Class 1. Regression problems

Many people think machine learning is some sort of magic wand. If a scholar claims that a task is mathematically impossible, people start asking if machine learning can make an alternative. The truth is, as discussed from all pre-requisite courses, machine learning is nothing more than a computer version of statistics, which is a discipline that heavily relies on mathematics.
Once you step aside from basic statistical concepts, such as mean, variance, co-variance, and normal distribution, all statistical properties are built upon mathematical language. In fact, unless it is purely based on experiments, mathematics is a language of science. Statistics as a science is no exception. And, machine learning is a computational approach of statistics, which we call computational statistics.
Throughout this course, it is introduced that all machine learning topics are deeply based on statistical properties. Although the SIAI’s teaching relies less on math more on practical applications, it is still required to learn key mathematical backgrounds, if to use machine learning properly. If you skip this part, then you will be one of the amateurs arguing machine learning (or any computational statistical sub-disciplines) as a magic.
When do you need machine learning?
To answer why machine learning become suddenly popular, you first have to understand what it really does. Machine learning helps us to find a non-parametric function that fits to data. Non-parametric means that you do not have a specific functional shape, like $y=a \cdot x^2 + b \cdot x + c$. Once you step away from linear representation of the function, there can be infinite number of possibilities to represent a function. $y=f(x)$ can be a combination of exponential, log, or any other form you want. As long as it fits to data, why care so much?
Back then, fitting to data was only the first agenda. Because the data in your hand is only a sample of the giant population. For example, if a guy claim that he can perfectly match stock price movements for the last 3 years for a specific stock. Then, amateurs are going to ask him if
- The horizon can be expanded not only to the distant past, but also for the future
- Other stock prices can be replicated
If the stock price returns are randome, a fit for sample data cannot be replicated to other sets of data, unless miracle occurs. In mathematical terms, we call it a probability $\frac{1}{\infty}$ event. If you have done some stochastic calculus, it can be said that the probability converges to 0 almost surely (a.s.).
Here, the second agenda arises, which is minimizing model variance for generality of the model. In statistics, it is often done by Z-test, t-test, $\chi^2$-test, and F-test. Although the statistical tests based on (co-)variance (or 2nd-moments, in more scientific terms) is not universal solution to claim generality of the model, if conditions fit, we can argue that it is fairly good enough. (Conditions that can be satisfied if you data follows normal distribution, for example).
Unfortunately, machine learning hardly addresses the second one. Why? Because machine learning relies on further assumptions. The 2nd-moment should be irrelevant for it to work. What are the data sets that overrules the 2nd-moment tests? Data that does not follow random distribution, thus does not have variance. Data that follows rules.
In short, machine learning is not for random data. The quest to find an ultra complicated function should be rewarding, and the probability is guaranteed if such funcational events are highly frequent. Examples of such events are like language. You do not speak random gibberish for daily conversation. (Assuming that you do not read this text in a psychiatric hospital.) As long as your language has a grammar and a dictionary for vacabulary, that means there is a rule and it is repeated, thus highly frequent.
Then, how come machine learning become so popular?
Out of many other reasons that machine learning suddenly becomes popular, one thing that can be told is that we now have a plethora of highly frequent data with certain rules. You do not need bigtech companies to build a peta-byte database of text, image, and any other contents with rules. Finding a linear functional form, like $y=a \cdot x^2 + b \cdot x + c$, for such data is mostly next to impossible. Then, what is an ideal alternative? Is there any alternative? Remember that machine learning helps us to fit such a complicated function.
The first page of this lecture note then starts with an example of traditional statistics that fails to find such a function. In the above screenshot, on the left, factor analysis cannot help us to differentiate data sets of 0~9. There are 10 types of data, but factor analysis was not able to find key characteristics of each type. It is because the combination of characters are complicated, and a simple function cannot find the decent fit. For example, number 3 and 9 have the similar shape on the upper right part and bottom center part. Number 5 and 9 have the similar bottom right part. Number 0 and 9 also share the upper right part and the bottom right part. You need more than a simple function to match all combinations. This is where multi-layer factor analysis (called Deep Neural Network) can help us.
