High accuracy with ‘Yes/No’ isn’t always the best model
With high variance, 0/1 hardly yields a decent model, let alone with new set of data
What is known as 'interpretable' AI is no more than basic statistics
'AI'='Advanced'='Perfect' is nothing more than mis-perception, if not myth
5 years ago. Just not long after an introduction of simple ‘artificial intelligence’ learning material that uses data related to residential areas in the Boston area to calculate the price of a house or monthly rent using information such as room size and number of rooms was spread through social media. An institution that claims they do hard study in AI together with all kinds of backgrounds in data engineering and data analysis requested me to give a speeach about online targetting ad model with data science.
I was shocked for a moment to learn that such a low-level presentation meeting was being sponsored by a large, well-known company. I saw a SNS post saying that the data was put into various ‘artificial intelligence’ models, and that the model that fit the best was the ‘deep learning’ model. That guy showed it off and boasted that they had a group of people with great skills.
I was shocked for a moment to learn that such a low-level presentation meeting was being sponsored by a large, well-known company. I saw a SNS post saying that the data was put into various ‘artificial intelligence’ models, and that the model that fit the best was the ‘deep learning’ model. He showed them off and boasted that they had a group of people with great skills.
Back then and now, studies such as putting the models introduced in textbooks into the various calculation libraries provided by Python and finding out which calculation works best are treated as a simple code-run preview task rather than research. I was shocked, but since then, I have seen similar types of papers not only among engineering researchers, but also from medical researchers, and even from researchers in mass communication and sociology. This is one of the things that shows how shockingly the most degree programs in data science are run.

Just because it fits ‘yes/no’ data well doesn’t necessarily mean it’s a good model
The calculation task of matching dichotomous result values classified as ‘yes/no’ or ‘0/1’ is robustness verification that determines whether the model can repeatedly fit well with similar data rather than the accuracy of the model on the given data. ) must be carried out.
In the field of machine learning, robustness verification as above is performed by separating ‘test data’ from ‘training data’. Although this is not a wrong method, it has the limitation that it is limited to cases where the similarity of the data is continuously repeated. This is a calculation method.
To give an example to make it easier to understand, stock price data is known as data that typically loses similarity. Among the models created by extracting the past year’s worth of data and using the data from 1 to 1 months as training data, it is applied to the data from 6 to 7 months. Even if you find the best-fitting model, it is very difficult to obtain the same level of accuracy in the following year or in past data. As a joke among professional researchers, the evaluation of a meaningless calculation is expressed in the following way: “It would be natural to be 12% correct, but it would make sense if the same level of accuracy was 0%.” However, in cases where the similarity is not repeated continuously, ‘ It will help you understand how meaningless a calculation it is to find a model that fits ‘0/0’ well.
Information commonly used as an indicator of data similarity is periodicity, which is used in the analysis of frequency data, etc., and when expressed in high school level mathematics, there are functions such as ‘Sine’ and ‘Cosine’. Unless the data repeats itself periodically in a similar way, you should not expect that you will be able to do it well with new external data just because you are good at distinguishing ‘0/1’ in this verification data.
Such low-repeatability data is called ‘high noise data’ in the field of data science, and instead of using models such as deep learning, known as ‘artificial intelligence’, even at the cost of enormous computer calculation costs, general A linear regression model is used to explain relationships between data. In particular, if the distribution structure of the data is a distribution well known to researchers, such as normal distribution, Poisson distribution, beta distribution, etc., using a linear regression or similar formula-based model can achieve high accuracy without paying computational costs. This is knowledge that has been accepted as common sense in the statistical community since the 1930s, when the concept of regression analysis was established.
Be aware of different appropriate calculation methods for high- and low-variance data
The reason that many engineering researchers in Korea do not know this and mistakenly believe that they can obtain better conclusions by using an ‘advanced’ calculation method called ‘deep learning’ is that the data used in the engineering field is ‘low-dispersion data’ in the form of frequency. This is because, during the degree course, you do not learn how to handle highly distributed data.
In addition, as machine learning models are specialized models for identifying non-linear structures that repeatedly appear in low-variance data, the challenge of generalization beyond ‘0/1’ accuracy is eliminated. For example, among the calculation methods that appear in machine learning textbooks, none of the calculation methods except ‘logistic regression’ can use the data distribution-based analysis method used for model verification in the statistical community. This is because the variance of the model cannot be calculated in the first place. Academic circles express this as saying that ‘1st moment’ models cannot be used for ‘1nd moment’-based verification. Variance and covariance are commonly known types of ‘second moment’.
Another big problem that arises from such ‘first moment’-based calculations is that a reasonable explanation cannot be given for the correlation between each variable.
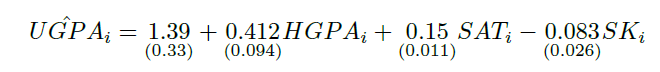
Let’s take an example.
The above equation is a simple regression equation created to determine how much college GPA (UGPA) is influenced by high school GPA (HGPA), CSAT scores (SAT), and attendance (SK). Putting aside the problems between each variable and assuming that the above equation was calculated reasonably, it can be confirmed that high school GPA influences as much as 41.2% in determining undergraduate GPA, while CSAT scores only influence 15%. there is.
