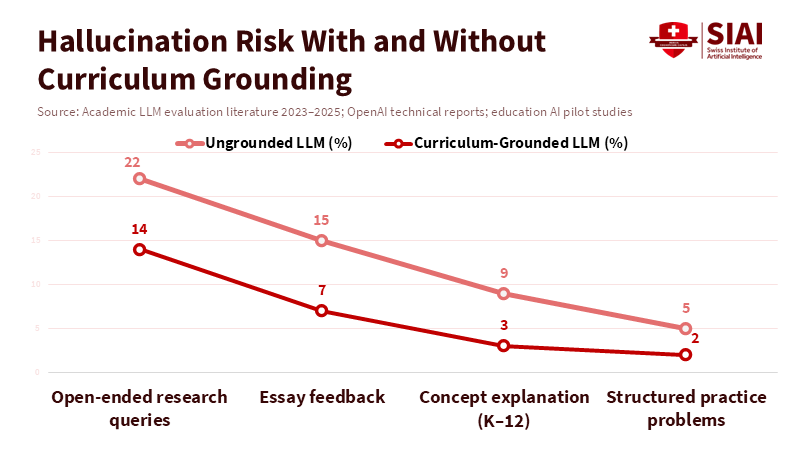
Figure 2: Curriculum grounding and task structure reduce hallucination risk by more than half across most educational tasks.
There are two essential things to keep in mind. First, AI tutoring can work well if schools invest in ensuring it aligns with the curriculum. This means creating shared materials, practice questions, and regular checks to ensure the AI helps students meet learning goals. Second, the best results happen when AI tutors work with human teachers. Humans set the goals, track progress, and step in when needed. This raises a question: if this mixed approach is most effective, how should we pay and promote teachers who contribute to it? If we don't address this, the blended approach could become a justification for cost cuts. AI would take over routine work, leaving the remaining human teachers underpaid and unsupported. We need to invest in both technology and people, not treat them as substitutes for each other.
The benefits of AI tutoring vary by subject and grade level. Subjects such as mathematics and tasks involving repetition show greater improvement than subjects such as writing or history. This doesn't mean AI can't help with writing or historical thinking. Still, it requires clear guidelines, scoring rubrics, and human review to ensure the feedback is valuable rather than merely superficial. We should focus on using AI in areas where it aligns more easily with the curriculum, while also testing it in other areas under careful human oversight.
The Risks of AI Tutors
One of the most significant risks of AI tutors is that they can make mistakes. AI can provide answers that appear correct but are actually incorrect. Research from 2020 to 2025 has examined these errors, their causes, and ways to address them. But there's no single solution that eliminates the problem. The risk of errors depends on the situation. AI is less likely to make mistakes in organized tasks with reliable sources than in open-ended research questions. However, even a small number of confident errors can damage trust, lead to incorrect learning, and compromise data analysis. Schools need to plan for errors as a regular part of AI use.
To reduce errors, we need to use several safeguards:
Grounding: Make sure the AI uses only approved, up-to-date sources.
Human escalation: Send uncertain or essential questions to trained staff.
Transparent audit trails: Keep records of every answer, linking it to the curriculum and source.
Changing the way we prompt the AI and using strategies to improve its information retrieval can reduce errors. But this requires ongoing work: maintaining prompt libraries, checking information sources, and updating knowledge bases. This means we need fewer routine instructors and more people who can design curricula, create prompts, and monitor the AI's performance. A small, skilled team can keep the AI tutoring system accurate for many tasks, as long as they have the authority and funding to fix problems when they arise.
For example, if an AI tutor invents a formula or makes a false historical claim, it can lead a student down the wrong path, which is hard to correct. Once trust is lost in a classroom, it's hard to regain, as parents and administrators expect accountability. That's why it's essential to have error transparency, clear ways to correct mistakes, and a system for sending uncertain outputs to humans. These requirements change how schools should buy AI systems. They should choose modular, auditable systems with shared knowledge repositories rather than systems that are difficult to understand and trace.