Throughout the course, just like above, each machine learning topic will be introduced in a way to overcome given trouble that traditional statistics may not solve easily. Note that it does not mean that machine learning is superior to traditional statistics. It just helps us to find a highly non-linear function, if your computer can do the calculation. Possibilities are still limited and often explained in mathematical format. In fact, all machine learning jargons have more scientific alternative, like multi-layer factor analysis to Deep Neural Network, which also means there is a scientific back-up needed to fully understand what it really does. Again, computational methods are not magic. If you want to wield the magic wand properly, you have to learn the language of the ‘magic’, which is ‘mathematics’.
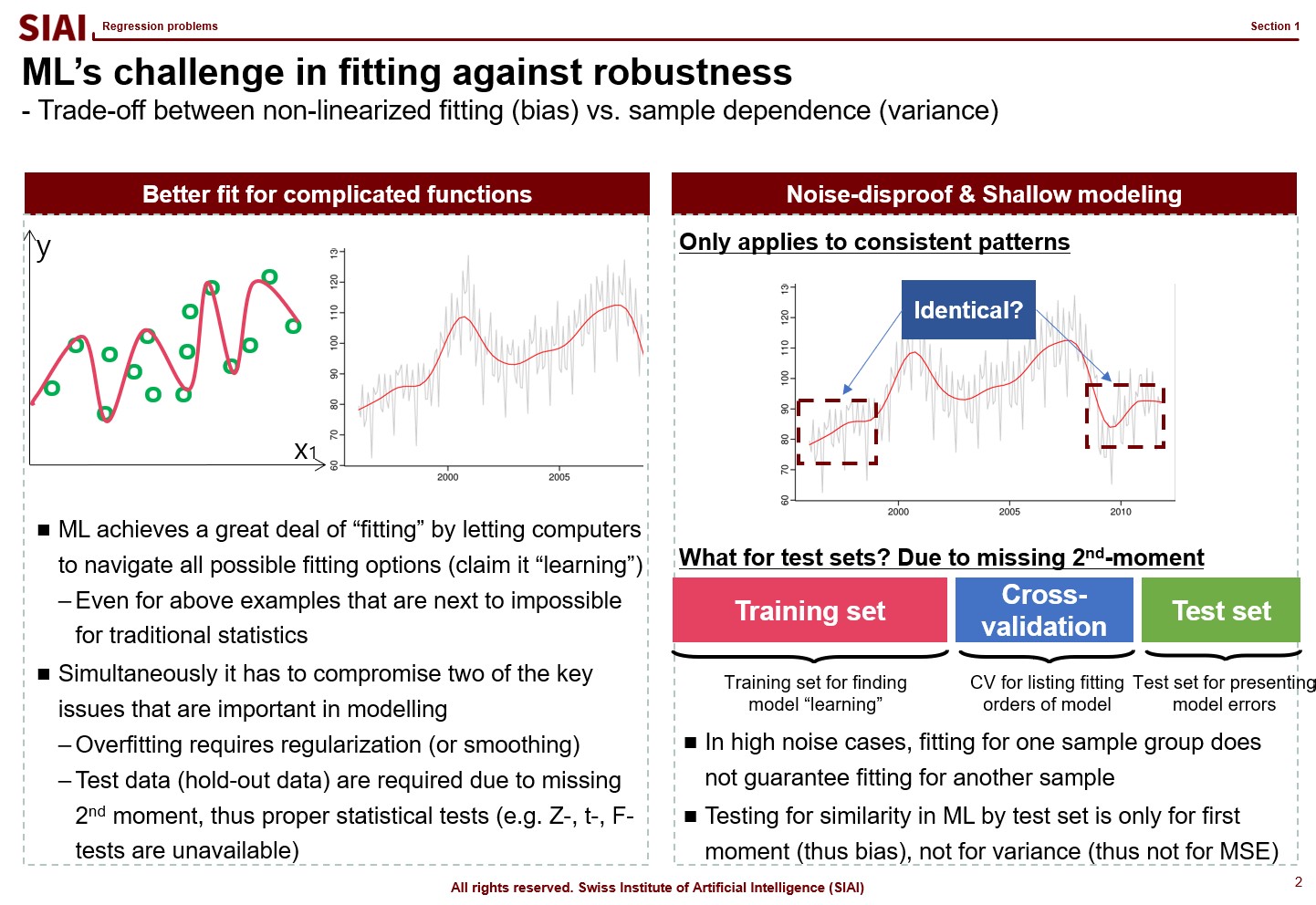
Most simpliest possible machine learning is to find a non-linear fit of a data set. As you have more and more data points, the function to match all points is necessarily going to have more ups and downs, unless you have a data set fits to a linear function. Thus, if you have more data, it is likely that you are going to suffer from less fit with abundant error or more fit with complication in function.
