Why was ‘Tensorflow’ a revolution, and why are we so desperate to faster AI chips?
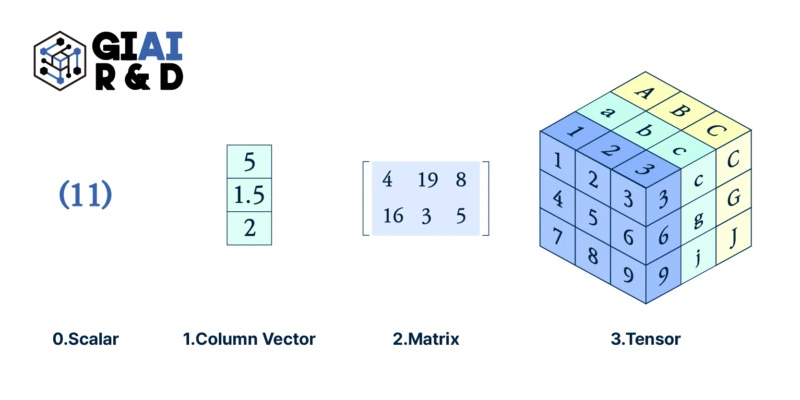
Transition from column to matrix, matrix to tensor as a baseline of data feeding changed the scope of data science,
but faster results in 'better', only when we apply the tool to the right place, with right approach.
Back in early 2000s, when I first learned Matlab to solve basic regression problems, I was told Matlab is the better programming tool because it runs data by ‘Matrix’. Instead of other software packages that feed data to computer system by ‘column’, Matlab loads data with larger chunk at once, which accelerates processing speed by O(nxk) to O(n). More precisely, given how the RAM is fed by the softwares, it was essentially O(k) to O(1).
Together with a couple of other features, such as quick conversion of Matlab code to C code, Matlab earned huge popularity. A single copy was well over US$10,000, but companies with deep R&D and universities with significant STEM research facilities all jumped to Matlab. While it seemed there were no other competitors, there was a rising free alternative, called R, that had packages handling data just like Matlab. R also created its own data handler, which worked faster than Matlab for loop calculation. What I often call R-style (like Gangnam style), replaced loop calculations from feeding column to matrix type single process.
R, now called Posit, became my main software tool for research, until I found it’s failure to handling imaginary numbers. I had trouble reconciliating R’s outcome with my hand-driven solution and Matlab’s. Later, I ended up with Mathematica, but given the price tag attached to Mathematica, I still relied on R for communicating with research colleagues. Even after prevailing Python data packages, upto Tensorflow and PyTorch, I did not really bother to code in Python. Tensorflow was (and is) also available on R, and there was not that much speed improvement in Python. If I wanted faster calculation for multi-dimensional tasks that require Tensorflow, I coded the work in Matlab, and transformed to C. There initially was a little bug, but the Matlab’s price tag did worth the money.
A few years back, I found Julia, which has similar grammar with R and Python, but with C-like speed in calculations with support for numerous Python packages. Though I am not an expert, but I feel more conversant with Julia than I do to Python.
When I pull this story, I get questions like wy I traveled around multiple software tools? Have my math models become far more evolved that I required other tools? In fact, my math models are usually simple. At least to me. Then, why from Matlab to R, Mathematica, Python, and Julia?
Since I only had programming experience from Q-Basic, before Matlab, I really did not appreciate the speed enhancement by ‘Matrix’-based calculations. But when I switched to R, for loops, I almost cried. It almost felt like Santa’s Christmas package had a console gamer that can play games that I have dreamed of for years. I was able to solve numerous problems that I had not been able to, and the way I code solution also got affected.
The same transition affected me when I first came across ‘Tensorflow’. I am not a computer scientist, so I do not touch image, text, or any other low-noise data, so the introduction of tensorflow by computer guys failed to earn my initial attention. However, on my way back, I came to think of the transition from Matlab to R, and similar challenges that I had had trouble with. There were a number of 3D data sets that I had to re-array them with matrix. There were infinitely many data sets in shape of panel data and multi-sourced time series.
When in search for right stat library that can help solving my math problems in simple functions, R usually was not my first choice. It was mathematica, and it still is, but since the introduction of tensorflow, I always think of how to leverage 3D data structure to minimize my coding work.
Once successful, it not only helps me to save time in coding, but it tremendously changes my ‘waiting’ time. During my PhD, for one night, the night before supposed meeting with my advisor, I found a small but super mega important error in my calculation. I was able to re-derive closed solutions, but I was absolutely sure that my laptop won’t give me a full-set simulation by the next morning. I cheated with the simulation and created a fake graph. My advisor was a very nice guy to pinpoint something was wrong with my simluation within a few seconds. I confessed. I was too in a hurry, but I should’ve skipped that week’s meeting. I remember it took me years to earn his confidence. With faster machine tools that are available these days, I don’t think I should fake my simulation. I just need my brain to process faster, more accurately, and more honestly.
After the introduction of H100, many researchers in LLM feel less burden on handling massive size data. As AI chips getting faster, the size of data that we can handle at the given amount of time will be increasing with exponential capacity. It will certainly eliminate cases like my untruthful communication with the advisor, but I always ask myself, “Where do I need hundreds of H100?”
Though I do appreicate the benefits of faster computer processing and I do admit that the benefits of cheaper computational cost that opens opportunities that have not been explored, it still needs to answer ‘where’ and ‘why’ I need that.