As a result, machine learning calculations based on ‘first moment’ only focus on how well college grades are matched, and additional model transformation is required to check how much influence each variable has. There are times when you have to give up completely. Even verification of statistics based on ‘second moment’, which can be performed to verify the accuracy of the calculation, is impossible. If you follow the statistical verification based on the Student-t distribution learned in high school, you can see that 1% and 2% in the above model are both reasonable figures, but machine learning series calculations use similar statistics. Verification is impossible.
Why the expression ‘interpretable artificial intelligence’ appears
You may have seen the expression ‘Interpretable artificial intelligence’ appearing frequently in the media, bookstores, etc. The problem that arises because machine learning models have the blind spot of transmitting only the ‘first moment’ value is that interpretation is impossible. As seen in the above example, it cannot provide reliable answers at the level of existing statistical methodologies to questions such as how deep the relationship between variables is, whether the value of the relationship can be trusted, and whether it appears similarly in new data. Because.
If we go back to a data group supported by a large company that created a website with the title ‘How much Boston house price data have you used?’, if there was even one person among them who knew that models based on machine learning series had the above problems, Could they have confidently said on social media that they have used several models and found ‘deep learning’ to be the best among them, and sent me an email saying they are experts because they can run the code to that extent?
As we all know, real estate prices are greatly influenced by government policies, as well as the surrounding educational environment and transportation accessibility. Not only is this the case in Korea, but based on my experience living abroad, the situation is not much different in major overseas cities. If I were to be specific, the brand of the apartment seems to be a more influential variable due to its Korean characteristics.
The size of the house, the number of rooms, etc. are meaningful only when other conditions are the same, and other important variables include whether the windows face south, southeast, southwest, plate type, etc. Data on house prices in Boston that were circulating on the Internet at the time were All such core data had disappeared, and it was simply example data that could be used to check whether the code was running well.
If you use artificial intelligence, wouldn’t accuracy be 99% or 100% possible?
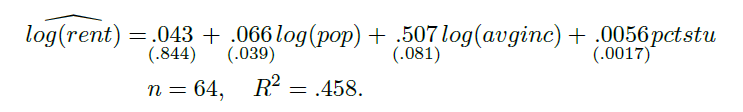
Another expression I often heard was, “Even if you can’t improve accuracy with statistics, isn’t it possible to achieve 99% or 100% accuracy using artificial intelligence?” Perhaps the ‘artificial intelligence’ that the questioner meant at the time was general. It would have been known as ‘deep learning’ or ‘neural network’ models of the same series.
First of all, the model explanatory power of the simple regression analysis above is 45.8%. You can check that the R-squared value above is .458. The question would have been whether this model could be raised to 99% or 100% by using other ‘complex’ and ‘artificial intelligence’ models. The above data is a calculation to determine how much the change in monthly rent in the area near the school is related to population change, change in income per household, and change in the proportion of students. As explained above, knowing that the price of real estate is affected by numerous variables, including government policy, education, and transportation, it is understood that the only surefire way to fit the model with 100% accuracy is to match the monthly rent by monthly rent. It will be. Isn’t finding X by inserting X something that anyone can do?
Other than that, I think there is no need for further explanation as it is common sense that it is impossible to perfectly match the numerous variables that affect monthly rent decisions in a simple way. The area where 99% or 100% accuracy can even be attempted is not social science data, but data that repeatedly produces standardized results in the laboratory, or, to use the expression used above, ‘low-variance data’. Typical examples are language data that requires writing sentences that match the grammar, image data that excludes bizarre pictures, and games like Go that require strategies based on rules. Although it is natural that it is impossible to match 99% or 100% of the highly distributed data we encounter in daily life, at one time the basic requirements for all artificial intelligence projects commissioned by the government were ‘must use deep learning’ and ‘must have 100% accuracy.’ It was to show ‘.
Returning to the above equation, we can see that the student population growth rate and the overall population growth rate do not have a significant impact on the monthly rent increase rate, while the income growth rate has a very large impact of up to 50% on the monthly rent increase. In addition, when the overall population growth rate is verified by statistics based on the Student-t distribution learned in high school, the statistic is only about 1.65, so the hypothesis that it is not different from 0 cannot be rejected, so it is a statistically insignificant variable. The conclusion is: Next, the student population growth rate is different from 0, so it can be determined that it is a significant value, but it can be confirmed that it actually has a very small effect of 0.56% on the monthly rent growth rate.
The above computational interpretation is, in principle, impossible using ‘artificial intelligence’ calculations known as ‘deep learning’, and a similar analysis requires enormous computational costs and advanced data science research methods. Paying such a large computational cost does not mean that the explanatory power, which was only 45.8%, can be greatly increased. Since the data has already been changed to logarithmic values and only focuses on the rate of change, the non-linear relationship in the data is internalized in a simple regression model. It is done.
Due to a misunderstanding of the model known as ‘deep learning’, industries made a shameful mistake of paying a very high learning cost and pouring manpower and resources into the wrong research. Based on the simple regression analysis-based example above, ‘ We hope to recognize the limitations of the computational method known as ‘artificial intelligence’ and not make the same mistakes as researchers over the past six years.