As discussed above, machine learning approaches are to find a fit, or 1st-moment (mean, average, min, max…), which assumes that data set is repeated in out of sample. As long as it fits to data in hand, machine learning researchers assume that it fits to all other data in the same category. (This is why a lot of engineers, after the 1st lecture of machine learning, claim that they can find a fit to stock price movements and make money in the market. They don’t understand that financial markets are full of randomness.)

In statistics, the simplest form of regression is called ordinary least square (OLS). In machine learning, the OLS solution is called ‘Normal equation’ method. Why are they end up with the same form of the solution?
This happens only when the OLS is the most optimal fit to given data set, which is coined as ‘Best Linear Unbiased Estimator (BLUE)’ in statistics, where one condition for OLS to be BLUE is the target variable follows normal distribution. To be precise, statistians say that $y$ is normally distributed conditional on $X$, or $y|X \backsim N(\beta \cdot X, \sigma^2)$. Given your explanatory variables, if your target variable follows normal distribution, your machine learning model will give you exactly the same solution as OLS. In other words, if you have normally distributed random data, then you don’t have to go for machine learning models to find the optimal fit. You need machine learning models when your target variable is not normally distributed, and it is not random.
Just to note that if your data follows a known distribution, like Poisson, Laplace, Binomial…, there is a closed-form BLUE solution, so don’t waste your computational cost for machine learning. It’s like high school factorization. If you know the form, you have the solution right away. If not, you have to rely on a calculator. For questions like $x^2 – 2x +1 =0$ is simple, but complicated questions may require enourmous amount of computational cost. You being smart is the key cost saving for your company.
In real world, hardly any data (except natural language and image) have non-distributional approximation. Most data have proxy distribution, which gives near optimal solution with known statistics. This is why elementary statistics only teach binomial (0/1) and Gaussian ($N(\mu, \sigma^2)$)distribution cases. Remember, machine learning is a class of non-parametric computational approach. It is to find a fit that matches to unknown function. And, it does not give us variance for testing. The entire class of machine learning models assume that there are strong patterns in the data set, otherwise a model without out of sample property is not a model. It is just a waste of computer resource.
Think of an engineer claiming that he can forecast stock price movements based on previous 3 years data. He may have a perfect fit, after running a computational model for years (or a lot of electric power and super expensive graphics card.) We know that stock prices are deeply exposed to random components, which means that his model will not fit for the next 3 years. What would you call the machine learning model? He may claim that he needs more data or more computational power. Financial economists would call them amateurs, if not idiots.

Then, one may wonder, what about data sets that fit better with non-linear model? In statistics, maximum likelihood estimators (MLE) are known as the best unbiased estimator (BUE), as long as the distributional shape is known. And, if the distribution is normal, as discussed in earlier slides, it matches exactly the same as OLS. (Note that variance is slightly different due to loss of degrees of freedom, but $N-1$ and $N$ are practically the same, if $N \rightarrow \infty$.)
In general, if the model is limited to linear class models, simple OLS (or GLS, at best) is the optimal approach. If the distributional shape is known, MLE i the best option. If your data does not have known distribution, but needs to find a definitive non-linear pattern, that’s when you need to run machine learning algorithms.
Many amateurs blatantly run machine learning models and claim that they found the most fitted solution, like accuracy rate is 99.99%. As discussed, with machine learning, you cannot do any out of sample test. You might be 99.99% accurate for today’s data, but you cannot guarantee that tomorrow. Borrowing the concept of computational efficiency from COM501:Scientific Programming, machine learning models are exposed to larger MSE and more computational cost. Therefore, for data sets OLS and MLE are the best fit, all machine learning models are inferior.
Above logic is the centerpiece of COM502: Machine Learning, and in fact is the single most important point of the entire program at SIAI. Going forward, for every data problem that you have, the first question you have to answer is if you need to rely on machine learning models. If you stick to it despite random data set closed to Gaussian distribution, you are a disqualified data scientist.