The Future of Teaching
The way our economy works explains why AI adoption will speed up. According to a memo from Commissioner Anastasios Kamoutsas, some teachers have not received pay increases because of what he described as "unnecessary and prolonged contract negotiations" by unions. Automation enables the maintenance of basic instruction while reducing costs. But this has consequences. According to Keith Lee, while AI can help teachers save time on tasks like creating rubrics or outlining lessons, these productivity gains will only benefit students and teachers if schools change their processes to ensure the regained time leads to better feedback, stronger curricula, and fairer outcomes instead of being diverted elsewhere. Linking automation to deliberate reinvestment is essential to make sure these benefits serve the public good.
A practical plan rests on three things. First, set standards for how AI should be used. These standards should include clear learning targets, permissible error rates, human escalation procedures, and public reporting of outcomes. Second, fund regional centers that can provide vetted knowledge bases and compliance services. This will help smaller districts access high-quality AI systems without taking on too much risk. These centers can also provide shared evaluation and benchmarks for comparing results across districts. Third, change teachers' career paths. Create and appropriately compensate roles for curriculum design, system management, and student support. There should be clear paths for teachers to move from the classroom into roles such as curriculum engineer or intervention specialist, with corresponding pay increases. Policymakers should test reinvestment clauses linked to AI pilots, so that savings are used to support people and programs.
There are lessons from the past. When standardized testing and pre-packaged curricula became common, teaching became more scripted and less creative. Automation could make this worse unless we link productivity gains to reinvestment in professional roles. To prevent this, districts should report how they allocate savings from automation and monitor the impact on disadvantaged students. This kind of conditional funding, along with transparency, will be controversial, but it's necessary if automation is to expand opportunity rather than limit it.
Remember, AI tutoring is already automating a lot of routine instructional work. This isn't necessarily a bad thing. It only becomes bad if schools use it to cut investments in human expertise and social support. If we instead design a system where AI handles routine tasks, expert humans handle design, and savings are reinvested in higher-skill roles and support, we can expand access and advance learning. The choice is ours to make.
Fund the teams that manage and oversee the AI tutoring systems, require open audits of error rates, and link automation gains to teacher career upgrades. Policymakers should set clear timelines for pilots, require open reporting of error rates, reinvest savings into staff development, and support regional hubs that pool expertise. Education leaders must require both technical audits and human-centered data that captures mentorship, trust, and access. Together, these measures will determine whether AI tutoring serves as a tool to expand opportunities or deepen existing divides.
The views expressed in this article are those of the author(s) and do not necessarily reflect the official position of the Swiss Institute of Artificial Intelligence (SIAI) or its affiliates.
References
Microsoft. (2025). AI in Education: A Microsoft Special Report. Nature. (2025). Kestin, G., Miller, K., Klales, A., Milbourne, T., & Ponti, G. (2025). AI tutoring outperforms in-class active learning: an RCT introducing a novel research-based design in an authentic educational setting. Scientific Reports. OECD. (2023). What do OECD data on teachers’ salaries tell us? (Education Indicators in Focus). OECD. (2025). AI adoption in the education system. (Report). OpenAI. (2025). Why language models hallucinate. Research blog. Springer / academic review. (2025). The rise of hallucination in large language models: systematic review and mitigation strategies. U.S. Department of Education, Office of Educational Technology. (2023). Artificial Intelligence and the Future of Teaching and Learning: Insights and Recommendations.
Picture
Member for
1 year 7 months
Real name
Ethan McGowan
Bio
Professor of AI/Finance, Gordon School of Business, Swiss Institute of Artificial Intelligence
Ethan McGowan is a Professor of AI/Finance and Legal Analytics at the Gordon School of Business, SIAI. Originally from the United Kingdom, he works at the frontier of AI applications in financial regulation and institutional strategy, advising on governance and legal frameworks for next-generation investment vehicles. McGowan plays a key role in SIAI’s expansion into global finance hubs, including oversight of the institute’s initiatives in the Middle East and its emerging hedge fund operations.
Japan’s growth problem is not a lack of effort, but weak output per hour
Extending work hours raises costs without fixing productivity or wages
Policy should shift from time worked to skills, management, and productivity gains
Payment stablecoins now hold a quiet form of monetary privilege
It comes from settlement design, not true money creation
Until issuers are regulated as banks, the system remains distorted
The market value of a degree now depends more on skills than prestige
Employers pay for verified, job-ready learning
Education policy must validate outcomes, not labels