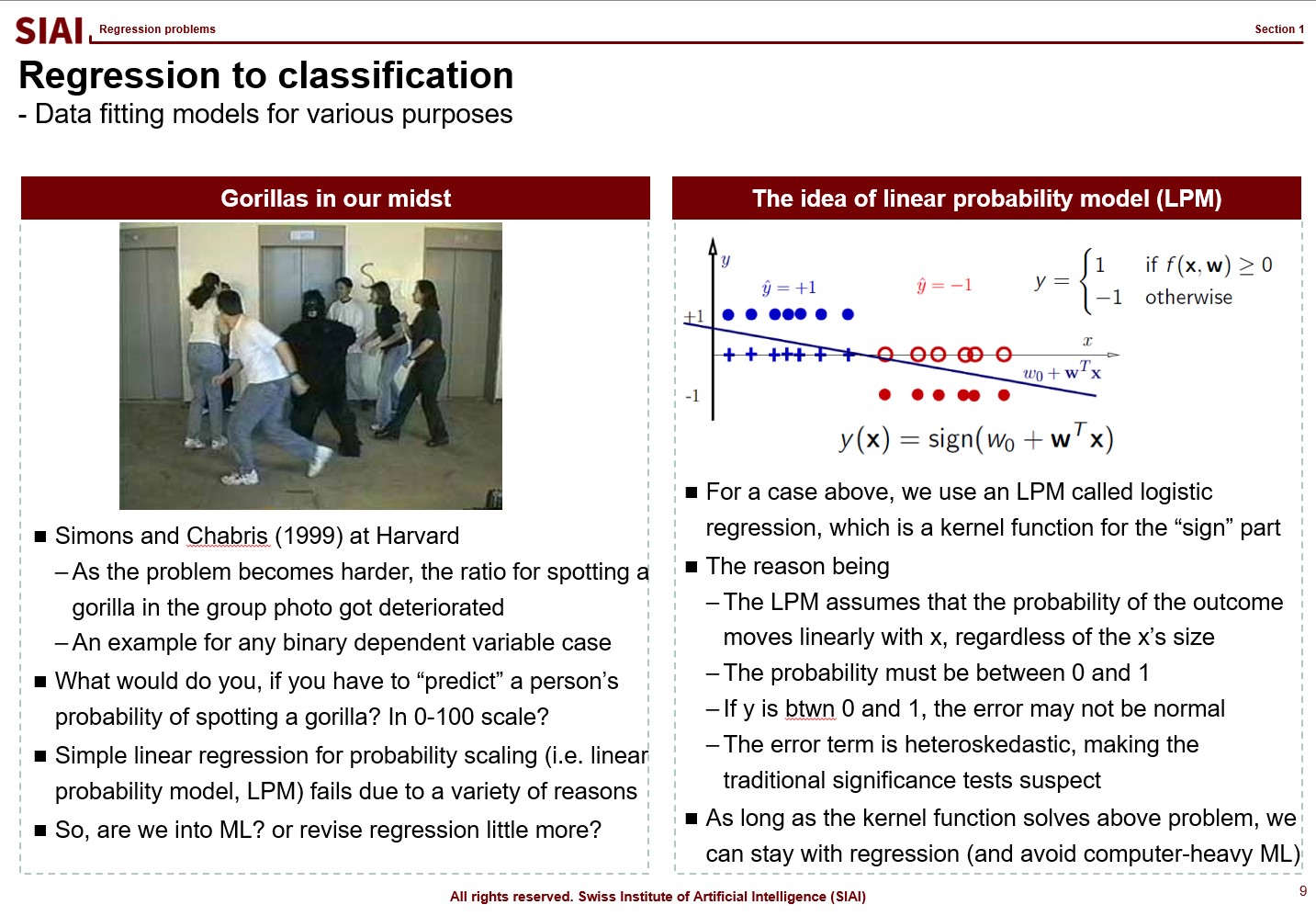
Kernel function for 0/1 or 0~100 scale
What if the outcome that you have to find the fit is no longer a continuous value from 0 to 100, or -$\infty$ to $\infty$? In mathematics, we call this as ‘support’, meaning that your value’s range. in other words, by the mathematical jargon, if your target variable’s support is 0/1 or Yes/No, your strategy might be affected, because you no longer have to match a random variable following normal distribution. We call 0/1 value cases as ‘binomial distribution’, and it requires different approximation strategy.
One that has been widely used is to apply a kernel function, which transforms your value to another support. From your high school math, you should have come across $y=f(x)$, (if not, your trial to learn ML is likely going to be limited to code copying only), a simplest form that tells us that $x$ is transformed to $y$ by function $f$. The function can be anything, as long as it converts $x$ to $y$, without any slag. (Mathematically, we call that $f$ is defined on $x$.)
If the transformation function $f$ maps value $x$ to 0~1, or Yes/No, we can fit Yes/No cases, just like we did with normal distribution.
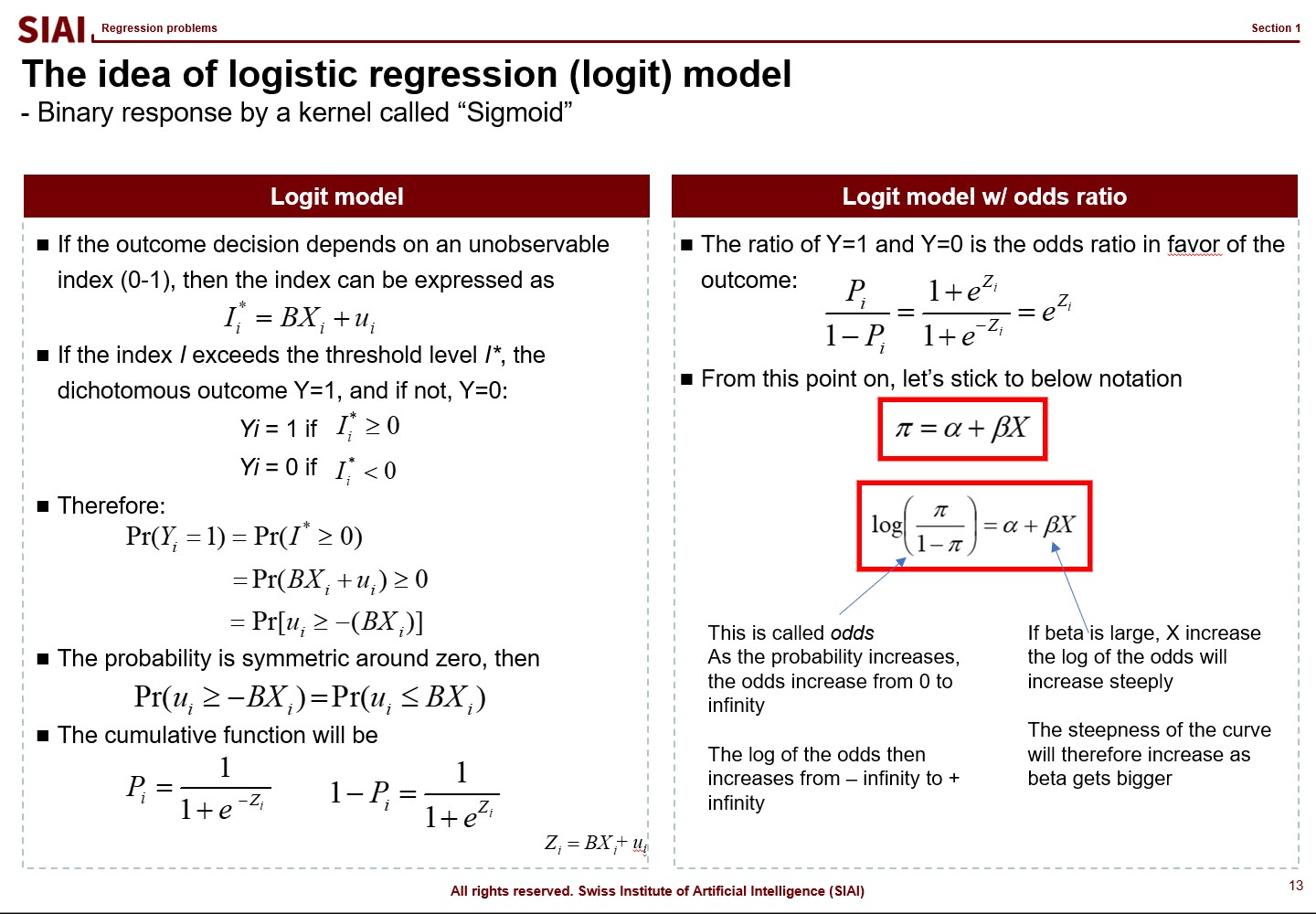
There are two widely adapted transformation $f$, Logit and Probit. As you can see from above lecture note, Logit coverts the $x$ value by odds ratio. Unfortunately, there is no closed form solution to calculate the ratio with hands, so we follow Newton methods, which we learned from COM501: Scientific Programming. The approach relies on the idea that likelihood of the value to be 0 vs. ths same probability to be 1. The ratio can be varying from -$\infty$ to +$\infty$, but the re-scaling put it into 0~1 frame.
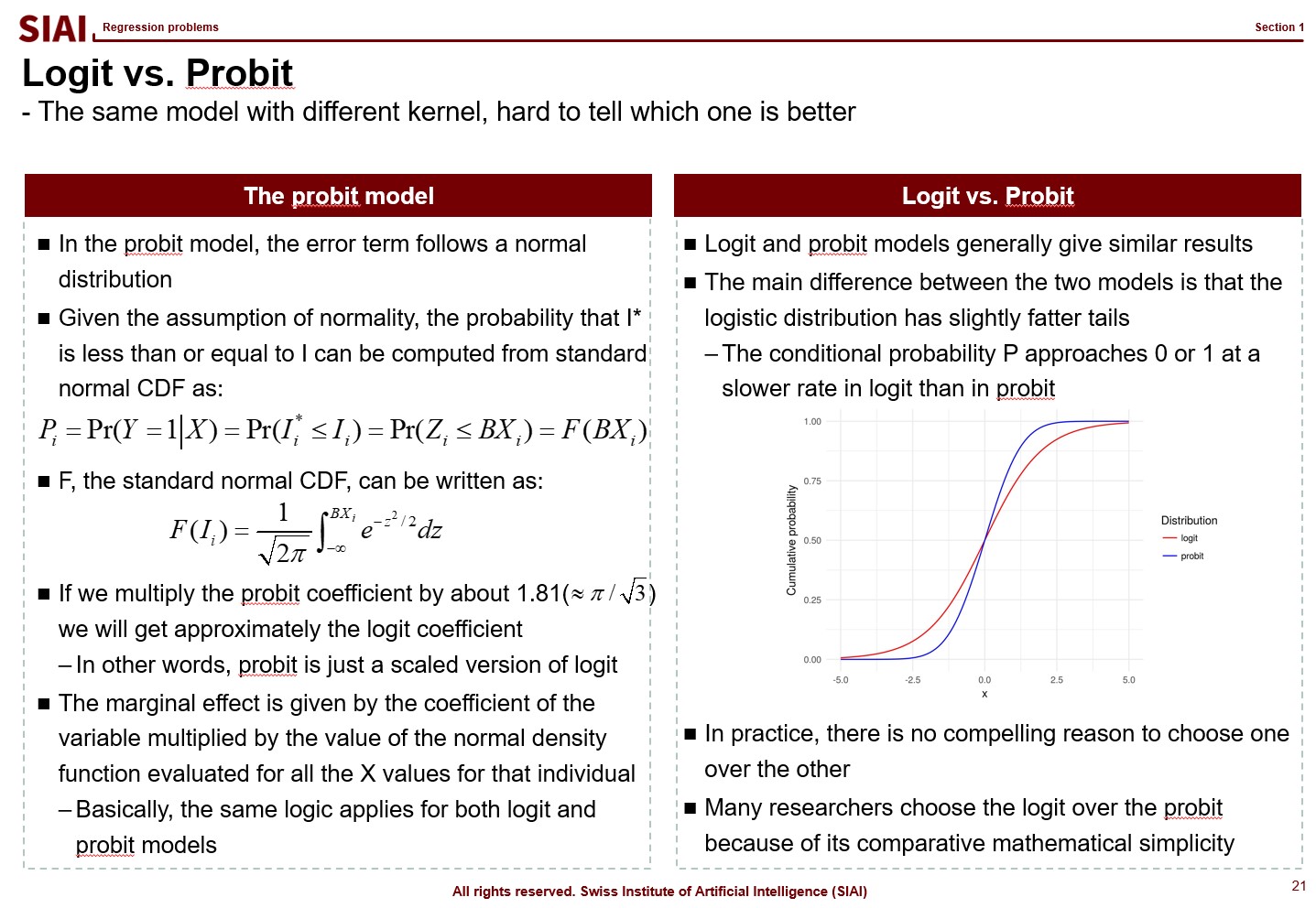
Similarly, Probit transforms the outcome by assuming that it follows normal distribution. There is little to no difference between these two methods, when it comes to the accuracy, if you have large number of independent sample data. In small samples, usually Logit provides smoother value changes than Probit. You had more details of Logit in COM501: Scientific Programming. Check the notes.
